






集群里,主要理解的东西就是一个数据同步的问题,也就是数据一致性问题,主要就是CAP理论,也就是一致性、可用性、网络分区。
一致性:你读取的是最新的写或者是错误
可用性:每一次请求都可以收到一个结果
网络分区:就是可能会有一个网络的故障
在现实中,网络是一定要允许网络故障的存在,所以这个P是一定存在的,所以对这个A、C做一个取舍,比如说我们选择的是一个cp架构,也就是说,我们要保证一致性+网络故障存在。如果要一致性,就牺牲了可用性,也就是说,有两台机器,网络出现问题,如果要保证一致性,那么就不让用户进行操作机器,牺牲机器的可用性。
如果要可用性+网络故障,那么一致性就要被丢失了。
1. Nacos集群的同步协议
AP:可用性+网咯故障的存在 ----->Distro协议
CP:一致性+网络故障的存在 ------> 对于Raft协议 实现的Nacos2.x SofaJRaft
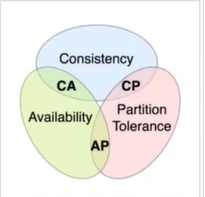
在集群这一块,我们要保证数据的一致性,关于CAP我们如何进行选择,如果你一定允许有网络分区存在的情况下,要么你就选择AP,要么就选择CP,如果没有网络分区的话其实C和A是可以同时满足的。
AP架构主要用于 临时实例的场景,Distro协议,在保证一致性的情况下,将数据转给其它其它节点
CP架构主要用于 持久实例的场景。
2. CP架构下的问题
2.1. 选举主节点
在集群中,如果每一个节点都可以进行处理请求写数据,在并发情况下进行数据同步的时候就会带来复杂性,所以在CP架构模式下都会选择一个主节点。
所以第一个问题时,我们要在集群中选择一个(或者是至少一个)leader节点,将数据统一写在leader上,同时可以在leader上设置一个队列,保证它的一个顺序写。
2.2. 转发
比如nacos server S1成为主节点后,还有S2 ,S3
s2,s3 的数据写操作 通过forward 转发给S1写
2.3. 保证数据一致性
有三种解决方案需要考虑:
(1)保证所有节点写都成功,就会存在网络开销问题,要等待其它节点写入完成
(2)保证节点中大多数节点成功,就算成功。(可以权衡写数据性能和数据一致性的平衡)
(3)集群破溃【leader节点挂掉】的时候,重新选择主节点
2.4. 解决CP架构下问题的理论模型
Paxos、ZAB、Raft等一致性算法都是解决上述问题的理论模型

这些算法解决的时候,节点最好是奇数个,为什么呢, 这涉及到主节点的选举,一般是大于一半的节点选举成功,这个节点才能成为主节点,比较好统计票数。
3. Nacos的CP处理数据一致性算法
在nacos中的cp架构中,默认的一致性算法是SofaJRaft,主要流程包括leader选举、写数据、故障恢复、脑裂问题。
3.1. 分布式一致性
什么是分布式一致性呢。
如果你只有一个节点,写数据只需要发送给这个节点就可以了,不需要考虑数据一致性问题。
如果你有多个节点呢,这时候就需要考虑数据的协调了,那如何解决呢。我们这个节点有状态,分别分为Follower state、Candidate state (候选者)、Leader state。
在集群(三个)刚开始启动的时候,他们的角色都是Follower,那他们怎么变呢,会有一个倒计时,如果我们的follower没有收到leader的消息的话(心跳消息),其中有一个节点就会成为一个candidate,成为candidate后,就会发送选票给其他节点说,我想成为leader。那如何成为leader呢,只有节点中大多数节点同意成为它为leader时,才成为leader。这个时候,整个集群中是有三票的(包括它也有一票),首先candidate会给自己给投一票。
那怎么写数据呢,肯定将数据写到leader之上,但写到leader之上也不会立即成功,而是会写到一个日志文件,表示我想要更新这个数据。当前的日志文件没有提交,然后通过心跳把需要更新的内容(log文件),发给其它的节点,其它节点同意写的话,会给leader节点一个同意的反馈,leader收到同意后就会写入,应用到自己的内存当中,然后给其他节点发送消息,将数据更新的内容,同步到其它节点。然后就会给客户端一个反馈,表示这个一致性已经到达了。两阶段的提交,第一个阶段是写日志文件,第二个阶段是写数据。
第一阶段:发送log文件给其他follower节点
第二阶段:通知所有节点可以把log文件应用到内存
3.2. leader选举
怎么进行leader选举呢,在每个节点启动的时候都会有一个倒计时,这个倒计时是随机的,这个倒计时时间,谁先结束,那么谁就会成为condidate,这个随机时间初始化为150ms - 300ms之间。成为condidate后先投给自己一票,然后发送请求给其他节点,其它节点接受到的后,如果没有发生给其他的condidate,那么就会把选票发送给它。成为leader后,会定时发送请求给其他节点,说自己是leader并且还存活。
3.3. leader故障
如果leader出现了故障,挂掉了怎么办呢。其它节点收不到leader的心跳后,就认为leader挂了,然后重新进行选举,倒计时成为condidate,发送选票,成为leader。
如果出现选票一样,那么再次进行随机时间,在进行选举。
3.4. 脑裂问题
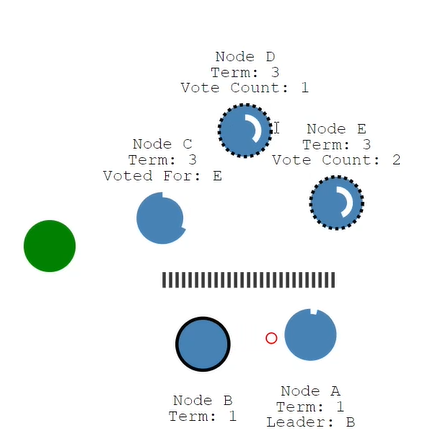
由于网络故障,形成了网络分区,重新选举了一个leader,现在就有两个leader。如果写的请求发送给B,B最多可以获取到两票,没有过半,所以更新数据不会成功。发生脑裂的时候,拥有多半节点的leader可以写成功,小于则写不成功。
如果网络恢复了,那么就拥有了两个leader,这是不允许的,因为这个时候客户端就不知道把数据写给谁了。两个leader中都会有一个日志文件,那么到底谁把日志文件删除,回滚呢。主要是这两个问题。
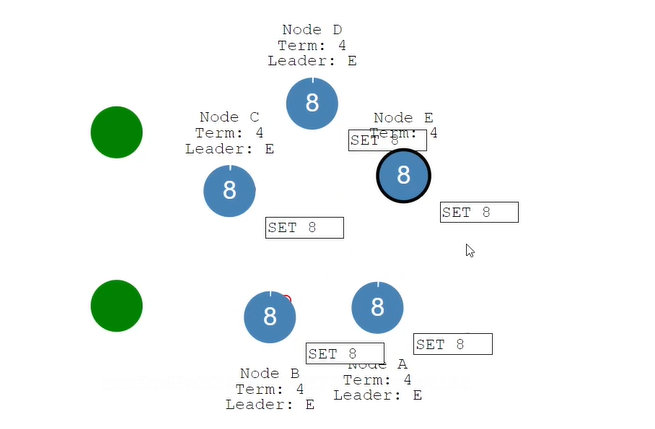
会选择日志比较新的leader保留,其它leader就变成follower节点















 4382
4382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









