







| Python正则表达式详细介绍! |
文章目录
一. 正则表达式基础
1.1. 简单介绍
- 正则表达式并不是Python的一部分。正则表达式是用于 处理字符串 的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。
- 下图展示了使用 正则表达式进行匹配的流程:

- 正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
1.2. Python支持的正则表达式元字符和语
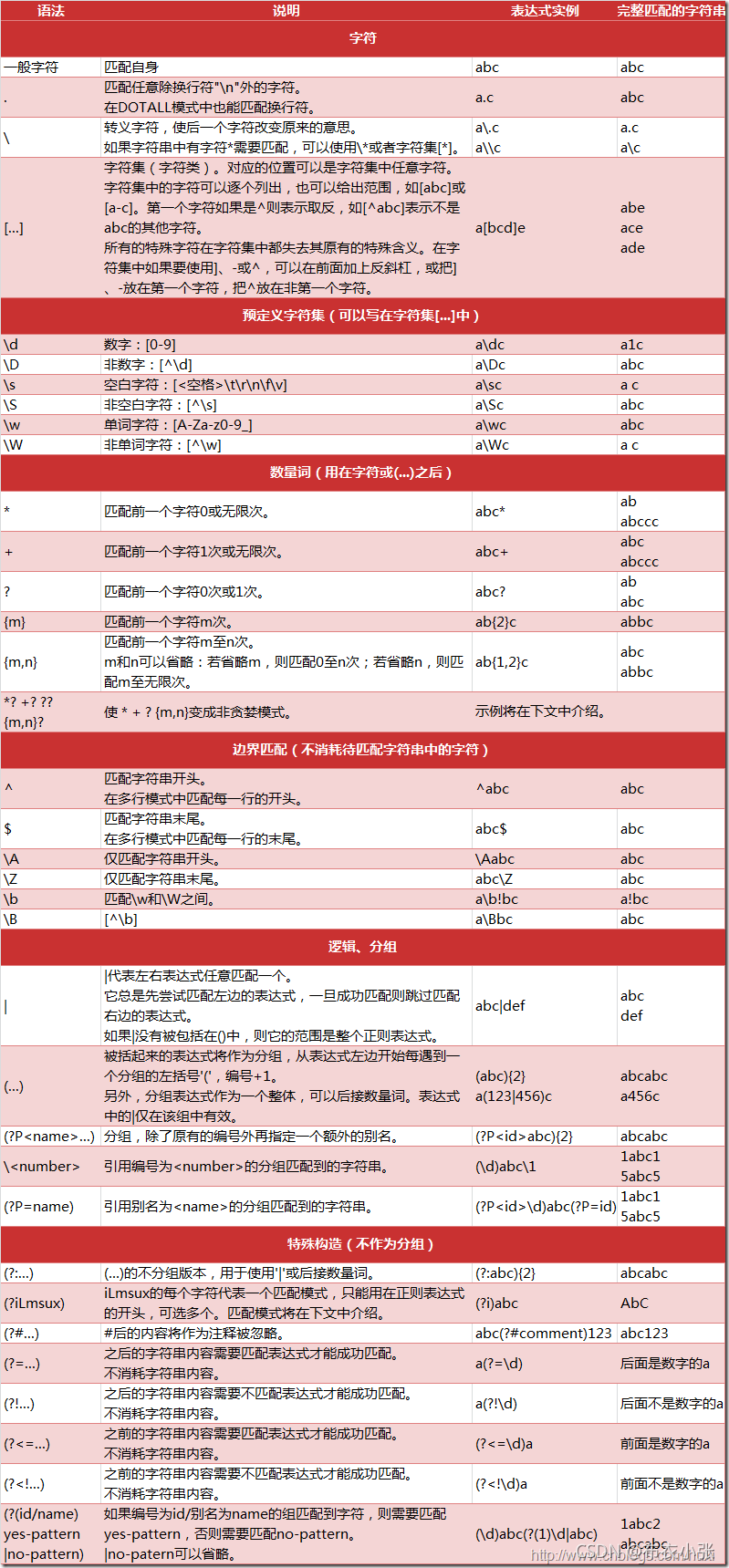
1.2. 正则表达式中^的用法(限定开头和取反)

1.3. 数量词的贪婪模式(Python里数量词默认)与非贪婪模式
- 正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的 (在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式
"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。
1.4. 反斜杠的困扰
- 与大多数编程语言相同,正则表达式里使用
"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。- 注意:
'r'是防止字符转义的 如果路径中出现'\t'的话 不加r的话\t就会被转义 而加了'r'之后'\t'就能保留原有的样子。
1.5. 匹配模式
- 正则表达式提供了一些可用的匹配模式,比如 忽略大小写、多行匹配 等,这部分内容将在
Pattern类的工厂方法re.compile(pattern[, flags])中一起介绍。
二. re模块
2.1. 开始使用re
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
import re
# 将正则表达式编译为Pattern对象
pattern = re.compile(r'hello')
# 使用Pattern匹配文本,获得匹配结果,无法匹配返回None
match = pattern.match('hello world!')
if match:
# 使用Match获得分组信息
print(match.group())
# 返回结果:
hello
re.compile(strPattern[, flag])- 这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符’|'表示同时生效,比如
re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)S(DOTALL): 点任意匹配模式,改变'.'的为 任意行为L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的:
- 具体见下图:

- Python正则表达式,这一篇就够了:https://zhuanlan.zhihu.com/p/127807805
a = re.compile(r"""\d + # the integral part
\. # the decimal point
\d * # some fractional digits""", re.X)
b = re.compile(r"\d+\.\d*")
re提供了众多模块方法用于完成正则表达式的功能。这些方法可以使用Pattern实例的相应方法替代,唯一的好处是少写一行re.compile()代码,但同时也无法复用编译后的Pattern对象。这些方法将在Pattern类的实例方法部分一起介绍。如上面这个例子可以简写为:
m = re.match(r'hello', 'hello world!')
print(m.group())
# 返回结果:
hello
re模块还提供了一个方法escape(string),用于将string中的正则表达式元字符如*/+/?等之前加上转义符再返回,在需要大量匹配元字符时有那么一点用。
2.2. Match
- Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
- 属性如下:
- string: 匹配时使用的文本。
- re: 匹配时使用的Pattern对象。
- pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
- lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
- 方法如下:
group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。> 1. group默认值为0。- span([group]):
返回(start(group), end(group))。expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g、\g引用分组,但不能使用编号0。\id与\g是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符’0’,只能使用\g<1>0。
import re
m = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello world!!')
print(m.string)
print(m.re)
print(m.pos)
print(m.endpos)
print(m.lastindex)
print(m.lastgroup)
print(m.group(1, 2))
print(m.groups())
print(m.groupdict())
print(m.start(2))
print(m.end(2))
print(m.span(2))
print(m.expand(r'\2 \1\3'))

2.3. Pattern
- Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。
- Pattern不能直接实例化,必须使用re.compile() 进行构造。
- Pattern提供了几个可读属性用于获取表达式的相关信息:
- pattern: 编译时用的表达式字符串。
- flags: 编译时用的匹配模式。数字形式。
- groups: 表达式中分组的数量。
- groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
import re
p = re.compile(r'(\w+) (\w+)(?P<sign>.*)', re.DOTALL)
print(f"p.pattern:{p.pattern}")
print(f"p.flags:{p.flags}")
print(f"p.groups:{p.groups}")
print(f"p.groupindex:{p.groupindex}")
- 执行结果

2.3.1. 实例方法[或re模块方法]

1). match()
- match(string[, pos[, endpos]]) 或者 re.match(pattern, string[, flags]):
- 这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。
- pos和endpos的默认值分别为0和len(string);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
- 注意: 这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符
'$'。示例参见2.1小节。
2). search()
- search(string[, pos[, endpos]]) 或者 re.search(pattern, string[, flags]):
- 这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。
- pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
import re
# 将正则表达式编译成Pattern对象
pattern = re.compile(r'world')
# 使用search()查找匹配的子串,不存在能匹配的子串时将返回None
# 这个例子中使用match()无法成功匹配
match = pattern.search('hello world world!')
if match:
# 使用Match获得分组信息
print(match.group())
# 执行结果:
world
import re
text = '"学校" "反映麻步镇正虹饲料厂每晚八九点钟开始排放浓烈刺鼻气味的气体,有时白天也会排放,严重影响附近村民和学校学生生活和学习。"'
keywords = ["垃圾", "废物", "废弃物", "废料", "废油桶废水", "污水", "汽油", "化学物品", "腐蚀", "硫酸", "烟花", "易燃易爆", "煤气罐", "刺鼻", "异味"]
print("|".join(keywords))
re.search("|".join(keywords), text)
垃圾|废物|废弃物|废料|废油桶废水|污水|汽油|化学物品|腐蚀|硫酸|烟花|易燃易爆|煤气罐|刺鼻|异味
<re.Match object; span=(28, 30), match='刺鼻'>
3). split()
- split(string[, maxsplit]) 或者 re.split(pattern, string[, maxsplit]):
- 按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
import re
p = re.compile(r'\d+')
print(p.split('one1two2three3four4', maxsplit=2))
print(p.split('one1two2three3four4'))
# 执行结果
# ['one', 'two', 'three3four4']
# ['one', 'two', 'three', 'four', '']
4). findall()
- findall(string[, pos[, endpos]]) 或者 re.findall(pattern, string[, flags]):
- 搜索string,以列表形式 返回全部能匹配的子串。
import re
p = re.compile(r'\d+')
print(p.findall('one1two289eethree3four4'))
# 执行结果
# ['1', '289', '3', '4']
5). finditer()
- inditer(string[, pos[, endpos]]) 或者 re.finditer(pattern, string[, flags]):
- 搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
import re
p = re.compile(r'\d+')
for m in p.finditer('one1two289three3four4'):
print(m.group(), end=" ")
# 执行结果
# 1 289 3 4
6). sub()
- 使用repl替换string中每一个匹配的子串后返回替换后的字符串。
- 当repl是一个字符串时,可以使用\id或\g、\g引用分组,但不能使用编号0。
- 当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
- count用于指定最多替换次数,不指定时全部替换。
import re
p = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!'
print(p.sub(r'\2 \1', s))
def func(m):
return m.group(1).title() + ' ' + m.group(2).title()
print(p.sub(func, s))
# 执行结果
# say i, world hello!
# I Say, Hello World!
7). subn()
- subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
- 返回 (sub(repl, string[, count]), 替换次数)。
import re
p = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!'
print(p.subn(r'\2 \1', s))
def func(m):
return m.group(1).title() + ' ' + m.group(2).title()
print(p.subn(func, s))
# 执行结果
# ('say i, world hello!', 2)
# ('I Say, Hello World!', 2)
三. 正则表达式匹配中文
- 1. 匹配字符串中的第一个中文字符(search):
import re
p = re.compile(r'[\u4e00-\u9fa5]')
text='123,39rjqkefq张开放,王晓明12,李争23fe!'
match = p.search(text)
print(match)
# print(match.group())
# 执行结果:
# <re.Match object; span=(13, 14), match='张'>
- 2. 匹配字符串中的第一个连续的中文片段(search):
import re
p = re.compile(r'[\u4e00-\u9fa5]+')
text='123,39rjqkefq张开放,王晓明12,李争23fe!'
match = p.search(text)
print(match)
# print(match.group())
# 执行结果:
# <re.Match object; span=(13, 16), match='张开放'>
- 3. 匹配字符串中的所有中文字符:
import re
p = re.compile(r'[\u4e00-\u9fa5]')
text='123,39rjqkefq张开放,王晓明12,李争23fe!'
match = p.findall(text)
print(match)
# 执行结果:
# ['张', '开', '放', '王', '晓', '明', '李', '争']
- 4. 匹配字符串中的所有中文字符:
import re
p = re.compile(r'[\u4e00-\u9fa5]+')
text='123,39rjqkefq张开放,王晓明12,李争23fe!'
match = p.findall(text)
print(match)
# 执行结果:
# ['张开放', '王晓明', '李争']
- 注意:要确保正则字符和匹配文本是 unicode 范围内的编码。
- 正则匹配中文应用如下:
import re
p = re.compile('([a-z]+.[a-z]+)([\u4e00-\u9fa5]+)')
text = 'box.bty图例框的类型,box.lty决定是否为虚线,box.lwd决定粗线,box.col决定颜色'
match = p.findall(text)
print(match)
# print(re.findall(r'([a-z]+.[a-z]+)([\u4e00-\u9fa5]+)',s))
# 执行结果:
# [('box.bty', '图例框的类型'), ('box.lty', '决定是否为虚线'), ('box.lwd', '决定粗线'), ('box.col', '决定颜色')]
四. 别名(?P<name>[0-9]{4})和邮箱和(.*?)与(.*)的区别
4.1. 别名
import re
pattern = re.compile('您尾号(?P<trading_partner>[0-9]{4})的储蓄卡.*?(?P<time>[0-9]{1,2}月[0-9]{1,2}日[0-9]{1,2}时[0-9]{1,2}分[0-9]{0,2}秒?).*?(?P<method>收入|支出|提现)人民币(?P<amount>[0-9]*\,*[0-9]+\.*[0-9]*).*?\[(?P<trader>建设银行)]')
text = "您尾号2462的储蓄卡6月7日12时52分向财付通-肯德基消费支出人民币22.50元,活期余额27.54元。[建设银行]"
result = pattern.match(text)
dict = result.groupdict()
print(dict)
# 执行结果:
{'trading_partner': '2462', 'time': '6月7日12时52分', 'method': '支出', 'amount': '22.50', 'trader': '建设银行'}
4.2. 邮箱
import re
pattern = re.compile(".*?(?P<content>[\.\-a-zA-Z0-9]+@[\-a-zA-Z0-9]+\.[a-zA-Z]+)")
def extract(text):
result = []
if "@" in text: # 先判断这些关键词是否在text中,如果不在,直接不用正则匹配, 提升速度;
res = pattern.match(text)
if not res: # 当前规则匹配失败,使用下一条匹配规则
pass
else: # 当前规则匹配成功
dict = res.groupdict()
dict["type"] = 4
dict["field_type"] = 406
result.append(dict)
return result
if __name__ == '__main__':
text = "泸州照涵电子商务有限公司kaifang.zkf-8410477036@163-a.com EE997788"
# text = "所有人阿玛尼满钻售价349元@40高佣 卡直播有男粉的 线上结算的 转化率超高 配合豆荚玩 投产1比5以上 12点后申请 马上申请 马上跑的http://pub.alimama.com/myunion.htm#!/promo/self/campaign? campaignId=116030358&shopkeeperId=1381270173&userNumberId=2208827680894记住一定要申请定向链接 不然系统会错误 佣金 结算错误阿玛尼满钻349元40高佣1号链接:https://item.taobao.com/item.htm? spm=a21an.7676007.1998473182.218.553a61db96iGal&id=626203129761阿玛尼带手表349元链接:https://item.taobao.com/item.htm? spm=a21an.7676007.1998473182.233.553a61db96iGal&id=626203565271阿玛尼石英表349元链接:https://item.taobao.com/item.htm? spm=a21an.7676007.1998473182.228.553a61db96iGal&id=626203457304满天星摩天轮349元链接:https://item.taobao.com/item.htm? spm=a21an.7676007.1998473182.213.553a61db96iGal&id=626202777905满天星银色石英表349链接:https://item.taobao.com/item.htm? spm=a21an.7676007.1998473182.203.553a61db96iGal&id=625884876313百度网盘 提取 最新阿玛尼素材链接:https://pan.baidu.com/s/1bPvy5waOi4Ufz-9vXlWbeg 提取码:0ez0淘宝要跑线下结算的 也可以找我 线下发货后 结算百分之70"
print(extract(text))
# 输出结果
# [{'content': 'kaifang.zkf-8410477036@163-a.com', 'type': 4, 'field_type': 406}]
# Process finished with exit code 0
4.3. (.*?)与(.*)的区别
- 首先在正则表达式中,通过
()是可以代表要提取的内容的,如参考:https://blog.csdn.net/weixin_43487902/article/details/88407311



五. 邮箱、身份证、手机号、电话、域名、IP地址、日期、邮编、中文字符…
- 使用Python验证常见的50个正则表达式:https://zhuanlan.zhihu.com/p/338826624
六. python正则匹配re.search与re.findall的区别
六. 参考文献
- 主要参考了以下作者,这里表示感谢!
- Python正则表达式指南(推荐):https://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
- Python正则表达式,这一篇就够了(推荐):https://zhuanlan.zhihu.com/p/127807805
- 使用Python验证常见的50个正则表达式:https://zhuanlan.zhihu.com/p/338826624
- python 正则表达式中匹配中文: https://www.cnblogs.com/shanger/p/12922135.html
- python正则过滤字母、中文、数字及特殊字符方法详解! https://www.jb51.net/article/180132.htm
















 2675
2675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











