






Sora学习笔记 1
From Datawhale & 魔搭社区
Sora技术原理解析
01 Sora能力边界探索
-
Advantage
- 最大支持60秒高清视频 (时间)
- 短视频前后扩展及人物/场景高度一致 (延申)
- 视频融合 (包含于改变原视频风格、场景)
- 动态摄影机:3D空间人及场景的一致移动
- 分辨率+宽高比 任意
- Bonus:Text to image 文生图很棒 (size)
- Simulate virtual world
-
Dis
- 对物理规律理解有限
技术报告分析:
Ambition: Building general purpose simulators of the phyisical world!
02 Sora模型训练流程
Sora是一个在不同时长、分辨率和宽高比的视频及图像上训练而成的扩散模型,同时采用了Transformer架构
一图看懂Sora模型训练流程
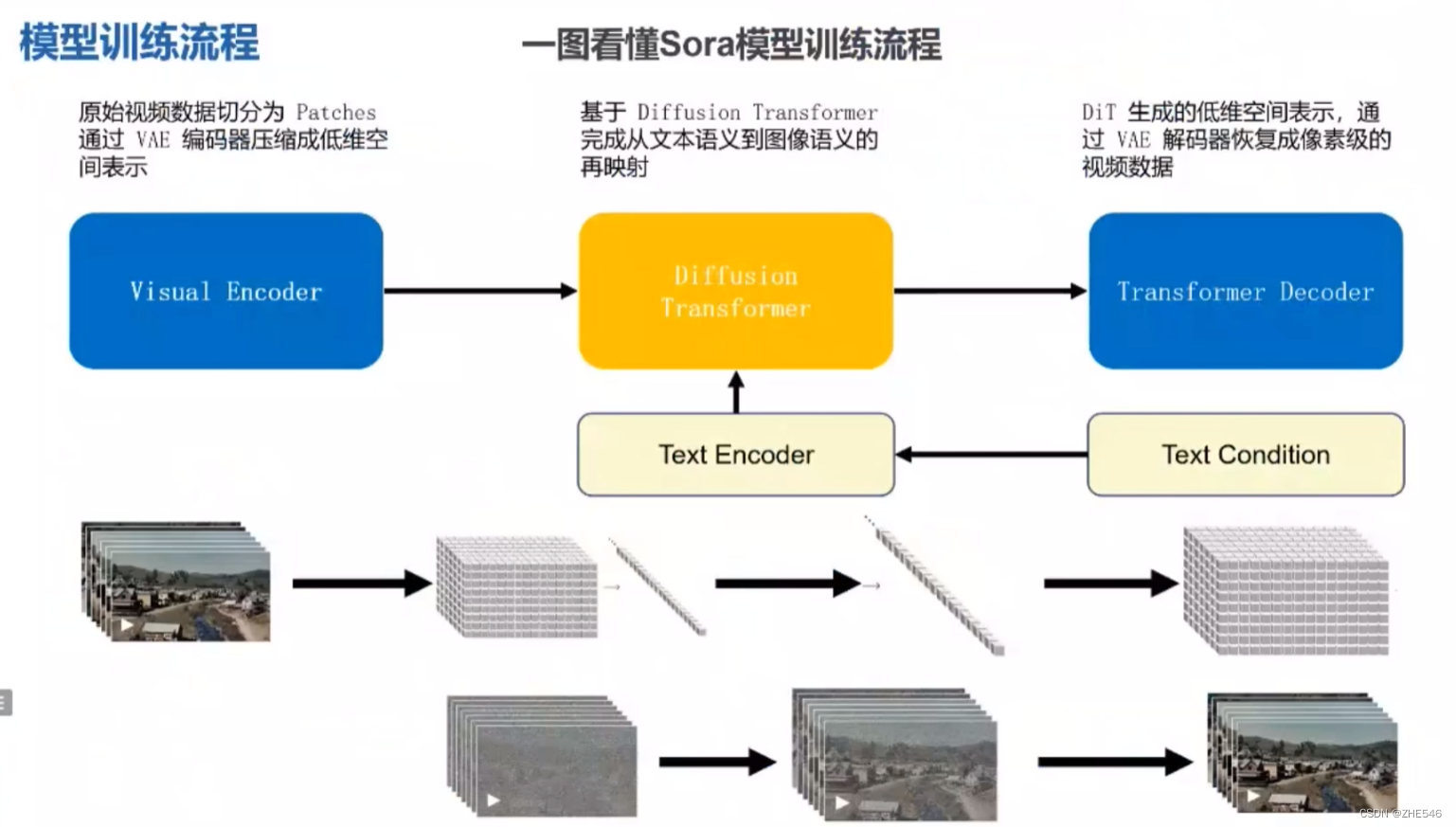
-
3 Parts
Visual Encoder:视频解码器。旨在切分原始视频数据为patches,通过VAE编码器压缩成低维空间(最后:一维向量)表示
类比 token
Diffusion Transformer (DiT): 扩散模型Transformer架构。从文本语义到图像语义的再映射。
Prompt 到图片映射,一起变成向量,喂给模型学习
Transformer Decoder: VAE解码器恢复低维空间为像素级视频数据
-
Transforming Visual Data into Patches
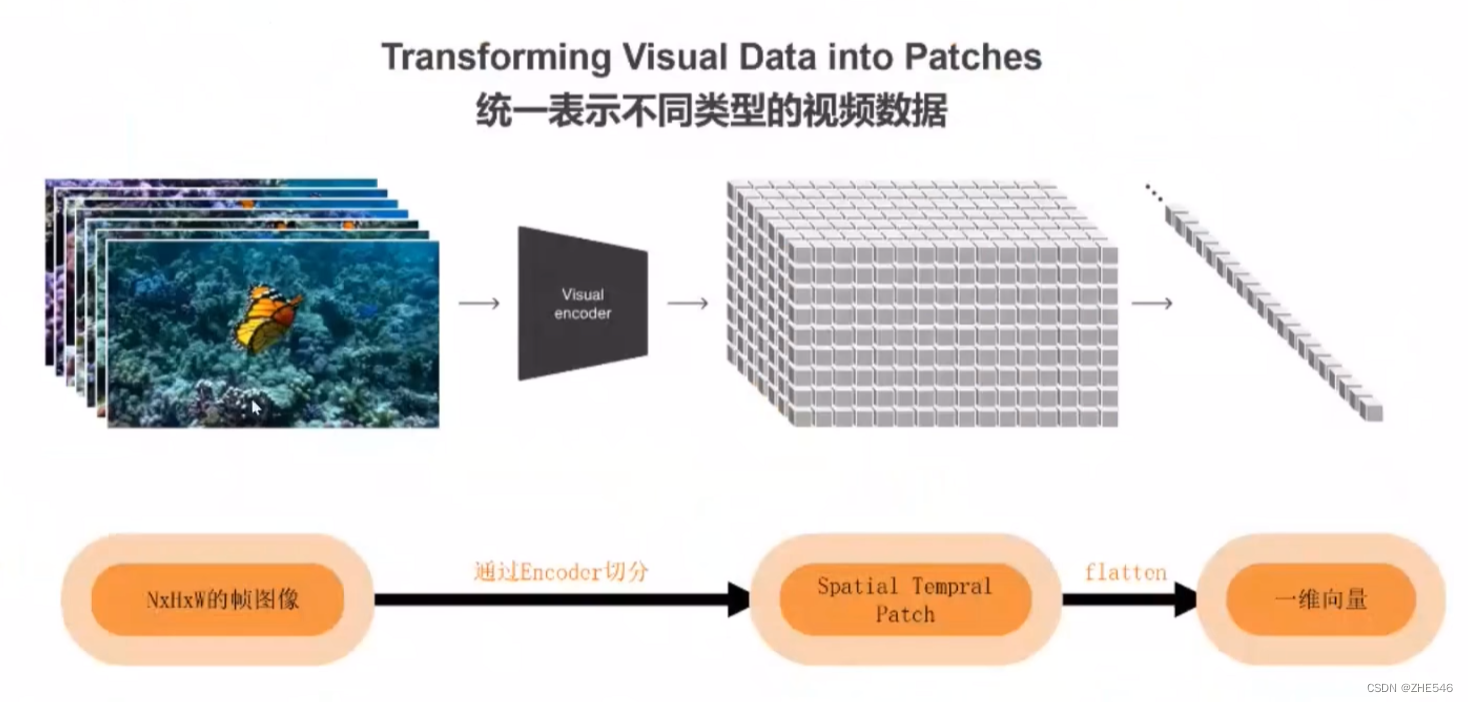
NxHxW的帧图像 — Encoder切分 —> Spatial tempral patch — flatten —> 一维向量
patch包含时空信息
一维向量减少计算开销
简单介绍Diffusion模型及延申至Sora原理
-
Diffusion:
Diffusion模型是一类深度生成模型,用于生成高质量的、结构化的数据,如图像、音频和文本。它们通过模拟一个逐步的去噪过程来生成数据,该过程从一个随机噪声分布开始,逐步转换成具有清晰结构的数据分布。这种模型的工作原理与自然界中的扩散过程类似,因此得名“Diffusion”。
Diffusion模型的工作过程分为两个主要阶段:首先是扩散(前向过程),其中模型逐渐将噪声加入数据直至完全或部分变为噪声状态,这一过程是预设的且无需学习;随后是反扩散(生成过程),在此阶段,模型通过学习如何从噪声数据中去除噪声,逐步恢复出清晰、有结构的原始数据,这一过程通过迭代重构,每步使数据更清晰,直至生成高质量输出。
例子:红墨水扩散
-
DDPM:
DDPM(Denoising Diffusion Probabilistic Models)是一类基于扩散过程的生成模型,利用了一系列的概率分布变换,通过模拟扩散过程(即逐渐引入噪声到数据中)和反扩散过程(即逐渐从噪声数据中恢复出原始数据)来生成数据。
在训练过程中,DDPM学习的是在给定噪声数据的条件下,如何预测原始数据的分布。这通常通过最小化某种形式的损失函数来实现。
-
U-Net:
Backbone 限制规格,不会膨胀。原先的SD模型中,在其反扩散过程中,U-Net起到去噪的作用,它从随机噪声中逐步恢复出与文本描述相匹配的图像。
该模型因其独特的“U”形结构而得名,这种结构有效地捕捉图像的上下文信息和细节信息,使其在图像分割领域特别有效。
主要特点:
对称结构:U-Net的结构分为两部分,一部分是收缩路径(下采样),用于捕获图像的上下文信息;另一部分是扩展路径(上采样),用于精确定位图像的细节信息。这两部分形成了一个“U”字形状。
跳跃连接(Skip Connections):在扩展路径中,来自收缩路径的特征图与上采样的特征图在通道维度上进行拼接。这些跳跃连接允许模型在上采样过程中利用更丰富的上下文信息,有助于恢复图像的细节。通过跳跃连接,U-Net可以有效地将低层次的特征(如边缘信息)直接传递到高层次,从而在进行图像分割时保持更多的细节信息。
-
基本只有生成网络主体U-net换成了Transformer
03 关键技术拆解
-
Vision Transformeer ViT:
ViT尝试将标准Transformer结构直接应用于图像
图像被划分为多个patch后,将二维patch转换为一维向量作为Transformer的输入
介绍
ViT(Vision Transformer)是一种应用于计算机视觉任务的深度学习模型,它将Transformer架构——最初设计用于处理自然语言处理(NLP)任务——成功应用于图像识别领域。ViT的提出标志着从传统的卷积神经网络(CNN)向Transformer架构的重要转变,在图像处理任务中取得了显著的成绩。
工作原理
ViT通过将输入图像切割成多个小块(称为patches),然后将这些patches线性嵌入到一个高维空间中,并加入位置编码以保持空间信息。这些嵌入随后被送入一个标准的Transformer模型中进行处理。Transformer的自注意力(Self-Attention)机制允许模型捕捉patches之间的复杂关系.
代码实现
Einops库:Link
ViViT:
ViViT处理视频数据的方式融合了创新性技术,首先通过空间-时间块切割技术将视频分割成小的空间-时间块,每个块不仅携带了空间上的信息,还包含了时间维度的动态信息,允许模型捕捉视频的运动和变化。接着,这些块经过三维嵌入转换为高维表示,并加入位置编码,确保了空间位置和时间顺序的信息得以保留。最后,通过空间-时间自注意力机制,ViViT深入分析这些嵌入,让模型能够全面理解视频内帧间的动态关系及帧内的细节,从而有效地支持视频分类、动作识别等复杂的视频理解任务。
-
理解时空编码:Spacetime latent patches
摊大饼法:
从输入视频剪辑中均匀采样
n t n_t </span><span class="katex-html"><span class="base"><span class="strut" style="height: 0.5806em; vertical-align: -0.15em;"></span><span class="mord"><span class="mord mathnormal">n</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height: 0.2806em;"><span class="" style="top: -2.55em; margin-left: 0em; margin-right: 0.05em;"><span class="pstrut" style="height: 2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">t</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height: 0.15em;"><span class=""></span></span></span></span></span></span></span></span></span></span>个帧,使用与ViT相同的方法独立地嵌入<strong>每个2D帧</strong>(embed each 2D frame independently using the same method as ViT),并将所有这些token连接在一起。</p> <p><strong>切块法:</strong></p> <p>将输入的视频划分为若干tuplet**,每个tuplet会变成一个token**<br> 经过Spatial Temperal Attention进行空间/时间建模获得有效的视频表征token,即上图灰色block</p> </li><li> <p><strong>支持不同长度、分辨率的输入</strong></p> <p>NaViT:多个patches打包成一个单一序列实现可变分辨率</p> <p>使用不同分辨率、不同时长的视频进行训练保证推理时在不同长度和分辨率上的效果</p> <p>带来大量的计算负载不均衡</p> <p>可能使用Google的NaVit相关技术降低计算量支持动态输入</p> </li></ul>
技术难点
视频压缩网络类比于Latent Diffusion Model中的VAE
但压缩率是多少,Encoder的复杂度、时空交互的range还需要进一步的探索和实验
-
DiT:
D i T = V A E DiT = VAE </span><span class="katex-html"><span class="base"><span class="strut" style="height: 0.6833em;"></span><span class="mord mathnormal" style="margin-right: 0.0278em;">D</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right: 0.1389em;">T</span><span class="mspace" style="margin-right: 0.2778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right: 0.2778em;"></span></span><span class="base"><span class="strut" style="height: 0.6833em;"></span><span class="mord mathnormal" style="margin-right: 0.2222em;">V</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right: 0.0576em;">E</span></span></span></span></span> <span class="katex--inline"><span class="katex"><span class="katex-mathml"> e n c o d e r + V i T + D D P M + V A E encoder +ViT+DDPM +VAE </span><span class="katex-html"><span class="base"><span class="strut" style="height: 0.7778em; vertical-align: -0.0833em;"></span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">co</span><span class="mord mathnormal">d</span><span class="mord mathnormal" style="margin-right: 0.0278em;">er</span><span class="mspace" style="margin-right: 0.2222em;"></span><span class="mbin">+</span><span class="mspace" style="margin-right: 0.2222em;"></span></span><span class="base"><span class="strut" style="height: 0.7667em; vertical-align: -0.0833em;"></span><span class="mord mathnormal">Vi</span><span class="mord mathnormal" style="margin-right: 0.1389em;">T</span><span class="mspace" style="margin-right: 0.2222em;"></span><span class="mbin">+</span><span class="mspace" style="margin-right: 0.2222em;"></span></span><span class="base"><span class="strut" style="height: 0.7667em; vertical-align: -0.0833em;"></span><span class="mord mathnormal" style="margin-right: 0.0278em;">DD</span><span class="mord mathnormal" style="margin-right: 0.109em;">PM</span><span class="mspace" style="margin-right: 0.2222em;"></span><span class="mbin">+</span><span class="mspace" style="margin-right: 0.2222em;"></span></span><span class="base"><span class="strut" style="height: 0.6833em;"></span><span class="mord mathnormal" style="margin-right: 0.2222em;">V</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right: 0.0576em;">E</span></span></span></span></span></p> <p><strong>旨在</strong>解决传统Vision Transformer(ViT)模型在处理图像任务时对<strong>大量训练数据</strong>的依赖问题。通过改进模型架构和训练策略,DiT能够在较少的数据上也实现良好的性能,使其更适用于数据受限的应用场景。</p> <p><strong>核心特点</strong>在于其显著提高的数据效率,通过对架构和训练方法的创新优化,减少了对大量训练数据的依赖,使其能在更小的数据集上也展现出强大的性能。这种优化包括但不限于<strong>引入知识蒸馏、参数共享和改进的注意力机制</strong>等技术,旨在更有效地捕捉和利用图像数据中的信息。</p> <p><strong>步骤:</strong></p>
-
DiT首先将将每个patch空间表示Latent输入到第一层网络,以此将空间输入转换为tokens序列。
-
将标准基于ViT的Patch和Position Embedding应用于所有输入token,最后将输入token由Transformer处理。
-
DiT还会处理额外信息,e.g.时间步长、类别标签、文本语义等。
技术难点:
训练数据很重要,具体怎么构建?
Transformer Scale up到多大?
从头训练到收敛的trick?
如何实现Long Context(长达1分钟的视频)的支持 -> 切断+性能优化
如何保证视频中实体的高质量和一致性?
-
DALLE 2
核心特点在于可以通过简单的文本描述生成高分辨率、高质量的图像。这种模型不仅可以理解复杂和具体的文本指令,将它们转化为视觉作品,而且还展现了卓越的创意表现力,能够在生成的图像中融入抽象概念和多样风格。此外,DALL·E 2具备编辑现有图像的能力,可以根据用户指令进行图像的修改或增添新元素,进一步扩展了其应用范围。
S:
-
将文本提示输入文本编码器,该训练过的编码器便将文本提示映射到表示空间
-
先验模型将文本编码映射到图像编码,图像编码捕获文本编码中的语义信息
-
图像解码模型随机生成一幅从视觉上表现该语义信息的图像
-
04 个人思考与总结
-
算力需求增长
对算力需求增长如何? 如LLM在服务器形态爆发? 推理生产应用端爆发增长?
- SORA模型参数量预计<30B,模型参数量不会像LLM需要干卡/万卡大规模AI集群训练(百卡);
- DALL·E3视频文本标注数据有限(<30B),训练数据不像LLM可以无监督学习;
- OpenAI尚未公布SORA商业化时间,视频生成距离成熟还有时间距离(<半年);
- 目前推理算力比SD、SDXL要大2/3个量级,需要结合AI 训练集群或者AI推理集群;
- LLM大语言模型仍然是2024年消耗算力大头,多模态很多工作建立在语言之上;
Q: 一分钟长度、每秒30帧的视频,平均每帧包含256个token,总计将产生460k token。以34B模型(这里只是一个猜测),需要7xA100资源推理。
Dit XI.输入512x512, 训练使用一个TPU V3-256 Pod,按照TFLOPS换算约等于105个A100。那么 Sora需要的训练和微调的资源会是多少?
A:训练需要200-400张A100
调练时间2-3个月
-
技术总结
-
Scaling Law: 模型规模的增大对视频生成质量的提升具有明确意义,从而很好地解决视频一致性、连续性等问题;
-
Data Engine: 数据工程很重要,如何设计视频的输入(e.g.是否截断、长宽比、像素优化等)、patches的输入方式、文本描述和文本图像对质量;
Al Infra: AI系统(AI框架、AI编译器、AI芯片、大模型)工程化能力是很大的技术壁垒,决定了Scaling的规模。
-
LLM: LLM大语言模型仍然是核心,多模态(文生图、图生文)都需要文本语义去牵引和约束生成的内容,CLIP/BLIP/GLIP等关联模型会持续提升能力;
-
-















 2195
2195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









