







文章地址
我们首先概括性的讲述一下这篇文章的脉络:
图片处理:经典方法,每个像素处理成0,1比特的叠加态,之后所有像素做直积;
网络结构:

这里面v是处理后的图片数据(量子态),
Ψ
\Psi
Ψ就是需要向训练的测量算子。这是一种比较经典的张量网络结构,其基本想法就是用量子测量的语言来表述图片分类的过程。
目标函数:
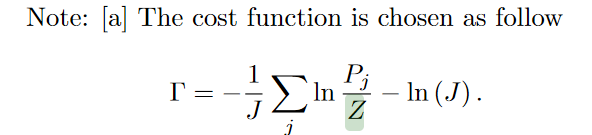
这里的目标函数实际上基于等概率假设,为什么叫生成模型,我个人是认为它是假设了概率分布后,通过一同个类别的样本生成出来的分类器。它是为每个类别分别训练一个测量算子,测试的时候测量样本坍缩到不同类别的概率。
此外,我们说一下这里张量网络梯度更新的规则。我们可以看到,目标函数实际上是一个闭合的张量网络(无开放指标),这种张量网络关于某张量的导数实际上等于将该张量移除后的张量网络:

针对文中展示的这种MPS态,我们给出一种比较具体的梯度更新方法:详见链接
这种方法除了完成梯度更新的工作外也可以进行维数裁剪的工作(因为过程中进行的是SVD分解);
首先对相邻的两个张量进行缩并:

此后就根据前述闭合张量网络梯度更新规则进行更新,之后我们利用SVD对更新后的张量进行处理:



SVD的处理方法一来可以非常方便的进行维数裁剪,另一方面也很容易决定左右张量分别以哪些纬度构成酉矩阵(因为张量如何reshape再做SVD是可以变化的),这样的话,我是让左张量变成酉矩阵,还是让右张量变成酉矩阵都是可以分别进行处理的。
另外说一下为什么我们要强调酉矩阵,因为张量网络处理机器学习问题一个很重要的特点在于他有一定的量子计算背景,我们在这边梯度更新的东西本质上是一个测量算子,我们要保证其物理含义就应该保证他在梯度更新过程中范数不变。
上面是比较详细的讲解了整个梯度更新的过程以及张量网络学习的处理手法,下面我们讲一讲这篇文章真正的核心内容:对张量网络模型优势的探讨。
从实验结果上来看,GTNC的结果还不错,但是相比于深度学习方案,如CNN等,还是有一些差距。作者认为主要差距在于CNN针对不同数据集拥有不同的网络结构,同时具有先验参数。这些和数据集相关的特殊化信息自然会提高模型的识别率.


另外,文章分析了懒惰学习效率不如GTNC的原因:
lazy learning的模型:
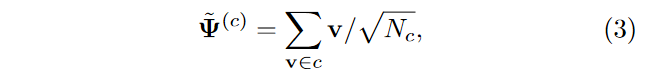
原因分析:

总而言之,作者认为这种将各个feature map直接叠加起来的测量算子,各个子系统之间的纠缠度太大,反映在MPS态上就是冗余信息过多。
下面作者分析了GTNC效率高的原因;
我们知道GTNC本质上也是将图片信息直接升维到高维空间,我们具体来看GTNC在升维后的聚集效果。
文章是比较的图片整理成向量后映射到向量空间的结果与GTNC的升维结果:

两类空间的测度方法:


这一点个人认为其实是所谓“正交灾难”的体现,两个不同的高维数(比如这里的指数维空间)向量之间做内积结果往往很接近0,这也就导致了不同类别(差异较大)的图片之间距离较大,形成了自然的聚集效应。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









