







1.线性回归函数loss function :残差平方和,系数1/2 消除求导时系数
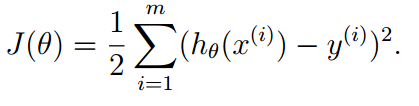
为什么选择这个函数作为loss function?

PS:中心极限定理:如果误差是由许多共同效应产生的,且都是独立的,效应的综合趋向于服从高斯分布。
因此
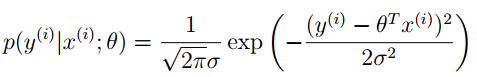
然后,求最大似然估计值,化简后,发现相当于最小化上面的loss function函数

2.最小化loss function,确定参数θ
(1)最小二乘法,直接使用数学推导的公式
(2)梯度下降法(gradient descent) -得到局部最小值
a) batch gradient descent批梯度下降 :每次θ的更新迭代使用全部的训练数据
b) 增量(随机)梯度下降:每次只使用一条数据 (会不断在收敛处徘徊)
(3)牛顿法
可求函数f(θ)=0的解
迭代式子:
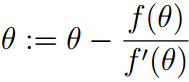
求解最大似然估计时,可转化成求L‘(θ)=0的解
当θ是向量时,迭代公式如下:

其中H是Hessian矩阵
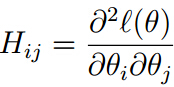
牛顿法收敛速度快,迭代次数少,但是计算量较大(求Hessian矩阵的逆)。当θ的维数不是太大,总体还是计算得比较快。
3 locally weighted linear regression
每条数据的贡献不一样,增加权重系数ω
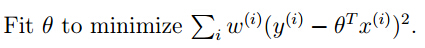
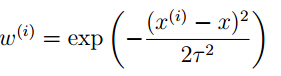
其中x是要预测的特征,与x越相似,权重越大。
θ无法预先计算,预测的特征x不同,θ的值也不一样。
此方法称为非参数学习算法















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









