







 文章通过对餐馆评论数据进行预处理,包括缺失值处理、异常值处理、中文分词和去停用词,建立了逻辑回归、支持向量机和朴素贝叶斯分类器,逻辑回归模型表现出色。研究还涉及了水军数据的初步处理,并通过词云图、柱状图和雷达图展示了数据的统计分析结果。
文章通过对餐馆评论数据进行预处理,包括缺失值处理、异常值处理、中文分词和去停用词,建立了逻辑回归、支持向量机和朴素贝叶斯分类器,逻辑回归模型表现出色。研究还涉及了水军数据的初步处理,并通过词云图、柱状图和雷达图展示了数据的统计分析结果。
餐馆评论的文本分析
0 引言
本文利用python语言,对餐馆的大众点评评论文本进行分析。首先,通过数据清洗、中文分词以及特征工程完成数据的预处理。对完成预处理的数据作了描述统计说明。
其次,构建了逻辑回归、支持向量机和朴素贝叶斯三个分类器模型,计算召回率、精确度、F1和准确率等指标来评价它们的实际性能。逻辑回归模型表现最好,准确率为85%,可以用于实现对餐馆评论文本的精确分类。
最后,基于处理好的数据利用关键字查询餐馆的名称,并通过可视化手段展示某个餐馆的评论、好评/差评比例、环境评分、口味评分、服务评分以及随时间变化的好评/差评线图等指标。
1 数据预处理
1.1 数据集描述
本文研究使用的餐馆大众点评评论文本包含3个数据集:restaurants.csv、ratings.csv、links.csv。数据集字段信息及部分示例数据如表1-3。



restaurant数据集包含 243247条餐馆数据
餐馆数目(有名称): 209132
餐馆数目(没有名称):34115
餐馆数目(总计): 243247
ratings数据集包含 4422473条评论数据、542706个用户
用户数目:542706
评分/评论数目(总计): 4422473
总体评分数目([1,5]): 3293878
环境评分数目([1,5]): 4076220
口味评分数目([1,5]): 4093819
服务评分数目([1,5]): 4076220
评论数目: 4107409
links数据集包含243247条数据
1.2 缺失值处理
对缺失值的处理主要是删除数据中的空值。
- 查看restaurant数据集的缺失值。
print(restaurants.isnull().sum(axis=0))

restaurant数据集name列有34115条缺失值。因为后文有可视化分析,没有餐馆名称的数据直接删掉。
- 查看ratings数据集的数据集
print(ratings.isnull().sum(axis=0))
ratings数据集总共4422473条数据
评分有1128580条缺失值
环境评分有346253条缺失值
口味评分有328654缺失值
服务评分有346253条缺失值
评论内容有315064条缺失值
首先删除restaurant数据集中餐馆名称为nan的restId,对应的ratings数据集数据。然后再删除评论内容中的缺失值。
# 删除餐馆名称为nan的restId,对应的ratings数据,要删除的id→id_with_missing_values
# 根据id删除行
data = ratings.set_index('restId').drop(id_with_missing_values).reset_index()
# 删除评论内容为nan的值
data.dropna(axis=0, subset='comment', inplace=True)
处理完之后再查看ratings数据集的缺失值。

处理之后发现rating_env、rating_flavor、rating_service均有55个缺失值,对缺失值进行具体探查。
# 查看rating_env列有缺失值的行
null_rating_env = data[data['rating_env'].isna()]
print(null_rating_env)
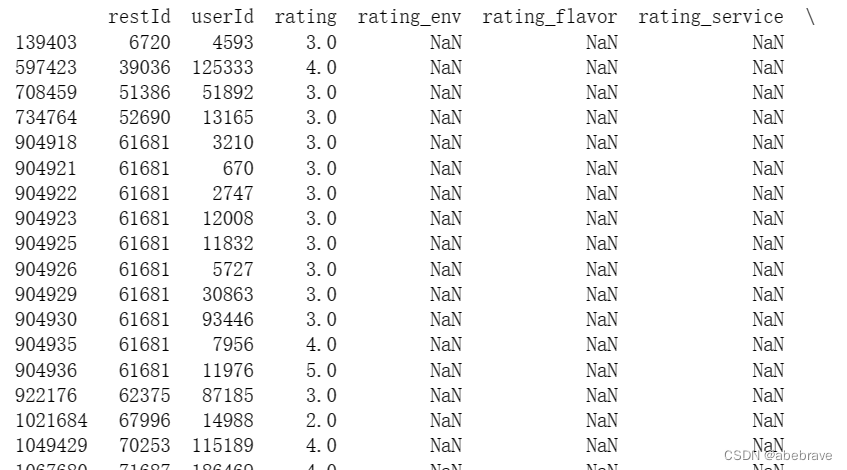
从图中可以看出rating_env、rating_flavor、rating_service是一起缺失的,所以直接删掉就好了。
然后rating列还存在1013107条缺失值,因为缺失值占据数据集的1/4,所以不能直接删除,初步的想法是对rating列进行填充。
因为数据量太大了,对于我个人的电脑来说要运行很久,所以直接删除好了。
1.3 异常值处理
同时呢我们观察到在ratings数据集中存在环境、口味、服务的评分与总评分不符合的情况,例如对环境、口味、服务评分只有1-2分,但是总评分却是4分及以上。可能是因为该餐馆在其他方面得到了更高的评价,例如价格、装修或者地理位置等。这些低分的评价可能是由于个别顾客对某些方面的不满意而导致的,不能完全反映该餐厅的整体评价,或者是某些用户的评分标准与其他用户存在很大差异,导致他们给的评分与整体评分相差较大。会影响对评论文本的情感分析,需要进行处理。
# 筛选rating_env、rating_flavor、rating_service评分为3分以下,rating评分为3分及以上的数据
data1 = known_rating[(known_rating['rating_env'] < 3) & (known_rating['rating_flavor'] < 3)
& (known_rating['rating_service'] < 3) & (known_rating['rating'] >= 4)]
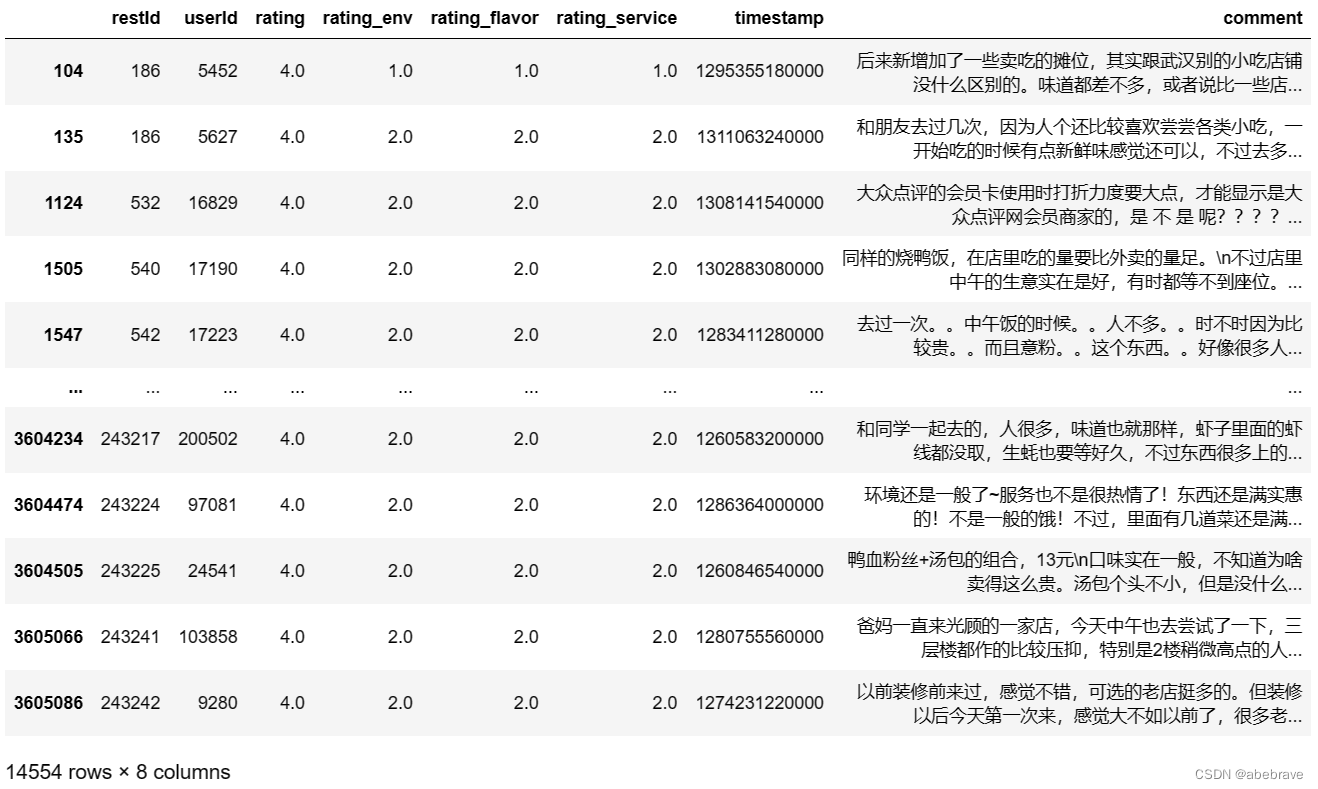
# 筛选rating_env、rating_flavor、rating_service评分为3分以上,rating评分为3分以下的数据
data2 = known_rating[(known_rating['rating_env'] >= 3) & (known_rating['rating_flavor'] >= 3)
& (known_rating['rating_service'] >= 3) & (known_rating['rating'] < 4)]
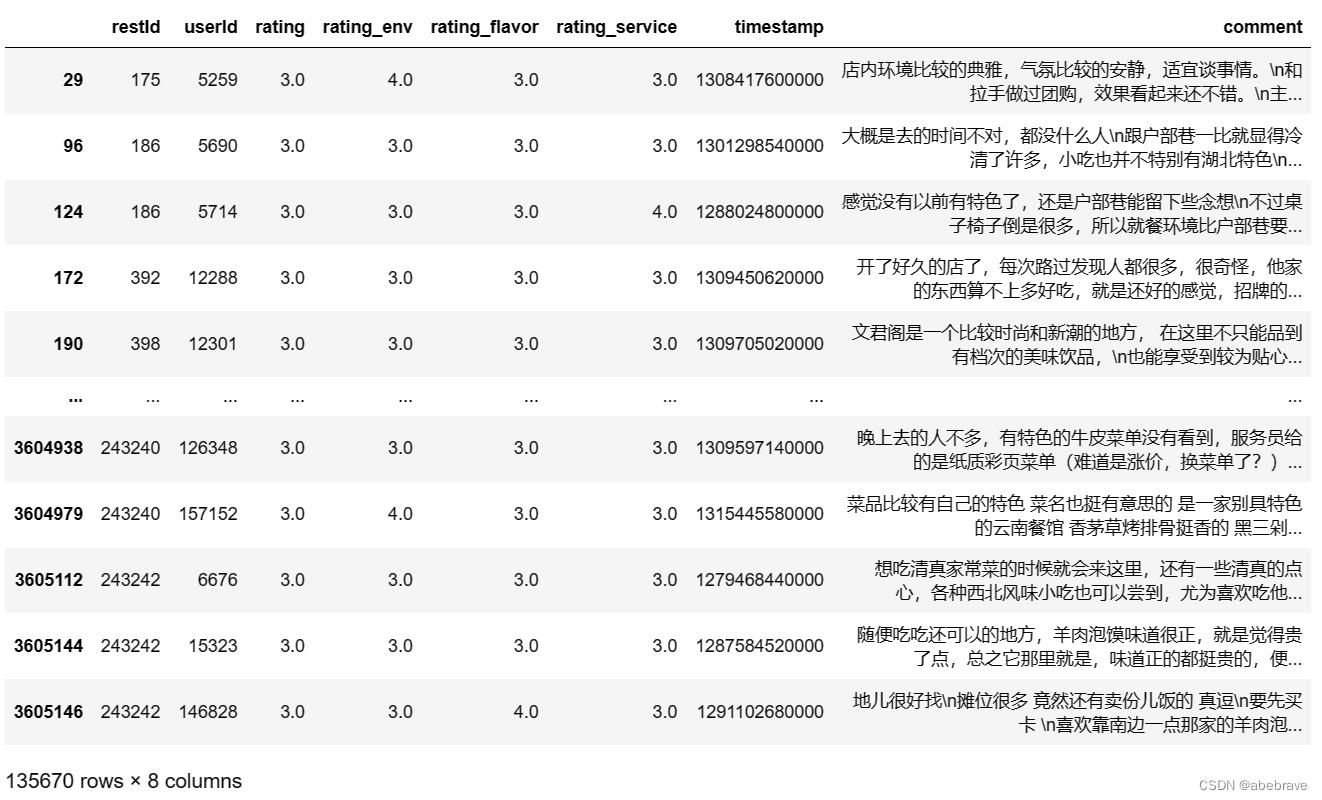
所以对于rating列异常值和异常值本文采取的处理方法是对所有维度的评分进行加权,并将其作为综合评分使用。这样可以更准确地反映顾客的整体评价,避免过于依赖单个维度(例如总评分)而导致评估不准确或误导。
权值的设置是自定义的,该赋权过程可以用公式表示如下:
rating_2=0.4×rating+0.2×rating_env+0.2×rating_flavor+0.2×rating_service
其中rating_2表示计算出的综合评分,其为0-5的数值。
利用综合评分的分值可以划分评论数据为好评数据和差评数据,设置rating_2值为[0,3]的评论为差评,rating_2值为[4,5]的评论为好评,将结果保存到evaluation列,其中“1”代表好评,“0”代表差评。
# 计算总的得分rating_2
data['rating_2'] = data['rating_env']*0.2 + data['rating_flavor']*0.2 + data['rating_service']*0.2 + data['rating']*0.4
# 划分好评和差评
data['evaluation'] = data['rating_2'].apply(lambda x: 0 if x < 4 else 1)
1.4 短句及特殊字符删除
评论字段中字符长度较小的数据,利用价值小。将评论文本中字符长度小于10的数据删除。
data = data[data['comment'].apply(len) >= 10]
还有一些特殊字符如英文、数字、表情符号、字符串等,对于特殊字符采用正则表达式re进行剔除,这个在去停用词部分处理。
1.5 中文分词、去停用词
中文文本与英文文本之间的差别很大,在中文表达中没有作为分隔符的空格出现,同时具体的汉字表达的意思也是极不明确的,单个词语更不能十分准确地表达意思。因此需要先对文本进行分词操作,然后对分词后的结果逐一进行表示。本文使用的是jieba分词技术来进行中文文本分词。
文本在经过分词之后存在很多像“的”、“了”、“吧”、“啊”、“这”等一些无实际意义的语气词、代词、介词等,还有标点符号、特殊符号等都称为停用词。这类词不仅会提升模型的复杂性还会影响分类效果,所以需要过滤这些无意义的词,从而减少文本的噪音,增大关键词密度,提高文本分类的准确率和主题分析的效率。
基于前人的研究成果,本文搜集了一些停用词典,主要包括哈工大停用词典、百度停用词典、四川大学机器智能实验室停用词库以及中文停用词表,将它们合并去重最后得到包含 1893个停用词的停用词典。
值得注意的是,由于本研究的数据量过大,在分词过程中将数据集划分为10个批次,对每个批次都进行了去停用词的处理,将结果依次保存为文件,最后将10个文件合并。
import jieba
import re
from sklearn.model_selection import KFold
# 加载停用词表
stop_words = set()
with open('D:/课程/数据挖掘技术与实践/作业/tc-corpus-answer/停用词表/stopwords.txt', encoding=encoding) as f:
for line in f:
stop_words.add(line.strip())
def preprocess_text(text):
# 去除空白字符
text = re.sub(r'\s+', '', text)
# 分词
seg_list = jieba.lcut(text)
# 去除停用词和非中文字符
seg_list = [token for token in seg_list if token not in stop_words and re.match(r'^[\u4e00-\u9fa5]+$', token)]
return ' '.join(seg_list)
# 划分数据集为 10 个批次,并对每个批次中的 comment 列进行预处理,并单独保存到文件中
kfold = KFold(n_splits=10, shuffle=True, random_state=42)
for i, (train_idx, test_idx) in enumerate(kfold.split(df)):
df_batch = df.iloc[test_idx].copy 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1929
1929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









