






10.2 BERT的预训练与微调
BERT模型的训练过程分为两个主要阶段:预训练和微调。通过这两个阶段的训练,BERT能够学到通用的语言表示,并在多种下游任务上表现优越。微调阶段允许模型根据具体任务的需求进行定制,而预训练阶段提供了一个通用的语境感知的基础。这种两阶段的训练策略使得BERT具有强大的迁移学习能力。
10.2.1 预训练
在BERT模型的预训练阶段主要实现了两个主要任务,即掩盖语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)。
1. 掩盖语言模型(MLM)
- 任务描述:在输入文本中,随机选择一些词汇,并将它们替换为特殊的"[MASK]"标记。模型的任务是根据上下文预测这些被掩盖的词的原始内容。
- 目的:这个任务使得模型必须在考虑上下文的情况下填补被掩盖的词,从而迫使模型学会理解词汇的双向上下文关系,这有助于捕捉长距离依赖和更全面的语境信息。
2. 下一句预测(NSP)
- 任务描述:模型接收两个句子的输入,这两个句子可能是文本中相邻的。模型的任务是判断这两个句子是否是原始文本中的相邻句子。
- 目的:通过这个任务,模型可以学到文本之间的关系,尤其是在处理自然语言推断等任务时。模型需要理解文本的语境,以确定两个句子之间是否存在逻辑或语义关系。
在实际实施中,BERT的预训练过程通过多次迭代这两个任务来进行。对于每个任务,使用随机抽样的文本创建批次,并根据任务目标计算损失,然后使用反向传播和优化算法来更新模型参数。
注意:BERT的预训练采用无监督学习方法,因此无需标注的标签。这种预训练过程使BERT能够学到通用的语言表示,从而在下游任务中能够更好地泛化和适应。预训练模型可以通过微调(fine-tuning)在特定任务上进行调整,以适应特定任务的数据和标签。这种两阶段的训练策略使得BERT成为一种强大的迁移学习工具。
10.2.2 微调
微调(fine-tuning)是使用已经预训练好的模型,在特定任务上进行额外的训练以适应该任务的过程。对于BERT模型,微调通常包括将预训练的BERT模型与任务特定的输出层结合,并使用标记好的任务数据进行有监督学习。在实际应用中,对BERT模型进行微调的基本步骤如下所示。
(1)准备数据集:为了微调BERT模型,需要有一个标记好的数据集,其中包含了输入文本和相应的标签。这个数据集应该与你的任务相关,例如文本分类、命名实体识别等。
(2)加载预训练的BERT模型
- 选择预训练模型:选择与任务相关的预训练模型,例如bert-base-uncased。
- 加载模型:使用Hugging Face Transformers库或其他相应的工具加载预训练的BERT模型。当然,也可以选择不同规模的BERT模型,具体取决于你的任务和计算资源。
(3)修改模型结构,调整输出层:针对特定任务,修改BERT模型的输出层以适应任务的标签数。例如,对于文本分类任务,最后的线性层的输出单元数应与类别数相匹配。
(4)创建 DataLoader,分批处理:将标记好的数据集加载到PyTorch或TensorFlow的DataLoader中,以便进行批处理。
(5)设置优化器和损失函数
- 优化器:选择优化器,常见的有AdamW等。
- 损失函数:根据任务选择损失函数,例如交叉熵损失函数。
(6)微调过程:
训练循环:使用微调数据集进行多轮的训练循环。在每个小批次中,将输入数据传递给模型,计算损失,进行反向传播并更新模型参数。
梯度截断:为了防止梯度爆炸,可以进行梯度截断,即在反向传播前裁剪梯度的大小。
(7)评估微调模型,评估验证集:使用验证集评估微调后的模型性能。根据任务选择适当的指标,例如准确率、精确度、召回率等。
(8)保存微调后的模型:将微调后的模型保存,以备在测试集上进行推断。
(9)调整超参数(学习率、批量大小等):可以使用验证集进行超参数的搜索和调整工作,以优化微调性能。
(10)测试微调后的模型:在测试集上评估微调后的模型性能,以获取最终的性能指标。
注意:在具体实践中,微调BERT模型可能需要一定的计算资源和时间,但通常可以为特定任务提供出色的性能,尤其是在自然语言处理领域。
例如下面是一个使用库Hugging Face Transformers微调BERT模型的一个例子,在这个例子中,使用一个二分类任务(情感分类)来展示实现微调的过程。
实例10-1:使用库Hugging Face Transformers微调BERT模型(源码路径:daima\10\wei.py)
实例文件wei.py的具体实现代码如下所示。
-
import torch
-
from transformers
import BertTokenizer, BertForSequenceClassification, AdamW
-
from torch.utils.data
import DataLoader, TensorDataset
-
-
# 载入已经预训练好的BERT模型和分词器
-
model = BertForSequenceClassification.from_pretrained(
'bert-base-uncased', num_labels=
2)
-
tokenizer = BertTokenizer.from_pretrained(
'bert-base-uncased')
-
-
# 伪造一些微调数据
-
sentences = [
"This is a positive sentence.",
"This is a negative sentence."]
-
labels = [
1,
0]
-
-
# 使用分词器对文本进行处理
-
tokenized_input = tokenizer(sentences, padding=
True, truncation=
True, return_tensors=
"pt")
-
-
# 创建PyTorch DataLoader
-
dataset = TensorDataset(tokenized_input[
'input_ids'], tokenized_input[
'attention_mask'], torch.tensor(labels))
-
loader = DataLoader(dataset, batch_size=
1, shuffle=
True)
-
-
# 设置优化器和损失函数
-
optimizer = AdamW(model.parameters(), lr=
5e-5)
-
criterion = torch.nn.CrossEntropyLoss()
-
-
# 微调模型
-
model.train()
-
for epoch
in
range(
5):
-
for batch
in loader:
-
inputs, attention_mask, label = batch
-
optimizer.zero_grad()
-
outputs = model(inputs, attention_mask=attention_mask, labels=label)
-
loss = outputs.loss
-
loss.backward()
-
optimizer.step()
-
-
# 保存微调后的模型
-
model.save_pretrained(
"fine_tuned_bert_model")
-
tokenizer.save_pretrained(
"fine_tuned_bert_model")
上述代码实现了对BERT模型进行微调的过程,具体实现流程如下所示。
- 加载预训练的BERT模型和分词器:通过Hugging Face Transformers库,使用预训练的BERT模型('bert-base-uncased')和相应的分词器(BertTokenizer)。
- 伪造微调数据:提供两个样本的文本和相应的标签,其中一个被标记为正面(1),另一个被标记为负面(0)。
- 使用分词器处理文本:将提供的文本使用BERT分词器进行处理,包括将文本转换为输入模型的格式,进行填充和截断等操作。
- 创建PyTorch DataLoader:将处理后的数据集包装成PyTorch DataLoader,以便于进行批处理。
- 设置优化器和损失函数:使用AdamW优化器,以及交叉熵损失函数(CrossEntropyLoss)来计算模型预测与实际标签之间的损失。
- 微调模型:在5个训练轮次内,通过迭代 DataLoader 中的批次数据,将模型参数更新以最小化损失。
- 保存微调后的模型:将微调后的BERT模型和分词器保存到文件,以备后续在测试集或实际应用中使用。
1. 模型名称bert-base-uncased
在上述代码中,'bert-base-uncased' 库Hugging Face Transformers中的一个预训练的BERT模型的名称,这个名称用于指定加载的预训练模型,具体说明如下所示。
- "bert":表示这是一个BERT模型。
- "base":表示这是基础版本,通常包含较少的层和参数。有时还可以看到 "large" 等表示更大规模的模型。
- "uncased":表示模型是在不区分大小写的文本上进行了预训练。如果使用 "cased",则表示预训练时保留了大小写信息。
这种命名约定帮助用户轻松选择不同规模和配置的预训练模型。其他常见的模型名称包括 "bert-large-uncased"、"bert-base-cased" 等。在微调或使用预训练模型时,选择适合任务和资源要求的模型非常重要。
2. num_labels 参数
在BERT模型中,num_labels 参数用于指定模型要处理的类别数量。通常,这个参数在微调阶段用于适应任务的特定需求,尤其是针对分类任务。对于二分类任务(例如情感分类、垃圾邮件检测等)来说,将num_labels参数设置为2,表示模型需要输出两个类别的预测结果。通常,这两个类别是二进制的,比如正类别和负类别,或者类别1和类别0。
在微调的过程中,模型的最后一层(输出层)会根据这个 num_labels 参数的设置调整权重,以确保适应特定任务的输出要求。这样,微调后的模型就能够产生与任务相关的预测结果。
在本实例的代码中,num_labels=2 意味着这是一个用于处理二分类任务的BERT模型。如果你的任务是一个多分类问题,需要将 num_labels 设置为相应的类别数量。例如,如果有3个类别,可以将 num_labels 设置为3。
总体而言,本实例实现了一个简单的BERT模型微调过程,用于一个二分类任务的情感分类。执行后会创建"fine_tuned_bert_model"目录,如图10-1所示。
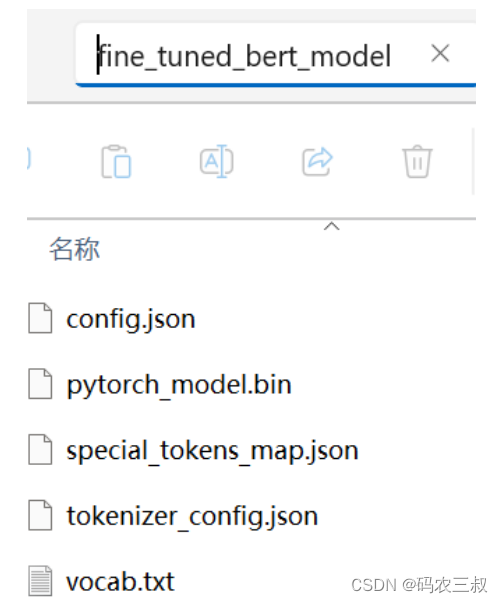
图10-1 "fine_tuned_bert_model"目录
在"fine_tuned_bert_model"目录中包含了微调后的BERT模型的相关文件,这些文件通常是Hugging Face Transformers库默认的模型保存结构,其中包括了模型的权重、配置信息、词汇表等。各个文件的具体化锁门如下所示。
- 文件config.json:包含了模型的配置信息,例如模型的层数、隐藏层维度等。这是模型架构的描述文件。
- 文件pytorch_model.bin:包含了微调后的BERT模型的权重参数。这个文件保存了模型在微调阶段学到的权重。
- 文件special_tokens_map.json:包含了特殊标记的映射关系,如"[CLS]"、"[SEP]"等。
- 文件tokenizer_config.json:包含了分词器的配置信息,描述了分词器的工作方式和设置。
- 文件vocab.txt:包含了模型使用的词汇表,其中包括了所有可能的词汇和对应的编号。
这些文件共同构成了一个完整的BERT模型,可以在以后的推理阶段或者在其他任务中使用。例如,可以使用这个微调后的BERT模型来进行文本分类、命名实体识别等任务。在使用时,可以通过加载这些文件来还原微调后的BERT模型。















 6347
6347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









