







|company:小红书;
|stage:Re-rank;
|model:SDD;
前言
本次要分享的是小红书在2021KDD上发表的工业推荐论文——”“Sliding Spectrum Decomposition for Diversified Recommendation“。文章提出的模型滑动频谱分解(Sliding Spectrum Decomposition,SSD)模型应用在工业推荐的重排阶段,加入了信息流推荐中滑动窗口的考虑,最主要的目的还是为了平衡推荐的质量与多样性,对标Hulu以及Youtube的DPP优化模型。
目录:
需要解决的问题与解决的方法;
SSD模型的介绍(包含模型、MAP inference);
CB2CF模型的介绍(为了SSD模型服务,提供item embedding);
实验(离线与A/B测试);
总结;
注: 本篇文章公式比较多,并且需要一些代数、几何的知识,而且需要了解DPP模型,如果想要了解的透彻,建议搭配原文以及额外资料进行浏览。
1. 挑战与创新
小红书主要的推荐场景是首页的Feeds流推荐,由于手机等设备的限制,需要滑动屏幕窗口来更新推荐的内容。在信息流推荐中,虽然当前窗口展示的内容用户印象很深,但由于用户总体的浏览长度较长(参考对每个用户平均曝光序列的长度,下图),之前浏览过的内容用户也有一定的记忆性。因此,作者指出了之前重排阶段其他方法的第一个缺陷:DPP模型只考虑当前窗口的一个多样性,忽略了历史的内容对用户多样性的体验(简单来说,DPP认为窗口就是设备的真实大小,而小红书认为窗口应该是用户临时记忆中的大小)。在推荐领域中,长尾效应是普遍存在的,那么第二个缺陷是:重排阶段的模型,例如DPP,都需要内容的Embedding向量来计算相似度分数。但是由于长尾效应,很多内容的交互行为是很稀疏的,因此通过CF(矩阵分解)等方法得到的Embedding向量进行相似度度量效果比较差。
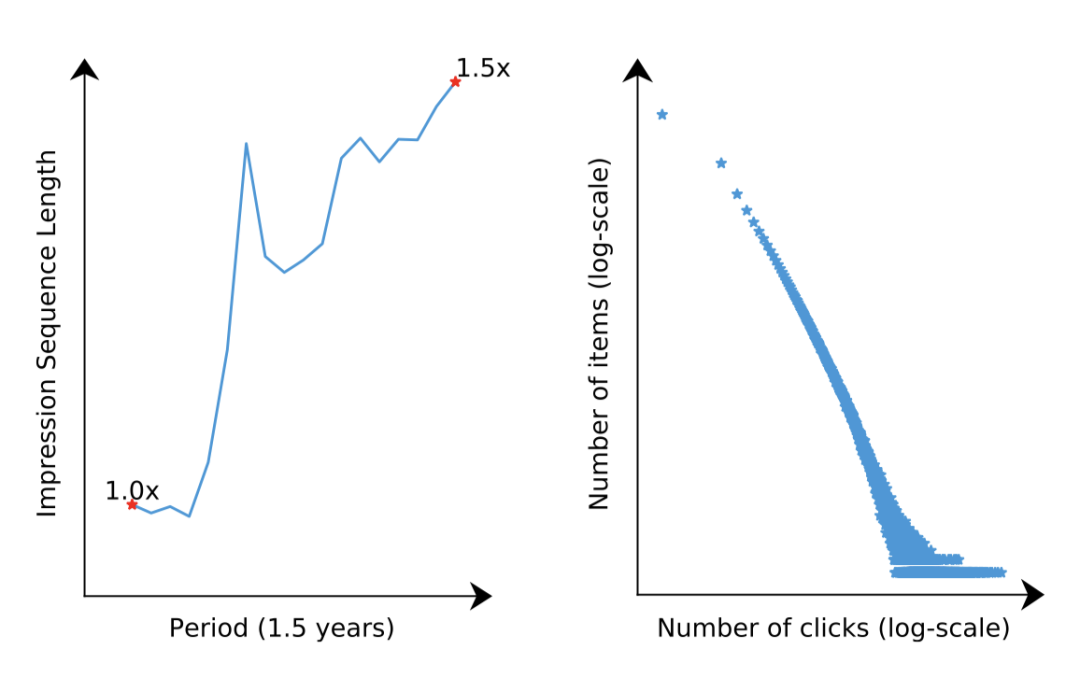
针对上述问题,
第一个缺陷,扩大窗口大小是不可取的,因为这会阻碍线上的延迟要求。作者认为可以利用时间序列技术从物品序列的角度来看待多样性推荐问题,所以提出了滑动频谱分解(SSD)方法,将当前窗口的内容与窗口外的内容都考虑进来完成多样性推荐。
第二个缺陷,基于内容的推荐(CB)也是不可取的,因为训练时某些标签是标注者的看法,并不是用户真正的观点。所以,作者设计了一个策略,将CB与CF相结合,即标签采用CF的方法收集,特征采用CB的内容,来学习item embedding,用于SSD模型。
2. SSD
模型最终的目标是在重排阶段构建一个高质量和多样化的物品推荐序列。以下分为三部分内容:
提出SSD模型,主要是为了公式化优化目标:如何从排序给出的候选物品集去挑选当前最适合的物品(内容质量与多样性的综合考虑);
有了模型,还需要最大化后验推理来计算得到最终的推荐物品集,作者针对重排的低延迟要求,提出一个高效的SSD贪心推理方法;
SSD方法与DPP复杂度的比较;
2.1 模型
如何量化所需要的目标?可以将其拆解为两个小问题:
如何在长序列中衡量多样性?
如何综合考虑质量与多样性来构建这个目标?【trade-off】
对于第一个问题,我们可以从用户的角度来分析物品的顺序。信息流推荐通常提供一个长序列物品,用户当前的查看窗口只能占据整个序列的一部分。由于用户不断浏览条目,因此很自然地将信息流视为用户观察到的时间序列。所以我们可以将用户随时间步变化在窗口(滑动窗口)中浏览的物品变化过程转化为一个轨迹张量,如下图所示:
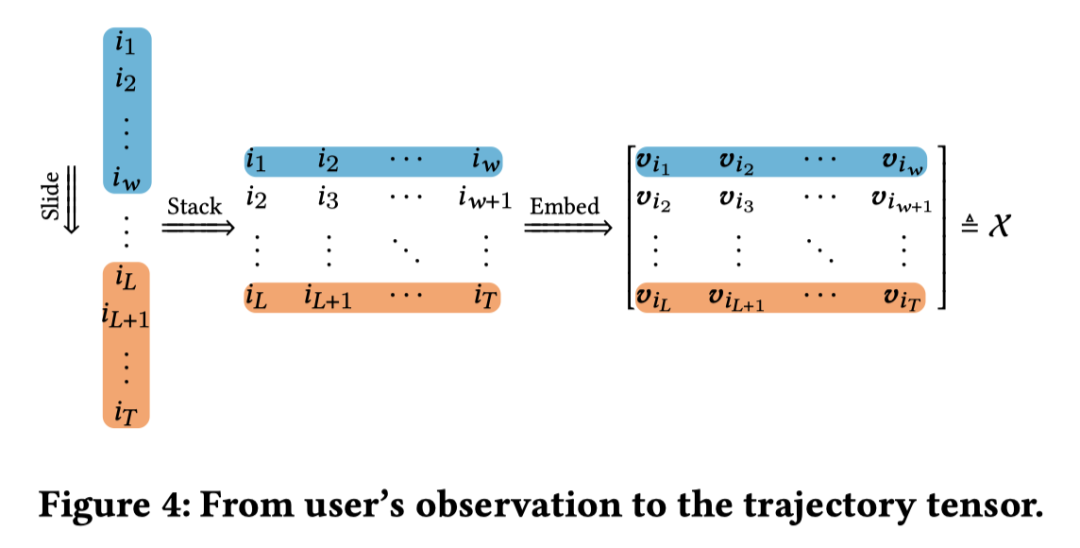
具体的轨迹张量:
其中,为浏览的总长度,为物品的Embedding向量维度大小。
如果,正是单变量时间序列奇异谱分析(singular spectrum analysis,SSA)中的轨迹矩阵。
❝重要:
奇异谱分析(Singular Spectrum Analysis, SSA)是一种将时间序列分解为各种正交分量的技术,这些分量的权重通过对轨迹矩阵的奇异值分解来表示。 奇异谱分析主要包括四个步骤:嵌入(构造轨迹矩阵)—分解(奇异值分解)—分组(对奇异值分组,使得对应的子矩阵不相关)—重构。[1]
❞
在推荐中,轨迹矩阵是一个三阶张量。通过SSA,分解的奇异值为:
其中是的正交分解矩阵的向量,表示外积。
❝公式(1)的分解涉及到了奇异值分解,张量的CP分解(Canonical Polyadic Decomposition)[2, 3]。
首先假设矩阵,对其进行奇异值分解,
其中是阶正交矩阵,是阶正交矩阵,是由按序排列的非负的对角线元素组成的矩形对角矩阵,如下图所示。
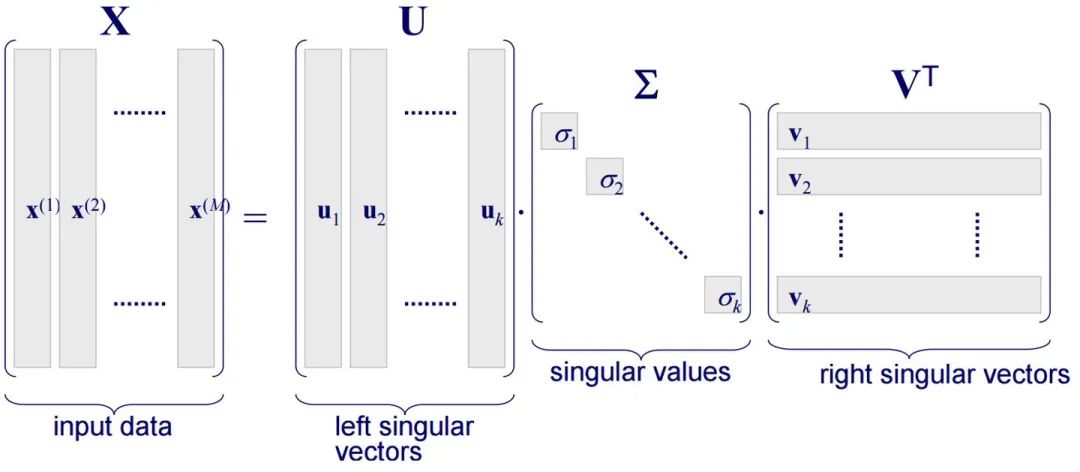
我们不妨换一种角度看待奇异值分解,取出的第一个向量,的第一个向量,两者作外积为一个矩阵,那么对应的奇异值可以理解为该矩阵在原始矩阵所占的权重。以此类推,将这些带权矩阵加起来,就可以得到原始矩阵:
其中为的秩,即非零奇异值的数量(大于0)。
此时我们将矩阵扩展为张量(以三阶为例),那么CP分解就是将张量分解为个秩为1的张量(秩一张量)和的形式,即:
为秩,CP分解如下图所示:
❞
关键:在推荐领域中,可以将每个正交分量看作是物品内容所呈现的正交方向,奇异值即为这些方向在用户感知中多样性的权重。
我们该如何定义分解下的多样性?
首先考虑简单的情况,即窗口没有重叠,计算多样性时都是独立的。所以只需要考虑张量的每一行,从张量--->矩阵(只考虑两个物品之间的多样性即可)。作者认为由于物品的embedding向量是定义在内积空间中,那么两个物品的内积可以表示两者的相似度。就很自然的定义多样性由物品向量张成的平行六面体体积(两个物品向量,其实就是平行四边形的面积,多样性可以理解为毫不相关)。物品之间越不相关,所构成的体积越大,因为它们的embedding向量更加正交(正交向量的内积为0)。又有资料[4]表示volume的计算方法之一可以用奇异值累积表示,所以有
❝注:上述的内容论文的跳跃实在太大了,多样性的转换定义一点都不自然,需要自己了解Determinants and Volumes,即行列式与几何中平行六面体体积的关系,参考[5]。
❞
此时,将多个窗口结合在一起,那么的体积(volume)代表了基于整个序列以及滑动窗口的多样性。因此,我们通过公式(2)定义整个序列的多样性,作者将这为称滑动频谱分解(SSD)。
衡量了多样性,那么该如何组合优化中推荐物品的多样性和质量?作者将它们相加作为最终的优化目标:
为一个超参数来平衡多样性与质量。的形式多样,可以为ctr分数,也可以是其他多个业务目标的联合值。
总结: SSD就是将整个物品序列视为用户观察到的时间序列,将其转为轨迹矩阵,再利用张量的奇异值分解,然后用对应的奇异值代表滑动窗口的多样性,最终结合质量分数,作为优化目标。
2.2 贪心推断
与DPP模型一样,我们要最大化公式(3),是一个NP-hard问题。所以作者提供了一种快速贪心推理算法来解决。
假设当前为第步,已经有个物品被选择,则需要从候选集(为已选择物品的集合)中挑选。
首先考虑的情况
当时,我们可以直接选择最高质量()物品;
当时,对于候选物品,体积就是和所张成的平行四边形面积【计算公式】:
与正交,记作,
注: 可以将与作内积进行验证。写成这个形式,应该是为了与下一步保持一致。
当时,相应平行六面体的体积也可以通过正交候选集来计算,但是是关于和,正交是Gram-Schmidt过程,公式化为
其中
没有滑动窗口的情况下(),可以重用候选物品的正交化结果,相当于一步修正的Gram-Schmidt (MGS)正交化。对于这个trick,贪心推理算法只有时间复杂度,算法如下所示:

❝
注:
1、简单再说明下的情况,初始化应该没有什么歧义。在while循环中,我们先要去计算所有不在集合中与(前一个)的正交向量【这对应着公式(4),只是求和符号里面的计算是直接更新的,所以这里只计算与的volume】,然后选择目标最大化对应的物品,其中表示平行六面体的体积,即多样性的量化。为了减少计算,需要在循环内更新。
2、建议多看几遍理解,感兴趣的话可以详细了解下MGS。
❞
然后考虑的情况(滑动窗口),
当时,如果遵循上述策略的方法就是从开始对进行正交,但是这忽略了物品和第一个窗口,与SSD联合多个窗口相违背。因此,作者在当前窗口中执行MGS(),同时保留所有选中物品的正交化结果(),允许当前窗口继承以前窗口的信息。因此,在时间步长中,贪心推理的优化目标变更为:
算法如下所示,

❝
注: 为了加速实现,作者应用循环队列来减少内存拷贝。上述算法加入了滑动窗口的考虑,简单说明下。
1、当时,用来保存当前被挑选物品的编号,用来保存物品的映射,对于每一个物品,需要先申请长度为的空间(不一定都填满),然后循环中保存当前物品与其他物品的映射。
2、当时,就可以从取出时的物品编号,从取出当时对应的映射,然后进行恢复到之前向量。再进行1的计算,选择物品。
需要时间复杂度和空间复杂度。
❞
2.3 复杂度分析比较
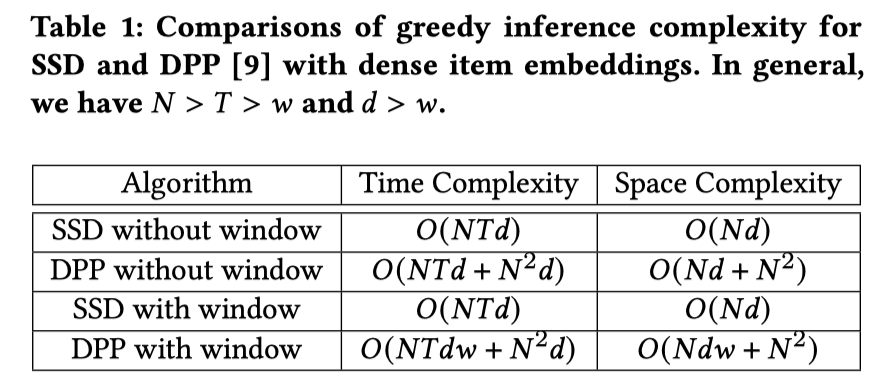
3. CB2CF
CB2CF主要是为了SSD模型服务,学习物品的Embedding向量。作者认为对于长尾物品,通过CF方法得到的物品Embedding向量在计算物品相似度时效果欠佳,所以结合了CB与CF,使用siamese网络结构学习item embedding,如下图所示:
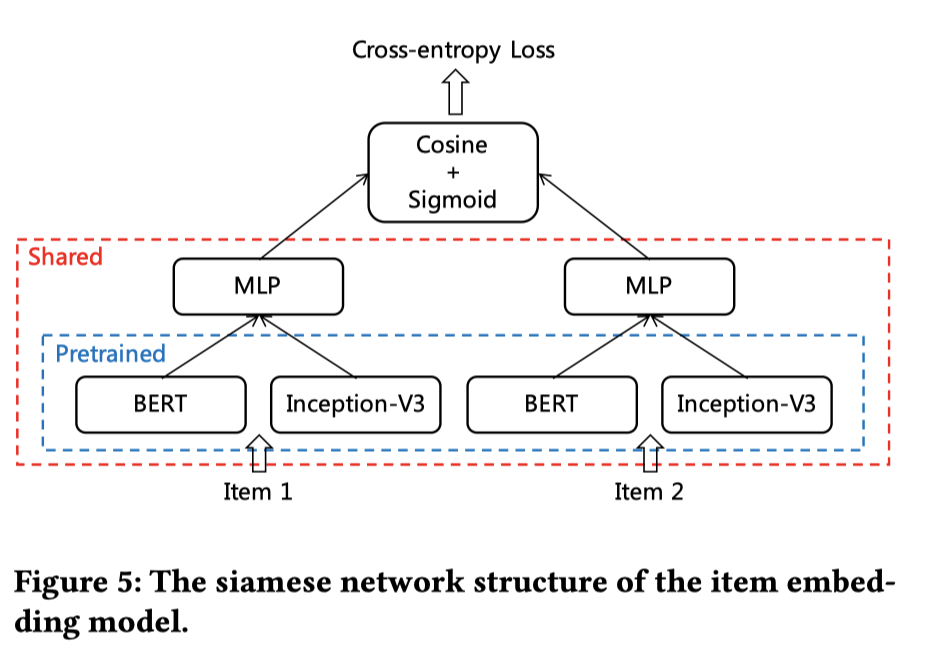
BERT用来学习内容的文字描述,Iception-V3学习图片。Item1作为种子,Item2作为候选,分别通过MLP得到抽象特征,再用余弦相似度与sigmoid得到概率分数。
1、为什么说相比CF方法,CB2CF的item embedding学习效果更好?
因为物品的特征其实是物品本身的属性,即文字描述,图片等,即使很少与用户交互,但依旧有足够多的特征。
2、如何构造样本?
首先选择一个与用户发生过交互的种子物品(点击很少也可以),则是通过召回模型例如ItemCF等方法推荐出来的结果,并且物品有足够的曝光。如果对于一个与用户发生交互的物品,则认为从用户的角度上物品与物品有很高的相似度。如果对于很多用户都是这样,那么就将这个物品对<i,j>作为正样本。
注: 对于物品,很可能是头部物品,因为要求了最小的曝光率。这种设计的一个好处是,它能够在长尾和头部项目之间建立相似关系,这可以帮助模型从商品内容归纳出相似度,也是“2CF”的原因。
负样本则是随机从ItemCF模型的推荐中挑选,构成负样本<i,j'>。
3、归一化问题
CB2CF训练中使用内积作为距离时,物品的l2范数是无界的。这种无界性可能导致物品之间的严重不公平,因为它提供了不可控制的贡献的数量。因此,我们在CB2CF训练中指定余弦相似度作为距离,使所有Embedding都具有相等的l2范数。
另一个问题是余弦距离和体积之间的不匹配。体积通常定义在内积空间上,如果两个向量的内积为0,那么它们是完全不同的。对于余弦距离,这两个完全不同的值是-1。为了解决这个问题,可以在标准化之后添加元素1的额外维度:
其中是CB2CF的输出。该变换保持了余弦函数描述的相似度,也实现了SSD的公平性和几何性质。
4. 实验
实验细节上,作者还提到了提高性能方法:在贪心推理过程中,当用户有集中的兴趣时,多样性值比质量值下降得更快。这些明显不同的趋势引入了权衡系数的稳定性问题。作者发现以下近似目标在实践中大大提高了稳定性:
该式继承了过去窗口信息,在,将此方法称为SSD*,以使SSD相对于系数更稳定。
4.1 离线实验
主要对比CF与CB2CF,突显CB2CF够早的item embedding在相似度计算上的有效性。
随机挑取10w个月点击小于3的物品(挑选长尾),通过ItemCF得到最相似的10个物品。CB2CF方法计算同一组物品的Embedding,并在向量Embedding空间中检索每个物品最相似的10个物品。为了比较检索到的物品的相似性,作者给每个物品贴上分类标签,简单使用分类法作为粗粒度近似来比较物品的相似性。结果如下图所示:
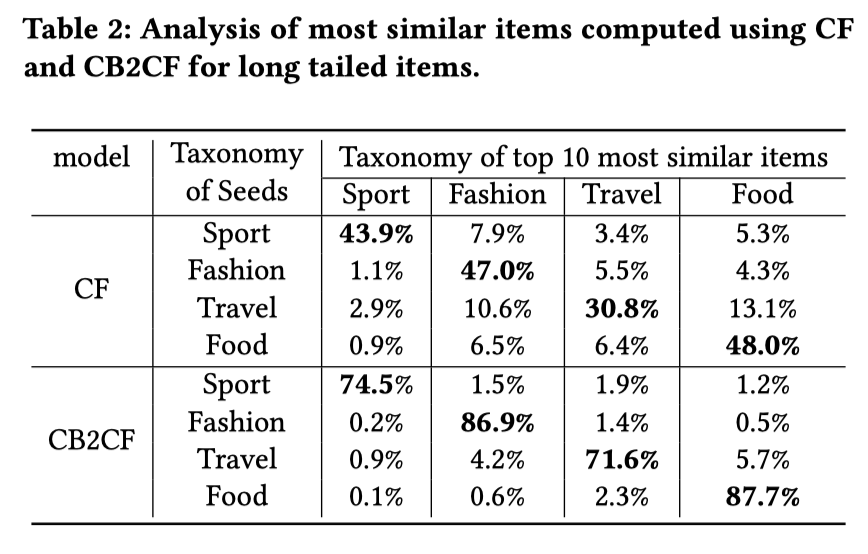
对于长尾物品,作者提出的CB2CF方法在度量长尾物品的相似性方面更有效。
4.2 在线A/B测试
在重排阶段,给出物品,最终返回物品。窗口大小依赖于设备,在区间,实验组与对照组得到的item embedding的方式相同。
对照组:10%的用户,应用DPP贪心推断方法。
实验组:10%的用户,应用SSD或者SSD*。
评估指标:
其中表示测试的用户集合,表示对于每个用户曝光的内容集合(显示在信息流中),表示用户点击过的内容集合,表示和的相似度,是将物品映射为对应的分类。
ILAD使用用户浏览物品之间的平均成对差异来衡量多样性。MRT使用用户点击的物品类别的平均数量来描述多样性。
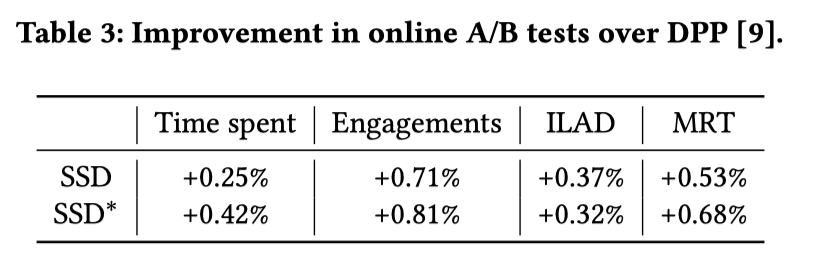
7天内A/B测试的结果如上表所示。与DPP相比,SSD显著提高了推荐结果的多样性和质量。
5. 总结
小红书提出的这个模型比较复杂,想要明白得需要了解DPP模型,并且由于论文在描述时,感觉跳了很多步,很让人费解,基础差点的同学(比如我)可能要查一些代数、几何的知识。不过总体来说,还是一篇值得学习的文章。

















 1885
1885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









