








👏作者简介:大家好,我是爱敲代码的小王,CSDN博客博主,Python小白
📕系列专栏:python入门到实战、Python爬虫开发、Python办公自动化、Python数据分析、Python前后端开发
📧如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀
🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
🍂博主正在努力完成2023计划中:以梦为马,扬帆起航,2023追梦人
🔥🔥🔥 python入门到实战专栏:从入门到实战
🔥🔥🔥 Python爬虫开发专栏:从入门到实战
🔥🔥🔥 Python办公自动化专栏:从入门到实战
🔥🔥🔥 Python数据分析专栏:从入门到实战
🔥🔥🔥 Python前后端开发专栏:从入门到实战
目录
Python GIL(Global Interpreter Lock)
全局锁GIL问题

在python中,无论你有多少核,在Cpython解释器中永远都是假象。无论你是4核,8核,还是16核.......不好意思,同一时间执行的线程只有一个线程,它就是这个样子的。这个是python的一个开发时候,设计的一个缺陷,所以说python中的线程是“含有水分的线程”。
Python GIL(Global Interpreter Lock)
Python代码的执行由Python 虚拟机(也叫解释器主循环,CPython 版本)来控制,Python 在设计之初就考虑到要在解释器的主循环中,同时只有一个线程在执行,即在任意时刻,只有一个线程在解释器中运行。对Python 虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。
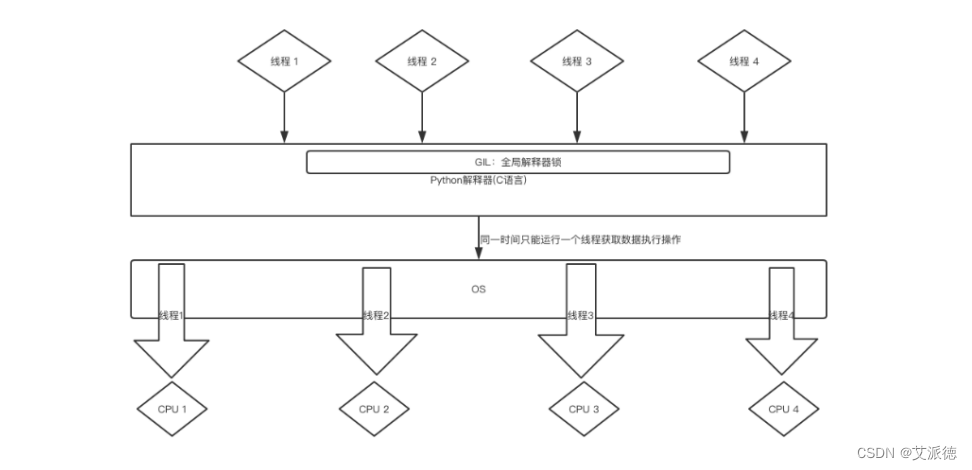
⚠️GIL并不是Python的特性,它是在实现Python解析器 (CPython)时所引入的一个概念,同样一段代码可以通过 CPython,PyPy,Psyco等不同的Python执行环境来执行,就没有GIL的问题。然而因为CPython是大部分环境下默认的Python 执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷
线程同步和互斥锁
同一个资源,多人想用?排队啊!
现实生活中,我们会遇到“同一个资源,多个人都想使用”的问题。 比如:教室里,只有一台电脑,多个人都想使用。天然的解决办法就是,在电脑旁边,大家排队。前一人使用完后,后 一人再使用。再比如,上厕所排队。

线程同步的概念
处理多线程问题时,多个线程访问同一个对象,并且某些线程还想修改这个对象。 这时候,我们就需要用到“线程同步”。 线程同步其实就是一种等待机制,多个需要同时访问此对象的线 程进入这个对象的等待池形成队列,等待前面的线程使用完毕后,下一个线程再使用。
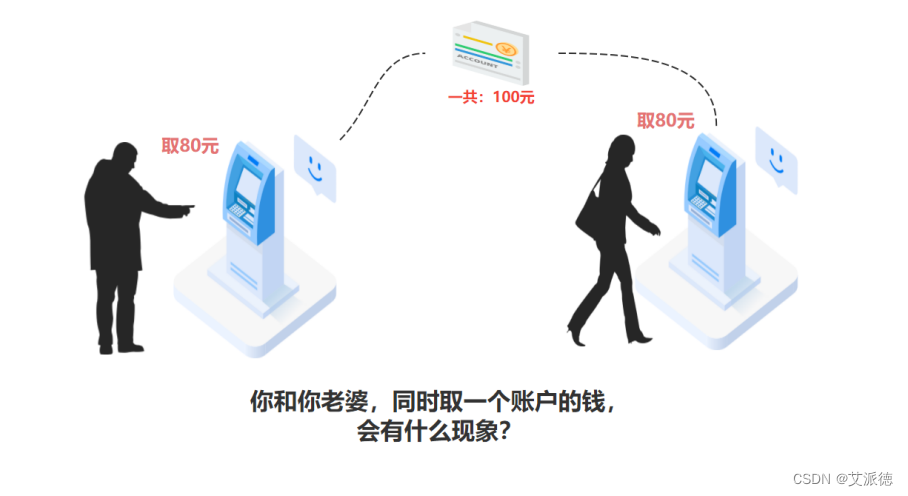
【示例】多线程操作同一个对象(未使用线程同步)
#encoding=utf-8
from threading import Thread
from time import sleep
class Account:
def __init__(self,money,name):
self.money = money
self.name = name
#模拟提款操作
class Drawing(Thread):
def __init__(self,drawingNum,account):
Thread.__init__(self)
self.drawingNum = drawingNum
self.account = account
self.expenseTotal = 0
def run(self):
if self.account.moneyself.drawingNum<0:
return
sleep(1) #判断完后阻塞。其他线程开始运行。
self.account.money -=self.drawingNum;
self.expenseTotal +=self.drawingNum;
print(f"账户:{self.account.name},余额是:{self.account.money}")
print(f"账户:{self.account.name},总共取了:{self.expenseTotal}")
if __name__ == '__main__':
a1 = Account(100,"gaoqi")
draw1 = Drawing(80,a1) #定义取钱线程对象;
draw2 = Drawing(80,a1) #定义取钱线程对象;
draw1.start() #你取钱
draw2.start() #你老婆取钱没有线程同步机制,两个线程同时操作同一个账户对象,竟然 从只有100元的账户,轻松取出80*2=160元,账户余额竟然成为了-60。这么大的问题,显然银行不会答应的。
我们可以通过“锁机制”来实现线程同步问题,锁机制有如下几个要点:
1、 必须使用同一个锁对象
2、 互斥锁的作用就是保证同一时刻只能有一个线程去操作共享数据,保证共享数据不会出现错误问题
3 、使用互斥锁的好处确保某段关键代码只能由一个线程从头到尾完整地去执行
4 、使用互斥锁会影响代码的执行效率
5、 同时持有多把锁,容易出现死锁的情况
互斥锁是什么?
互斥锁: 对共享数据进行锁定,保证同一时刻只能有一个线程去操作。
注意: 互斥锁是多个线程一起去抢,抢到锁的线程先执行,没有抢到锁的线程需要等待,等互斥锁使用完释放后,其它等待的线程再去抢这个锁。
threading 模块中定义了 Lock 变量,这个变量本质上是一个函数,通过 调用这个函数可以获取一把互斥锁。
【示例】多线程操作同一个对象(增加互斥锁,使用线程同步)
#encoding=utf-8
from threading import Thread,Lock
from time import sleep
class Account:
def __init__(self,money,name):
self.money = money
self.name = name
#模拟提款操作
class Drawing(Thread):
def __init__(self,drawingNum,account):
Thread.__init__(self)
self.drawingNum = drawingNum
self.account = account
self.expenseTotal = 0
def run(self):
lock1.acquire()
if self.account.moneyself.drawingNum<0:
return
sleep(1) #判断完后阻塞。其他线程开始运行。
self.account.money -= self.drawingNum;
self.expenseTotal += self.drawingNum;
lock1.release()
print(f"账户:{self.account.name},余额是:{self.account.money}")
print(f"账户:{self.account.name},总共取了:{self.expenseTotal}")
if __name__ == '__main__':
a1 = Account(100,"gaoqi")
lock1 = Lock()
draw1 = Drawing(80,a1) #定义取钱线程对象;
draw2 = Drawing(80,a1) #定义取钱线程对象;
draw1.start() #你取钱
draw2.start() #你老婆取钱1、acquire 和 release 方法之间的代码同一时刻只能有一个线程去操作
2、如果在调用 acquire 方法的时候 其他线程已经使用了这个互斥锁,那么此时 acquire 方法会堵塞,直到这个互斥锁释放后才能再次上锁。
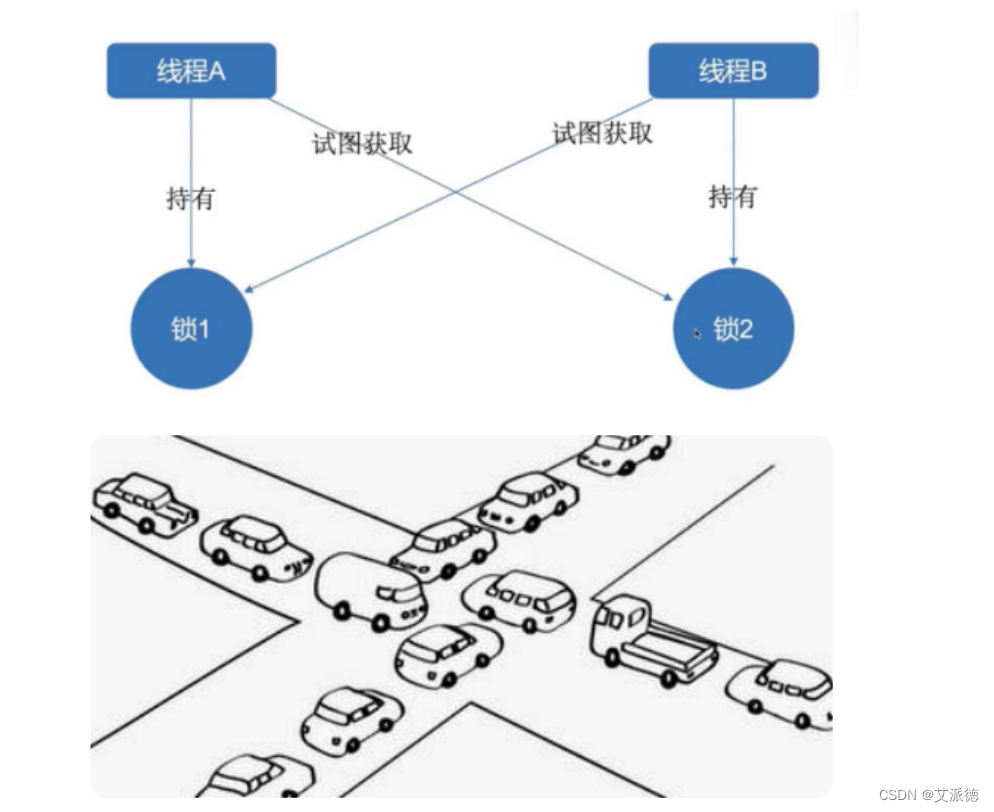
死锁
在多线程程序中,死锁问题很大一部分是由于一个线程同时获取多个锁造成的。举例: 有两个人都要做饭,都需要“锅”和“菜刀”才能炒菜。
from threading import Thread, Lock
from time import sleep
def fun1():
lock1.acquire()
print('fun1拿到菜刀')
sleep(2)
lock2.acquire()
print('fun1拿到锅')
lock2.release()
print('fun1释放锅')
lock1.release()
print('fun1释放菜刀')
def fun2():
lock2.acquire()
print('fun2拿到锅')
lock1.acquire()
print('fun2拿到菜刀')
lock1.release()
print('fun2释放菜刀')
lock2.release()
print('fun2释放锅')
if __name__ == '__main__':
lock1 = Lock()
lock2 = Lock()
t1 = Thread(target=fun1)
t2 = Thread(target=fun2)
t1.start()
t2.start()死锁的解决方法
死锁是由于“同步块需要同时持有多个锁造成”的,要解决这个问题,思路很简单,就是:同一个代码块,不要同时持有两个对象锁。
信号量(Semaphore)
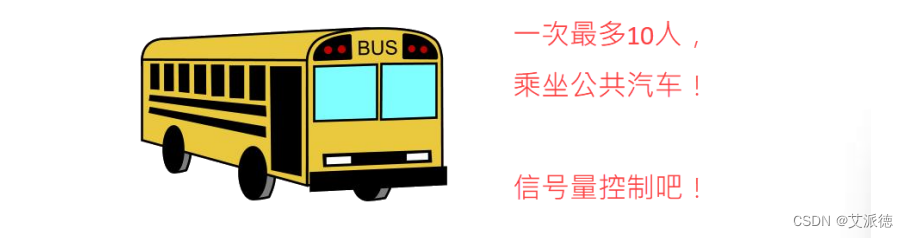
互斥锁使用后,一个资源同时只有一个线程访问。如果某个资源, 我们同时想让N个(指定数值)线程访问?这时候,可以使用信号量。 信号量控制同时访问资源的数量。信号量和锁相似,锁同一时间只允许一个对象(进程)通过,信号量同一时间允许多个对象(进程)通过。
应用场景
1、在读写文件的时候,一般只能只有一个线程在写,而读可以有多个线程同时进行,如果需要限制同 时读文件的线程个数,这时候就可以用到信号量了(如果用互斥锁,就是限制同一时刻只能有一个线程读取文件)。
2、在做爬虫抓取数据时。
底层原理
信号量底层就是一个内置的计数器。每当资源获取时(调用acquire) 计数器-1,资源释放时(调用release)计数器+1。
#coding=utf-8
from threading import Thread, Lock
from time import sleep
from multiprocessing import Semaphore
"""
一个房间一次只允许两个人通过
若不使用信号量,会造成所有人都进入这个房子
若只允许一人通过可以用锁-Lock()
"""
def home(name, se):
se.acquire() # 拿到一把钥匙
print(f'{name}进入了房间')
sleep(3)
print(f'******************{name}走出来房间')
se.release() # 还回一把钥匙
if __name__ == '__main__':
se = Semaphore(2) # 创建信号量的对象,有两把钥匙
for i in range(7):
p = Thread(target=home, args=(f'tom{i}', se))
p.start()
'''
执行结果:
tom0进入了房间
tom1进入了房间
******************tom1走出来房间
tom2进入了房间
******************tom0走出来房间
tom3进入了房间
******************tom2走出来房间
******************tom3走出来房间
tom4进入了房间
tom5进入了房间
******************tom5走出来房间
******************tom4走出来房间
tom6进入了房间
******************tom6走出来房间
Process finished with exit code 0
'''
事件(Event)
事件Event主要用于唤醒正在阻塞等待状态的线程;

原理
Event 对象包含一个可由线程设置的信号标志,它允许线程等待 某些事件的发生。在初始情况下,event 对象中的信号标志被设 置假。如果有线程等待一个 event 对象,而这个 event 对象的 标志为假,那么这个线程将会被一直阻塞直至该标志为真。一 个线程如果将一个 event 对象的信号标志设置为真,它将唤醒 所有等待个 event 对象的线程。如果一个线程等待一个已经被 设置为真的 event 对象,那么它将忽略这个事件,继续执行
Event() 可以创建一个事件管理标志,该标志(event)默认为False, event对象主要有四种方法可以调用:

【示例】Event事件对象经典用法
#coding:utf-8
#小伙伴们,围着吃火锅,当菜上齐了,请客的主人说:开
吃!
#于是小伙伴一起动筷子,这种场景如何实现
import threading
import time
def chihuoguo(name):
#等待事件,进入等待阻塞状态
print(f'{name}已经启动')
print(f'小伙伴{name}已经进入就餐状态!')
time.sleep(1)
event.wait()
# 收到事件后进入运行状态
print(f'{name}收到通知了.' )
print(f'小伙伴{name}开始吃咯!')
if __name__ == '__main__':
event = threading.Event()
# 创建新线程
thread1 = threading.Thread(target=chihuoguo, args=("tom", ))
thread2 = threading.Thread(target=chihuoguo, args=("cherry", ))
# 开启线程
thread1.start()
thread2.start()
time.sleep(10)
# 发送事件通知
print('---->>>主线程通知小伙伴开吃咯!')
event.set()
'''
执行结果:
tom已经启动
小伙伴tom已经进入就餐状态!
cherry已经启动
小伙伴cherry已经进入就餐状态!
---->>>主线程通知小伙伴开吃咯!
tom收到通知了.
小伙伴tom开始吃咯!
cherry收到通知了.
小伙伴cherry开始吃咯!
'''生产者和消费者模式
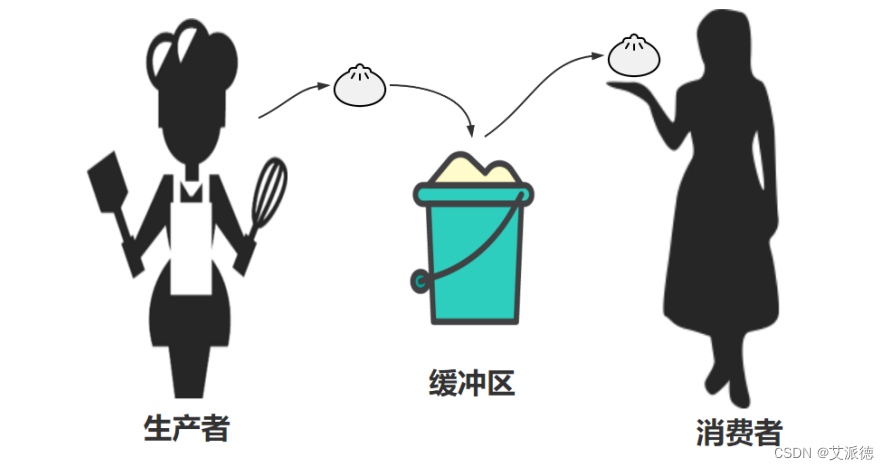
多线程环境下,我们经常需要多个线程的并发和协作。这个时候, 就需要了解一个重要的多线程并发协作模型“生产者/消费者模式”。

什么是生产者?
生产者指的是负责生产数据的模块(这里模块可能是:方法、对象、线程、进程)。
什么是消费者?
消费者指的是负责处理数据的模块(这里模块可能是:方法、对象、线程、进程)
什么是缓冲区?
消费者不能直接使用生产者的数据,它们之间有个“缓冲区”。生产 者将生产好的数据放入“缓冲区”,消费者从“缓冲区”拿要处理的数 据。
缓冲区是实现并发的核心,缓冲区的设置有3个好处:
1、 实现线程的并发协作
有了缓冲区以后,生产者线程只需要往缓冲区里面放置数据,而不需要管消费者消费的情况;同样,消费者只需要从缓冲区拿数据处理即可,也不需要管生产者生产的情况。 这样,就从逻辑上实现了“生产者线程”和“消费者线程”的分离。
2 解耦了生产者和消费者
生产者不需要和消费者直接打交道
3 解决忙闲不均,提高效率
生产者生产数据慢时,缓冲区仍有数据,不影响消费者消 费;消费者处理数据慢时,生产者仍然可以继续往缓冲区里 面放置数据
缓冲区和queue对象
从一个线程向另一个线程发送数据最安全的方式可能就是使用 queue 库中的队列了。创建一个被多个线程共享的 Queue 对象, 这些线程通过使用 put() 和 get() 操作来向队列中添加或者删除元素。 Queue 对象已经包含了必要的锁,所以你可以通过它在多个线程间 多安全地共享数据。
【示例】生产者消费者模式典型代码
#coding=utf-8
from queue import Queue
from threading import Thread
from time import sleep
def producer():
num = 1
while True:
if queue.qsize() < 5:
print(f'生产:{num}号,大馒头')
queue.put(f'大馒头:{num}号')
num += 1
else:
print('馒头框满了,等待来人消费啊!')
sleep(1)
def consumer():
while True:
print(f'获取馒头:{queue.get()}')
sleep(1)
if __name__ == '__main__':
queue = Queue()
t = Thread(target=producer)
t.start()
c = Thread(target=consumer)
c.start()
c2 = Thread(target=consumer)
c2.start()
'''
执行结果:
生产:1号,大馒头
获取馒头:大馒头:1号
生产:2号,大馒头
获取馒头:大馒头:2号
生产:3号,大馒头
获取馒头:大馒头:3号
生产:4号,大馒头
获取馒头:大馒头:4号
...
'''















 1223
1223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









