









 本文详细介绍了如何将YOLOV5模型转换为ONNX格式,并在OpenCV环境中进行部署。首先,针对NVIDIA-TensorRT安装失败的问题,提供了从源码安装的步骤,包括安装CUDNN、CUDA Toolkit以及设置环境变量。接着,利用YOLOV5的export.py脚本将.pt模型转换为.onnx,特别提到在OpenCV 4.70环境下,需要设置opset参数为12。最后,文章讨论了模型转换后的测试过程,包括解决ONNXRuntime报错和使用OpenCV的dnn模块进行目标检测的注意事项。
本文详细介绍了如何将YOLOV5模型转换为ONNX格式,并在OpenCV环境中进行部署。首先,针对NVIDIA-TensorRT安装失败的问题,提供了从源码安装的步骤,包括安装CUDNN、CUDA Toolkit以及设置环境变量。接着,利用YOLOV5的export.py脚本将.pt模型转换为.onnx,特别提到在OpenCV 4.70环境下,需要设置opset参数为12。最后,文章讨论了模型转换后的测试过程,包括解决ONNXRuntime报错和使用OpenCV的dnn模块进行目标检测的注意事项。
将模型转为onnx、RT等用于部署
yolov5s 6.0自带export.py程序可将.pt转为.onnx等,只需配置需要的环境即可。
1. 安装环境
activate pytorch
pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu # CPU
pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
报错:NVIDIA-tensorrt安装失败!
解决:从源码安装TensorRt:
①安装CUDNN和CudaToolKit等GPU配置
②从官网下载需要的rt版本:https://developer.nvidia.com/nvidia-tensorrt-8x-download


③解压后,将lib文件夹添加到环境变量path中
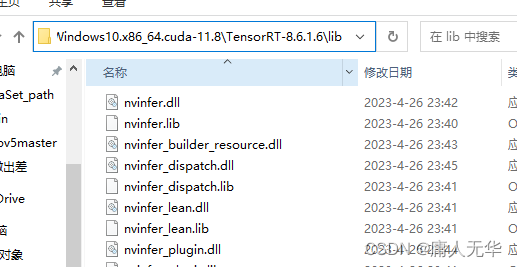
④将lib中全部文件复制到CUDA的lib\x64文件夹下,并将该x64文件夹路径添加到环境变量path中
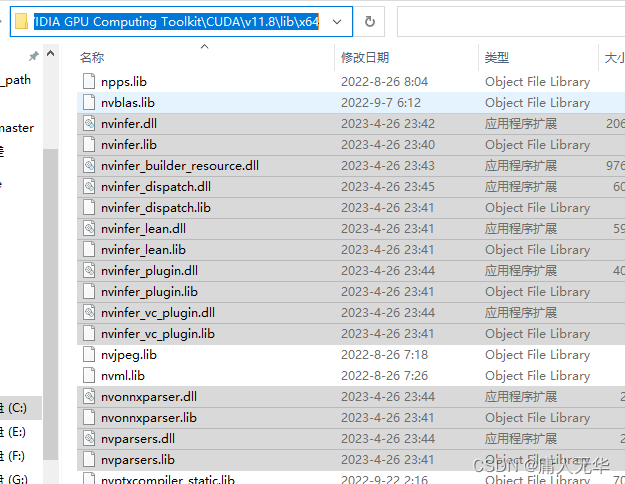
⑤安装RT依赖:
activate pytorch
pip install E:\Anaconda3.5\TensorRT-8.6.1.6.Windows10.x86_64.cuda-11.8\TensorRT-8.6.1.6\python\tensorrt-8.6.1-cp39-none-win_amd64.whl
安装完成后会出现successfully的字样,到这里tensorrt已经安装结束。
2. pt转onnx
yolov5自带的export.py可进行转换。yolov5 v6.0版本以后的支持opencv,不需要更改网络层。
命令行启动:
python export.py --weights yolov5s.pt --include onnx --opset 12
程序启动修改处:
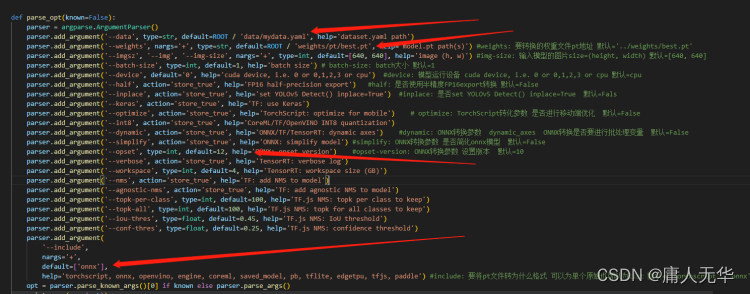
*** opset参数与protobuf有关,当前使用的opencv470,需要设定opset参数为12时才能识别对应的onnx文件。按F5启动程序后,会在原pt文件夹下生成同名的onnx文件。***
测试①:
用yolov5自带的detect.py检测生成的onnx文件,若报错:“onnxruntime::Model::Model Unknown model file format version“
解决:降低onnxruntime版本:
pip install onnxruntime-gpu==1.14 -i https://pypi.tuna.tsinghua.edu.cn/simple
测试②:
重新配置C++、opencv4.7环境,用opencv的dnn接口读取onnx并检测目标。
:1.用断点调试,测试net读取模型(net = readNet(netPath))能否成功,也有readNetFromONNX等。
2.注意绘图时的边界问题。
3.修改类别、图像路径、权重路径。
//main:
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <highgui/highgui_c.h>
#include <iostream>
#include "yolov5.h"
using namespace cv;
using namespace cv::dnn;
using namespace std;
int main()
{
string img_path = "F:/vscode/006.jpg";
string model_path = "F:/Object Detect/network/yolov5master/weights/pt/best.onnx";
// int num_devices = cv::cuda::getCudaEnabledDeviceCount();
// if (num_devices <= 0) {
// cerr << "There is no cuda." << endl;
// return -1;
// }
// else {
// cout << num_devices << endl;
// }
Yolov5 test;
Net net;
if (test.readModel(net, model_path, false)) {
cout << "read net ok!" << endl;
}
else {
return -1;
}
//生成随机颜色
vector<Scalar> color;
srand(time(0));
for (int i = 0; i < 80; i++) {
int b = rand() % 256;
int g = rand() % 256;
int r = rand() % 256;
color.push_back(Scalar(b, g, r));
}
vector<Output> result;
Mat img = imread(img_path);
resize(img,img,Size(480,640));
if (test.Detect(img, net, result)) {
test.drawPred(img, result, color);
}
else {
cout << "Detect Failed!"<<endl;
}
system("pause");
return 0;
}
//yolov5.h:
#pragma once
#include <iostream>
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/highgui.hpp>
using namespace cv;
using namespace dnn;
using namespace std;
#define YOLO_P6 false //是否使用P6模型
struct Output {
int id; //结果类别id
float confidence; //结果置信度
cv::Rect box; //矩形框
};
class Yolov5 {
public:
Yolov5() {
}
~Yolov5() {}
bool readModel(cv::dnn::Net& net, std::string& netPath, bool isCuda);
bool Detect(cv::Mat& SrcImg, cv::dnn::Net& net, std::vector<Output>& output);
void drawPred(cv::Mat& img, std::vector<Output> result, std::vector<cv::Scalar> color);
private:
void LetterBox(const cv::Mat& image, cv::Mat& outImage,
cv::Vec4d& params, //[ratio_x,ratio_y,dw,dh]
const cv::Size& newShape = cv::Size(640, 640),
bool autoShape = false,
bool scaleFill = false,
bool scaleUp = true,
int stride = 32,
const cv::Scalar& color = cv::Scalar(114, 114, 114));
#if(defined YOLO_P6 && YOLO_P6==true)
const int _netWidth = 1280; //ONNX图片输入宽度
const int _netHeight = 1280; //ONNX图片输入高度
#else
const int _netWidth = 640; //ONNX图片输入宽度
const int _netHeight = 640; //ONNX图片输入高度
#endif // YOLO_P6
float _classThreshold = 0.25;
float _nmsThreshold = 0.45;
public:
std::vector<std::string> _className = {"fire"};
// std::vector<std::string> _className = { "person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light",
// "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow",
// "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee",
// "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard",
// "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple",
// "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch",
// "potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone",
// "microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear",
// "hair drier", "toothbrush" };
};
//yolov5.cpp:
#include "yolov5.h"
#include<iostream>
#include <cassert>
#include <time.h>
using namespace std;
using namespace cv;
using namespace cv::dnn;
void Yolov5::LetterBox(const cv::Mat& image, cv::Mat& outImage, cv::Vec4d& params, const cv::Size& newShape,
bool autoShape, bool scaleFill, bool scaleUp, int stride, const cv::Scalar& color)
{
if (false) {
int maxLen = MAX(image.rows, image.cols);
outImage = Mat::zeros(Size(maxLen, maxLen), CV_8UC3);
image.copyTo(outImage(Rect(0, 0, image.cols, image.rows)));
params[0] = 1;
params[1] = 1;
params[3] = 0;
params[2] = 0;
}
cv::Size shape = image.size();
float r = std::min((float)newShape.height / (float)shape.height,
(float)newShape.width / (float)shape.width);
if (!scaleUp)
r = std::min(r, 1.0f);
float ratio[2]{ r, r };
int new_un_pad[2] = { (int)std::round((float)shape.width * r),(int)std::round((float)shape.height * r) };
auto dw = (float)(newShape.width - new_un_pad[0]);
auto dh = (float)(newShape.height - new_un_pad[1]);
if (autoShape)
{
dw = (float)((int)dw % stride);
dh = (float)((int)dh % stride);
}
else if (scaleFill)
{
dw = 0.0f;
dh = 0.0f;
new_un_pad[0] = newShape.width;
new_un_pad[1] = newShape.height;
ratio[0] = (float)newShape.width / (float)shape.width;
ratio[1] = (float)newShape.height / (float)shape.height;
}
dw /= 2.0f;
dh /= 2.0f;
if (shape.width != new_un_pad[0] && shape.height != new_un_pad[1])
{
cv::resize(image, outImage, cv::Size(new_un_pad[0], new_un_pad[1]));
}
else {
outImage = image.clone();
}
int top = int(std::round(dh - 0.1f));
int bottom = int(std::round(dh + 0.1f));
int left = int(std::round(dw - 0.1f));
int right = int(std::round(dw + 0.1f));
params[0] = ratio[0];
params[1] = ratio[1];
params[2] = left;
params[3] = top;
cv::copyMakeBorder(outImage, outImage, top, bottom, left, right, cv::BORDER_CONSTANT, color);
}
bool Yolov5::readModel(Net& net, string& netPath, bool isCuda = false) {
try {
net = readNet(netPath);
#if CV_VERSION_MAJOR==4 &&CV_VERSION_MINOR==7&&CV_VERSION_REVISION==0
net.enableWinograd(false); //bug of opencv4.7.x in AVX only platform ,https://github.com/opencv/opencv/pull/23112 and https://github.com/opencv/opencv/issues/23080
//net.enableWinograd(true); //If your CPU supports AVX2, you can set it true to speed up
#endif
}
catch (const std::exception&) {
return false;
}
//cuda
if (isCuda) {
net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
}
//cpu
else {
net.setPreferableBackend(cv::dnn::DNN_BACKEND_DEFAULT);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);
}
return true;
}
bool Yolov5::Detect(Mat& SrcImg, Net& net, vector<Output>& output) {
Mat blob;
int col = SrcImg.cols;
int row = SrcImg.rows;
int maxLen = MAX(col, row);
Mat netInputImg = SrcImg.clone();
Vec4d params;
LetterBox(SrcImg, netInputImg, params, cv::Size(_netWidth, _netHeight));
blobFromImage(netInputImg, blob, 1 / 255.0, cv::Size(_netWidth, _netHeight), cv::Scalar(0, 0, 0), true, false);
//如果在其他设置没有问题的情况下但是结果偏差很大,可以尝试下用下面两句语句
//blobFromImage(netInputImg, blob, 1 / 255.0, cv::Size(_netWidth, _netHeight), cv::Scalar(104, 117, 123), true, false);
//blobFromImage(netInputImg, blob, 1 / 255.0, cv::Size(_netWidth, _netHeight), cv::Scalar(114, 114,114), true, false);
net.setInput(blob);
std::vector<cv::Mat> netOutputImg;
//vector<string> outputLayerName{"345","403", "461","output" };
//net.forward(netOutputImg, outputLayerName[3]); //获取output的输出
net.forward(netOutputImg, net.getUnconnectedOutLayersNames());
std::vector<int> classIds;//结果id数组
std::vector<float> confidences;//结果每个id对应置信度数组
std::vector<cv::Rect> boxes;//每个id矩形框
int net_width = _className.size() + 5; //输出的网络宽度是类别数+5
int net_out_width = netOutputImg[0].size[2];
//assert(net_out_width == net_width, "Error Wrong number of _className"); //模型类别数目不对
float* pdata = (float*)netOutputImg[0].data;
int net_height = netOutputImg[0].size[1];
for (int r = 0; r < net_height; ++r) {
float box_score = pdata[4]; ;//获取每一行的box框中含有某个物体的概率
if (box_score >= _classThreshold) {
cv::Mat scores(1, _className.size(), CV_32FC1, pdata + 5);
Point classIdPoint;
double max_class_socre;
minMaxLoc(scores, 0, &max_class_socre, 0, &classIdPoint);
max_class_socre = max_class_socre* box_score;
if (max_class_socre >= _classThreshold) {
//rect [x,y,w,h]
float x = (pdata[0] - params[2]) / params[0];
float y = (pdata[1] - params[3]) / params[1];
float w = pdata[2] / params[0];
float h = pdata[3] / params[1];
int left = MAX(round(x - 0.5 * w +0.5), 0);
int top = MAX(round(y - 0.5 * h+0.5 ), 0);
classIds.push_back(classIdPoint.x);
confidences.push_back(max_class_socre );
boxes.push_back(Rect(left, top, int(w + 0.5), int(h + 0.5)));
}
}
pdata += net_width;//下一行
}
//执行非最大抑制以消除具有较低置信度的冗余重叠框(NMS)
vector<int> nms_result;
NMSBoxes(boxes, confidences, _classThreshold, _nmsThreshold, nms_result);
for (int i = 0; i < nms_result.size(); i++) {
int idx = nms_result[i];
Output result;
result.id = classIds[idx];
result.confidence = confidences[idx];
result.box = boxes[idx];
output.push_back(result);
}
if (output.size())
return true;
else
return false;
}
void Yolov5::drawPred(Mat& img, vector<Output> result, vector<Scalar> color) {
for (int i = 0; i < result.size(); i++) {
int left, top;
left = result[i].box.x;
top = result[i].box.y;
int color_num = i;
rectangle(img, result[i].box, color[result[i].id], 2, 8);
string label = _className[result[i].id] + ":" + to_string(result[i].confidence);
int baseLine;
Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
top = max(top, labelSize.height);
//rectangle(frame, Point(left, top - int(1.5 * labelSize.height)), Point(left + int(1.5 * labelSize.width), top + baseLine), Scalar(0, 255, 0), FILLED);
putText(img, label, Point(left, top), FONT_HERSHEY_SIMPLEX, 1, color[result[i].id], 2);
}
imshow("1", img);
//imwrite("out.bmp", img);
waitKey(0);
//destroyAllWindows();
}
效果:


















 2275
2275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









