







完整项目可私信博主获取
任务描述
停车场车位识别任务,主要完成下面几件事情:
- 在整个停车场当中,一共有多少辆车,一共有多少个空余的停车位,这样就能知道有多少个停车位是空余的
- 把空余的停车位标识出来,这样用户停车的时候,就可以一步到位,直接去空余的停车位处,为停车节省了很多时间
整体流程梳理
- 先通过一步过滤操作, 去掉多余的部分,只把停车场部分保留下来
- 把每一个停车位都给标记出来
- 训练模型判断当前的停车位有没有车(二分类任务)
- 把没有车的车位标识出来即可
数据介绍
这里面用个test_images目录,这里面的两张图片就是从视频中截出来的两帧图像。 后面就是基于这两张图片进行预测操作。
这里面还有train目录,存放的是模型训练的的图片,这个就和之前做的那个花分类的任务一致了,这里为了增加难度,打算后面用pytorch去训练模型,而不是用keras了。正好拿这个项目练练手。
图像预处理
图像预处理主要是一些二值化,灰度化的一些操作,将图片中的重要信息进行突出显示。
- 首先是阈值的操作,把图片中的背景信息给过滤掉,具体的话是根据像素的阈值,制作了一个mask矩阵,然后把这个矩阵放到图片上进行遮盖,保留了有效的信息
- 接下来,把上面的图片转成了灰度图像
- 采用边缘检测算法,把图片中的边缘给找出来
- 特定点标定连线,把停车场的这部分图像保留下来,把停车场之外的图片给去掉,具体实施就是手动选取停车场周围的点,一般是角点,然后把线连起来
- 基于霍夫变换中的直线检测,去找到停车场中的直线, 后面要根据直线锁定车位
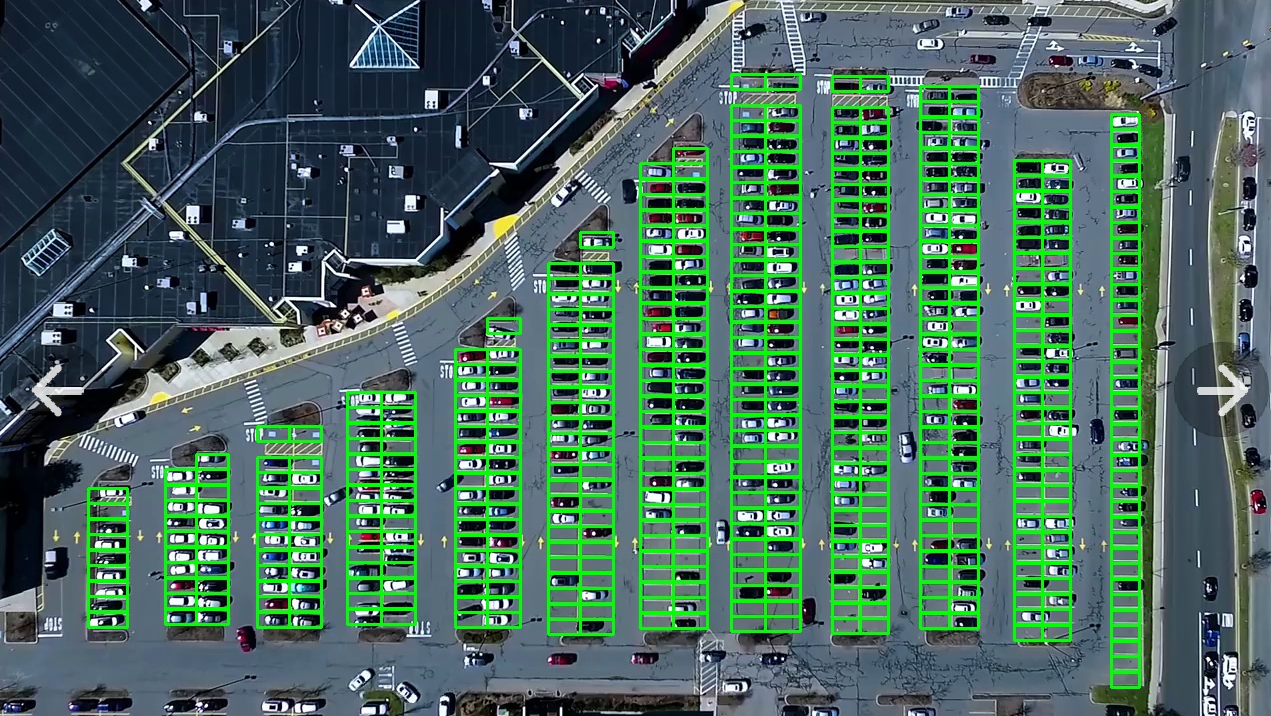
- 区域划分,把这个大的停车场划分成一列一列的,然后再从每一列里面去找停车位,然后标定号
- 选择出每一列去操作。通过手动坐标标定,把一个个的停车位找到拿出来
模型训练
这里是训练神经网络分类模型的过程,这里的网络是用的VGG16, 采用迁移学习的方式,一个原因是训练数据太少,从头开始训练效果不好,另一个是节省训练时间。训练完了之后,就对上面的一个个的停车位进行二分类的预测, 看看有没有车即可
Description:
图像预处理部分,主要是处理原始的停车场图片,通过一些图像预处理的技术,把里面的停车位一个个的提取出来, 主要包括下面的流程:
- 读入图像, 过滤掉背景
- Canny边缘检测找边缘
- 选出停车场区域, 使用霍夫变换找直线
- 根据直线信息, 以列为单位把停车位先进行划分开,每一列用一个矩形框先划分出来
- 可视化下,然后人工把每一列的矩形框进行微调,保证正好把所有停车位包起来
- 遍历每一列停车位,使用矩形框把每一个停车位用直线划分开,这个就是常规的坐标操作
- 可视化下上面划分结果,根据实际情况手工对直线进行调整,这里依然是保证尽量直线对其停车位分割线
- 调整完之后, 把停车位的坐标(左上和右下)以及编号进行保存, 这里要注意保存之前去掉无效的停车位。
保存的数据,作为后面卷积神经网络预测的数据集
import os
# golb模块是用来查找符合特定规则命名的文件名的“路径+文件名”,其功能就是检索路径
import glob
import numpy as np
import cv2
import matplotlib.pyplot as plt
from PIL import Image
import pickle
import operator
import collections
def cv_imshow(title, img):
cv2.imshow(title, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def plt_imshow(img, cmap=None):
cmap = 'gray' if len(img.shape) == 2 else cmap
plt.imshow(img, cmap=cmap)
plt.xticks([])
plt.yticks([])
plt.show()
读入图像数据
# 读入数据
test_images = [cv2.imread(path) for path in glob.glob('../test_images/*.jpg')] # BGR
- glob.glob: 返回所有匹配的文件路径列表,如果路径这里使用绝对路径,那么返回的列表也是绝对路径
- glob.iglob: 获取一个可遍历对象,使用它可以逐个获取匹配的文件路径名。
- 与glob.glob()的区别是:glob.glob同时获取所有的匹配路径,而glob.iglob一次只获取一个匹配路径,同时glob.iglob返回的是一个生成器类型
cv_imshow('test', test_images[1])
# 后面就直接用某一张
test_image = test_images[1]
过滤掉背景
def select_rgb_white_yellow(image):
# 过滤背景
lower = np.uint8([120, 120, 120])
upper = np.uint8([255, 255, 255])
# 三个通道内,低于lower和高于upper的部分分别变成0, 在lower-upper之间的值变成255, 相当于mask,过滤背景
# 保留了像素值在120-255之间的像素值
white_mask = cv2.inRange(image, lower, upper)
masked_img = cv2.bitwise_and(image, image, mask=white_mask)
return masked_img
这里看到inRange,想到了之前用到的二值化的方法threshold, 我在想这俩有啥区别? 为啥这里不用这个了? 下面是我经过探索得到的几点使用经验:
cv2.threshold(src, thresh, maxval, type[, dst]):针对的是单通道图像(灰度图), 二值化的标准,type=THRESH_BINARY: if x > thresh, x = maxval, else x = 0, 而type=THRESH_BINARY_INV: 和上面的标准反着,目前常用到了这俩个cv2.inRange(src, lowerb, upperb):可以是单通道图像,可以是三通道图像,也可以进行二值化,标准是if x >= lower and x <= upper, x = 255, else x = 0
这里做了一个实验, 事先把图片转化成灰度图warped = cv2.cvtColor(test_image, cv2.COLOR_BGR2GRAY),然后下面两句代码的执行结果是一样的:
cv2.threshold(warped, 119, 255, cv2.THRESH_BINARY)[1]cv2.inRange(warped, 120, 255)
masked_img = select_rgb_white_yellow(test_image)
cv_imshow('masked_img', masked_img)
# 转成灰度图
gray_img = cv2.cvtColor(masked_img, cv2.COLOR_BGR2GRAY)
cv_imshow('masked_img', gray_img)
Canny边缘检测
low_threshold, high_threshold = 50, 200
edges_img = cv2.Canny(gray_img, low_threshold, high_threshold)
cv_imshow('edge_img', edges_img)
停车场区域提取
接下来, 只选出停车场的这块区域来, 把其余部分去掉
def select_region(image):
"""这里手动选择区域"""
rows, cols = image.shape[:2]
# 下面定义6个标定点, 这个点的顺序必须让它化成一个区域,如果调整,可能会交叉起来,所以不要动
pt_1 = [cols*0.06, rows*0.90] # 左下
pt_2 = [cols*0.06, rows*0.70] # 左上
pt_3 = [cols*0.32, rows*0.51] # 中左
pt_4 = [cols*0.6, rows*0.1] # 中右
pt_5 = [cols*0.90, rows*0.1] # 右上
pt_6 = [cols*0.90, rows*0.90] # 右下
vertices = np.array([[pt_1, pt_2, pt_3, pt_4, pt_5, pt_6]], dtype=np.int32)
point_img = image.copy()
point_img = cv2.cvtColor(point_img, cv2.COLOR_GRAY2BGR)
for point in vert 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











