










Spring Data Jpa学习笔记
- Spring Data Jpa条件查询
- Spring Data Jpa删除和批量删除
- Spring Data Jpa实体类注解
- pageable和specification
- Jpa存入多张图片解决方案
- 问题
- 1. Field 'id' doesn't have a default value
- 2. Unable to locate Attribute with the the given name [noticeId] on this ManageType [com.example.demo.entity.ContentNoticeAutoPublish]
- 3. java.lang.IllegalArgumentException: org.hibernate.ObjectDeletedException: deleted instance passed to merge: [com.ssy.lingxi.product.entity.commodity.CommodityUnitPriceAndPic#]
什么是JPA?
相同处:
- 都跟数据∙库操作有关,JPA 是JDBC 的升华,升级版。
- JDBC和JPA都是一组规范接口 3.都是由SUN官方推出的
不同处:
- JDBC是由各个关系型数据库实现的, JPA 是由ORM框架实现。
- JDBC 使用SQL语句和数据库通信。 JPA用面向对象方式, 通过ORM框架来生成SQL,进行操作。
- JPA在JDBC之上的, JPA也要依赖JDBC才能操作数据库。
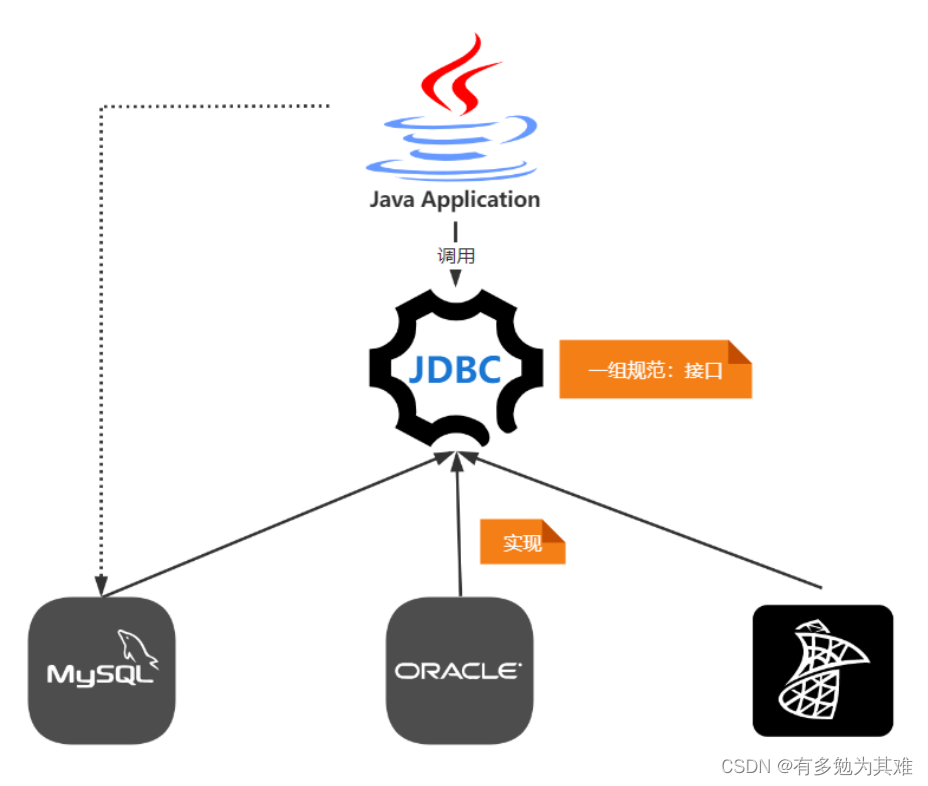
JDBC是我们最熟悉的用来操作数据库的技术,但是随之而来带来了一些问题:
- 需要面向SQL语句来操作数据库,开发人员学习成本更高。
- 数据库的移至性不高,不同数据库的SQL语句无法通用。
- java对象和数据库类型的映射是个麻烦事。
但在Sun在JDK1.5提出了JPA: JPA全称Java Persistence API(2019年重新命名为 Jakarta Persistence API ),是Sun官方提出的一种ORM规范。
O:Object R: Relational M:mapping
作用
- 简化持久化操作的开发工作:让开发者从繁琐的 JDBC 和 SQL 代码中解脱出来,直接面向对象持久化操作。
- Sun希望持久化技术能够统一,实现天下归一:如果你是基于JPA进行持久化你可以随意切换数据库。
**该规范为我们提供了:
-
ORM映射元数据:JPA支持XML和注解两种元数据的形式,元数据描述对象和表之间的映射关系,框架据此将实体对 象持久化到数据库表中;
如:@Entity、@Table、@Id与@Column等注解。 -
JPA 的API:用来操作实体对象,执行CRUD操作,框架在后台替我们完成所有的事情,开发者从繁琐的JDBC和 SQL代码中解脱出来。 如:
entityManager.merge(T t); -
JPQL查询语言:通过面向对象而非面向数据库的查询语言查询数据,避免程序的SQL语句紧密耦合。
如:from Student s where s.name = ?
So: JPA仅仅是一种规范,也就是说JPA仅仅定义了一些接口,而接口是需要实现才能工作的。
Hibernate与JPA:
所以底层需要某种实现,而Hibernate就是实现了JPA接口的ORM框架。
也就是说:JPA是一套ORM规范,Hibernate实现了JPA规范!
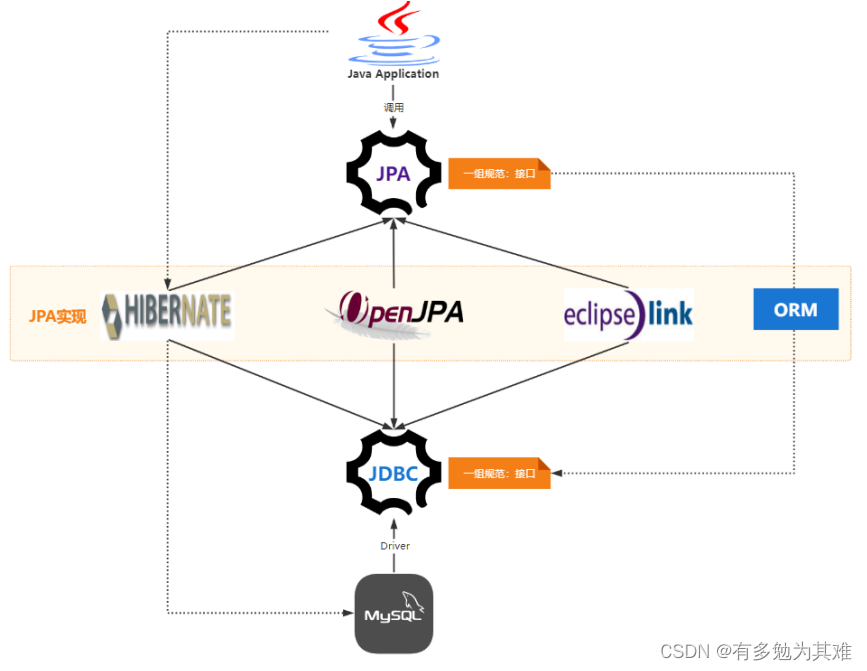
mybatis:小巧、方便?、高效、简单、直接、半自动
半自动的ORM框架,
小巧: mybatis就是jdbc封装 在国内更流行。
场景: 在业务比较复杂系统进行使用。
hibernate:强大、方便、高效、(简单)复杂、绕弯子、全自动 全自动的ORM框架。
强大:根据ORM映射生成不同SQL 在国外更流行。
场景: 在业务相对简单的系统进行使用,随着微服务的流行。
Hibernate示例
https://docs.jboss.org/hibernate/orm/5.5/userguide/html_single/Hibernate_User_Guide.html#hql
pom.xml
<!--junit4 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
<scope>test</scope>
</dependency>
<!--hibernate对jpa的支持包-->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate‐entitymanager</artifactId>
<version>5.4.32.Final</version>
</dependency>
<!--Mysql-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql‐connector‐java</artifactId>
<version>5.1.22</version>
</dependency>
如果单独使用hibernate的API来进行持久化操作,则不能随意切换其他ORM框架
jpa的对象4种状态
- 临时状态:刚创建出来,∙没有与entityManager发生关系,没有被持久化,不处于entityManager中的对象。
- 持久状态:∙与entityManager发生关系,已经被持久化,您可以把持久化状态当做实实在在的数据库记录。
- 删除状态:执行remove方法,事物提交之前。
- 游离状态:游离状态就是提交到数据库后,事务commit后实体的状态,因为事务已经提交了,此时实体的属
性任你如何改变,也不会同步到数据库,因为游离是没人管的孩子,不在持久化上下文中。
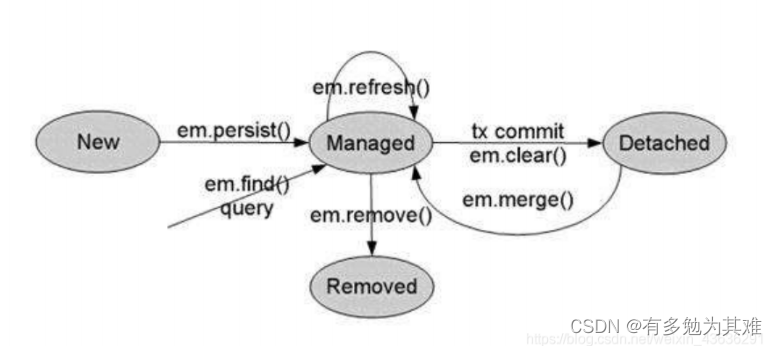
public void persist(Object entity)
persist方法可以将实例转换为managed(托管)状态。在调用flush()方法或提交事物后,实 例将会被插入到数据库中。
对不同状态下的实例A,persist会产生以下操作:
- 如果A是一个new状态的实体,它将会转为managed状态;
- 如果A是一个managed状态的实体,它的状态不会发生任何改变。但是系统仍会在数据库执行INSERT操作;
- 如果A是一个removed(删除)状态的实体,它将会转换为受控状态;
- 如果A是一个detached(分离)状态的实体,该方法会抛出IllegalArgumentException异常,具体异常根据不同的 JPA实现有关。
public void merge(Object entity)
merge方法的主要作用是将用户对一个detached状态实体的修改进行归档,归档后将产生 一个新的managed状态对象。
对不同状态下的实例A,merge会产生以下操作:
- 如果A是一个detached状态的实体,该方法会将A的修改提交到数据库,并返回一个新的managed状态的实例A2;
- 如果A是一个new状态的实体,该方法会产生一个根据A产生的managed状态实体A2;
- 如果A是一个managed状态的实体,它的状态不会发生任何改变。但是系统仍会在数据库执行UPDATE操作;
- 如果A是一个removed状态的实体,该方法会抛出IllegalArgumentException异常。
public void refresh(Object entity)
refresh方法可以保证当前的实例与数据库中的实例的内容一致。
对不同状态下的实例A,refresh会产生以下操作:
- 如果A是一个new状态的实例,不会发生任何操作,但有可能会抛出异常,具体情况根据不同JPA实现有关;
- 如果A是一个managed状态的实例,它的属性将会和数据库中的数据同步;
- 如果A是一个removed状态的实例,该方法将会抛出异常: Entity not managed
- 如果A是一个detached状态的实体,该方法将会抛出异常。
public void remove(Object entity)
remove方法可以将实体转换为removed状态,并且在调用flush()方法或提交事物后删除数据库中的数据。
对不同状态下的实例A,remove会产生以下操作:
- 如果A是一个new状态的实例,A的状态不会发生任何改变,但系统仍会在数据库中执行DELETE语句;
- 如果A是一个managed状态的实例,它的状态会转换为removed;
- 如果A是一个removed状态的实例,不会发生任何操作;
- 如果A是一个detached状态的实体,该方法将会抛出异常。
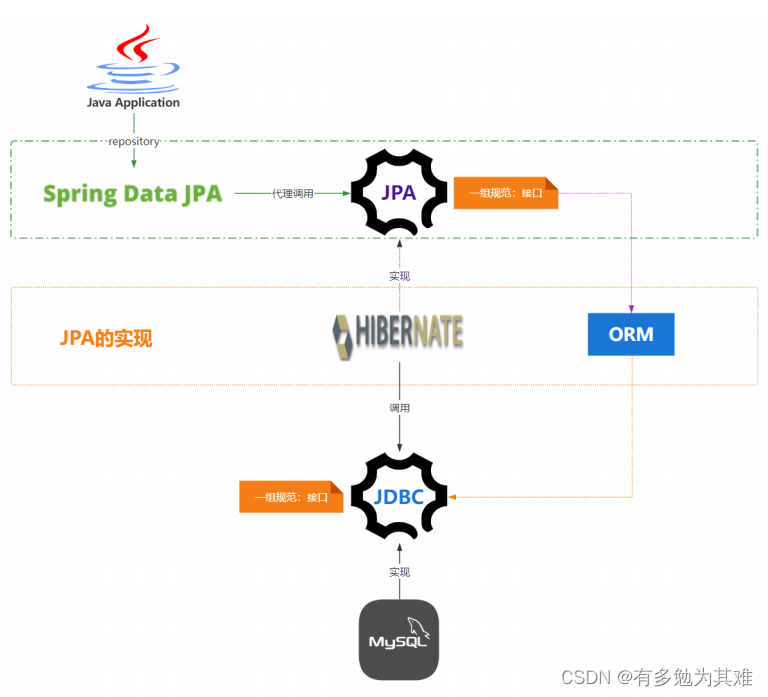
Spring data JPA
介绍
官网:https://spring.io/projects/spring-data-jpa#overview
Spring Data JPA, part of the larger Spring Data family, makes it easy to easily implement JPA based repositories. This module deals with enhanced support for JPA based data access layers. It makes it easier to build Spring-powered applications that use data access technologies.
Implementing a data access layer of an application has been cumbersome for quite a while. Too much boilerplate code has to be written to execute simple queries as well as perform pagination, and auditing. Spring Data JPA aims to significantly improve the implementation of data access layers by reducing the effort to the amount that’s actually needed. As a developer you write your repository interfaces, including custom finder methods, and Spring will provide the implementation automatically.
翻译:
Spring Data JPA 是更大的 Spring Data 系列的一部分,可以轻松实现基于 JPA 的repositories。该模块处理对基于 JPA 的数据访 问层的增强支持。它使构建使用数据访问技术的 Spring 驱动的应用程序变得更加容易。
实现应用程序的数据访问层已经很麻烦了。必须编写太多样板代码来执行简单的查询以及执行分页和审计。Spring Data JPA 旨在改 进数据访问层的实现以提升开发效率。作为开发人员,您编写存储库接口,包括自定义 finder 方法,Spring 将自动提供实现。
总结:
spirng data jpa是spring提供的一套简化JPA开发的框架,按照约定好的规则进行【方法命名】去写dao层接口,就可以 在不写接口实现的情况下,实现对数据库的访问和操作。同时提供了很多除了CRUD之外的功能,如分页、排序、复杂查 询等等。
Spring Data JPA 让我们解脱了DAO层的操作,基本上所有CRUD都可以依赖于它来实现,在实际的工作工程中,推荐使 用Spring Data JPA + ORM(如:hibernate)完成操作,这样在切换不同的ORM框架时提供了极大的方便,同时也使 数据库层操作更加简单,方便解耦。
SpringData Jpa 极大简化了数据库访问层代码。 如何简化的呢? 使用了SpringDataJpa,我们的dao层中只需要写接 口,就自动具有了增删改查、分页查询等方法。
Spring Data JPA实例
我们来实现一个基于Spring Data JPA的示例感受一下和之前单独使用的区别:
依赖
- 最好在父maven项目中设置spring data统一版本管理依赖: 因为不同的spring data子项目发布时间版本不一样,你自 己维护很麻烦, 这样不同的spring data子项目能保证是统一版本。
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring‐data‐bom</artifactId>
<version>2020.0.14</version>
<scope>import</scope>
<type>pom</type>
</dependency>
</dependencies>
</dependencyManagement>
- 在子项目中添加:
<dependencies>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring‐data‐jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring‐data‐jpa</artifactId>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate‐entitymanager</artifactId>
<version>5.4.32.Final</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql‐connector‐java</artifactId>
<version>5.1.22</version>
</dependency>
<!‐‐junit4‐‐>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.8</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring‐test</artifactId>
<version>5.3.10</version>
<scope>test</scope>
</dependency>
<dependencies>
使用 Spring Data Repositories
Spring Data repository 抽象的目标是显着减少为各种持久性存储实现数据访问层所需的样板代码量。
// 用来插入和修改 有主键就是修改 没有就是新增
// 获得插入后自增id, 获得返回值
<S extends T> S save(S entity);
// 通过集合保存多个实体
<S extends T> Iterable<S> saveAll(Iterable<S> entities);
// 通过主键查询实体
Optional<T> findById(ID id);
// 通过主键查询是否存在 返回boolean
boolean existsById(ID id);
// 查询所有
Iterable<T> findAll();
// 通过集合的主键 查询多个实体,, 返回集合
Iterable<T> findAllById(Iterable<ID> ids);
// 查询总数量
long count();
// 根据id进行删除
void deleteById(ID id);
// 根据实体进行删除
void delete(T entity);
// 删除多个
void deleteAllById(Iterable<? extends ID> ids);
// 删除多个传入集合实体
void deleteAll(Iterable<? extends T> entities);
// 删除所有
void deleteAll();
在 之上CrudRepository,有一个PagingAndSortingRepository抽象,它添加了额外的方法来简化对实体的分页访问:
// jdk动态代理的实例
@Autowired
CustomerRepository repository;
@Test
public void testPaging(){
Page<Customer> all = repository.findAll(PageRequest.of(0, 2));
// 每页显示数量
System.out.println("每页显示数:"+articlePage.getSize());
// 总页数
System.out.println("一共多少页:"+articlePage.getTotalPages());
// 查询内容总数
System.out.println("一共多少条数据:"+articlePage.getTotalElements());
//每页显示的内容列表
System.out.println("数据:"+articlePage.getContent());
}
自定义操作:
jpql(原生SQL)
@Query
-
查询如果返回单个实体 就用pojo接收 , 如果是多个需要通过集合
-
参数设置方式:
- 索引 : ?+数字
- 具名: :+参数名 结合@Param注解指定参数名字
-
增删改:
- 要加上事务的支持:
- 如果是插入方法:一定只能在hibernate下才支持 (Insert into …select )
@Transactional // 通常会放在业务逻辑层上面去声明
@Modifying // 通知springdatajpa 是增删改的操作
@Transactional//事务的注解
@Modifying//增删改必须有这个注解
@Query(value = "update ms_mc_member_user set password_error_times =:passwordErrorTimes,lock_time =:lockTime where id = :id", nativeQuery = true)
void updateErrorTimesById(Integer passwordErrorTimes, Long lockTime, Long id);
规定方法名
- 支持的查询方法主题关键字(前缀)
- 决定当前方法作用
- 只支持查询和删除
查询主题关键字
| 关键词 | 描述 |
|---|---|
| find…By , read…By , get.By ,query…By , search…,By , stream….By | 通用查询方法通常返回存储库类型、Collection或streamable子类型或结果包装器,例如Page ,GeoResults或任何其他特定于商店的结果包装器。可用作findBy… ,findMyDomainTypeBy…或与其他关键字结合使用。 |
| exists…By | 存在投影,通常返回boolean结果。 |
| count…By | 计数投影返回数字结果。 |
| delete…By , remove…By | 删除查询方法返回无结果(void)或删除计数。 |
| … First… , …Top… | 将查询结果限制为第一个<number〉结果。此关键字可以出现在主题的find(和其他关键字)和之间的任何位置by 。 |
| …Distinct… | 使用不同的查询仅返回唯一的结果。查阅特定于商店的文档是否支持该功能。此关键字可以出现在主题的 find(和其他关键字)和之间的任何位置by |
推荐一个插件,可以提示,非常方便:jpa buddy
- 支持的查询方法谓词关键字和修饰符
- 决定查询条件
| 关键词 | 样本 | JPQL片段 |
|---|---|---|
| Distinct | findDistinctByLastnameAndFirstname | select distinct … where x.lastname = ?1 andx.firstname = ?2 |
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is , Equals | findByFirstname, findByFirstnameIs, findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findBystartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age <= ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqua | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull, Null | findByAge(Is)Null | … where x.age is null |
| IsNotNull, NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| Startingwith | findByFirstnameStartingwith | … where x.firstname like ?1(参数绑定了append% ) |
| Endingwith | findByFirstnameEndingwith | … where x.firstname like ?1(参数绑定prepended% ) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1(参数绑定包裹在% ) |
| orderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection< Age> ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection< Age> ages) | … where x.age not in ?1 |
| True | findByActiveTrue() | … where x.active = true |
| False | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstname) = UPPER(?1) |
Query by Example
只支持查询
- 不支持嵌套或分组的属性约束,如 firstname = ?0 or (firstname = ?1 and lastname = ?2).
- 只支持字符串 start/contains/ends/regex 匹配和其他属性类型的精确匹 配。
实现:
- 将Repository继承QueryByExampleExecutor
public interface CustomerQBERepository extends PagingAndSortingRepository<Customer,Long>,QueryByExampleExecutor<Customer> {
}
- 测试代码
@Test
public void test01() {
Customer customer = new Customer();
customer.setCustName("徐庶");
Example<Customer> example = Example.of(customer);
System.out.println(repository.findAll(example));
}
@Test
public void test02() {
Customer customer = new Customer();
customer.setCustAddress("beijing");
// 匹配器, 去设置更多条件匹配
ExampleMatcher matcher = ExampleMatcher.matching()
.withIgnoreCase("custAddress");
Example<Customer> example = Example.of(customer, matcher);
System.out.println(repository.findAll(example));
}
Specifications
在之前使用Query by Example只能针对字符串进行条件设置,那如果希望对所有类型支持,可以使用Specifications
实现
- 继承接口JpaSpecificationExecutor
public interface CustomerRepository extends CrudRepository<Customer, Long>, JpaSpecificationExecutor<Customer> {
…
}
- 传入Specification的实现: 结合lambda表达式
repository.findAll((Specification<Customer>)
(root, query, criteriaBuilder) ‐>
{
// Todo...
return null;
});
}
Root:查询哪个表(关联查询) = from
CriteriaQuery:查询哪些字段,排序是什么 =组合(order by . where )
CriteriaBuilder:条件之间是什么关系,如何生成一个查询条件,每一个查询条件都是什么类型(> between in…) = where
Predicate(Expression): 每一条查询条件的详细描述
List<Customer> list = repository.findAll((Specification<Customer>)
(root, query, criteriaBuilder) ‐>
{
Order weightOrder = criteriaBuilder.desc(root.get("custId"));
CriteriaBuilder.In<Object> id = criteriaBuilder.in(root.get("custId"));
id.value(1).value(7);
return query.orderBy(weightOrder).where(id).getRestriction();
});
Specification<MemberRelationDO> specification = (Specification<MemberRelationDO>) (root, query, criteriaBuilder) -> {
List<Predicate> list = new ArrayList<>();
list.add(criteriaBuilder.or(criteriaBuilder.equal(root.get("memberId").as(Long.class), memberDO.getId()), criteriaBuilder.equal(root.get("subMemberId").as(Long.class), memberDO.getId())));
Predicate[] p = new Predicate[list.size()];
query.orderBy(criteriaBuilder.desc(root.get("createTime")));//排序
return criteriaBuilder.and(list.toArray(p));
};
List<MemberRelationDO> relationDOList = relationRepository.findAll(specification);
限制:
不能分组、聚合函数, 需要自己通过entityManager玩
Querydsl
官网https://querydsl.com/ QueryDsl文档https://querydsl.com/static/querydsl/4.1.3/reference/html_single/
QueryDSL是基于ORM框架或SQL平台上的一个通用查询框架。借助QueryDSL可以在任何支持的ORM框架或SQL平台 上以通用API方式构建查询。
JPA是QueryDSL的主要集成技术,是JPQL和Criteria查询的代替方法。目前QueryDSL支持的平台包括 JPA,JDO,SQL,Mongodb 等等。。。
Querydsl扩展能让我们以链式方式代码编写查询方法。该扩展需要一个接口QueryDslPredicateExecutor,它定义了很 多查询方法。
接口继承了该接口,就可以使用该接口提供的各种方法了
public interface QuerydslPredicateExecutor<T> {
T findOne(Predicate predicate);
Iterable<T> findAll(Predicate predicate);
long count(Predicate predicate);
boolean exists(Predicate predicate);
// … more functionality omitted.
}
interface UserRepository extends CrudRepository<User, Long>, QuerydslPredicateExecutor<User> {
}
引入依赖
<querydsl.version>4.4.0</querydsl.version>
<apt.version>1.1.3</apt.version>
<!‐‐ querydsl ‐‐>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl‐jpa</artifactId>
<version>${querydsl.version}</version>
</dependency>
添加maven插件
这个插件是为了让程序自动生成query type(查询实体,命名方式为:“Q”+对应实体名)。
<build>
<plugins>
<plugin>
<groupId>com.mysema.maven</groupId>
<artifactId>apt‐maven‐plugin</artifactId>
<version>${apt.version}</version>
<dependencies>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl‐apt</artifactId>
<version>${querydsl.version}</version>
</dependency> 13 </dependencies>
<executions>
<execution>
<phase>generate‐sources</phase>
<goals>
<goal>process</goal>
</goals>
<configuration>
<outputDirectory>target/generated‐sources/queries</outputDirectory><processor>com.querydsl.apt.jpa.JPAAnnotationProcessor</processor>
<logOnlyOnError>true</logOnlyOnError>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
执行mvn compile之后,可以找到该target/generated-sources/java,然后IDEA标示为源代码目录即可

QuerydslPredicateExecutor查询结果:
/* 等于 EQ : equal .eq
不等于 NE : not equal .ne
小于 LT : less than .lt
大于 GT : greater than .gt
小于等于 LE : less than or equal .loe
大于等于 GE : greater than or equal .goe
*/
@Autowired
CustomerDslRepository repository;
@Test
public void test02(){
QCustomer qCustomer = QCustomer.customer;
Iterable<Customer> all = repository.findAll(qCustomer.id.in(1L, 5L).and(qCustomer.firstName.in("徐庶", "王五")));
System.out.println(all);
}
自定义查询结果
@Autowired
CustomerDslRepository repository;
@PersistenceContext
EntityManager em;
@Test
public void test01(){
JPAQueryFactory queryFactory = new JPAQueryFactory(em);
QCustomer qCustomer = QCustomer.customer;
QueryResults<Tuple> tupleQueryResults = queryFactory.from(qCustomer)
.select(qCustomer.id.sum(), qCustomer.id)
.where( 15 qCustomer.id.between(1, 2)
)
.orderBy(qCustomer.id.desc())
.groupBy(qCustomer.id)
.fetchResults();
for (Tuple result : tupleQueryResults.getResults()) {
System.out.println(result.get(qCustomer.id));
System.out.println(result.get(qCustomer.id.sum()));
}
}
多表关联操作
一对一
客户表—>老婆表
客户表—>账户表
…
实现:
- 配置管理关系
@OneToOne
@JoinColumn(name=“外键字段名”)
@OneToOne(mappedBy = "customer",cascade = {CascadeType.PERSIST,CascadeType.REMOVE})
@JoinColumn(name="wife_id")
private Wife wife;
Wife
/* 一对一
一个客户对一个账户 */
@Entity
@Table(name="tb_account")
@Data
/*@Getter // 生成所有属性的get方法
@Setter // 生成所有属性的set方法
@RequiredArgsConstructor // 生成final属性的构造函数, 如果没有final就是无参构造函数
@EqualsAndHashCode*/
public class Account {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
private String password;
}
- 配置关联操作:
// 单向关联 一对一
/*
cascade 设置关联操作
ALL, 所有持久化操作
PERSIST 只有插入才会执行关联操作
MERGE, 只有修改才会执行关联操作
REMOVE, 只有删除才会执行关联操作
fetch 设置是否懒加载
EAGER 立即加载(默认)
LAZY 懒加载( 直到用到对象才会进行查询,因为不是所有的关联对象 都需要用到)
orphanRemoval 关联移除(通常在修改的时候会用到)
一旦把关联的数据设置null ,或者修改为其他的关联数据, 如果想删除关联数据, 就可以设置true
optional 限制关联的对象不能为null
true 可以为null(默认 ) false 不能为null
mappedBy 将外键约束执行另一方维护(通常在双向关联关系中,会放弃一方的外键约束)
值= 另一方关联属性名
*/
@OneToOne(mappedBy = "customer",
cascade = CascadeType.ALL,fetch = FetchType.LAZY,orphanRemoval=true,optional=false)
// 设置外键的字段名
@JoinColumn(name="account_id")
private Account account;
}
测试:
@ContextConfiguration(classes = SpringDataJPAConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class OneToOneTest {
@Autowired
CustomerRepository repository;
// 插入
@Test
public void testC(){
// 初始化数据
Account account = new Account();
account.setUsername("xushu");
Customer customer = new Customer();
customer.setCustName("徐庶");
customer.setAccount(account);
account.setCustomer(customer);
repository.save(customer);
}
// 插入
@Test
// 为什么懒加载要配置事务 :
// 当通过repository调用完查询方法,session就会立即关闭, 一旦session你就不能查询,
// 加了事务后, 就能让session直到事务方法执行完毕后才会关闭
@Transactional(readOnly = true)
public void testR(){
Optional<Customer> customer = repository.findById(3L); // 只查询出客户, session关闭
System.out.println("=================");
System.out.println(customer.get()); // toString
}
@Test
public void testD(){
repository.deleteById(1L);
}
@Test
public void testU(){
Customer customer = new Customer();
customer.setCustId(16L);
customer.setCustName("徐庶");
customer.setAccount(null);
repository.save(customer);
}
}
差异:
这两个设置之间的区别在于对 断开关系.例如,当设置 地址字段设置为null或另一个Address对象.
- 如果指定了 orphanRemoval = true ,则会自动删除断开连接的Address实例.这对于清理很有用 没有一个不应该存 在的相关对象(例如地址) 来自所有者对象(例如员工)的引用.
- 如果仅指定 cascade = CascadeType.REMOVE ,则不会执行任何自动操作,因为断开关系不是删除操作
一对多
一个客户有多条信息
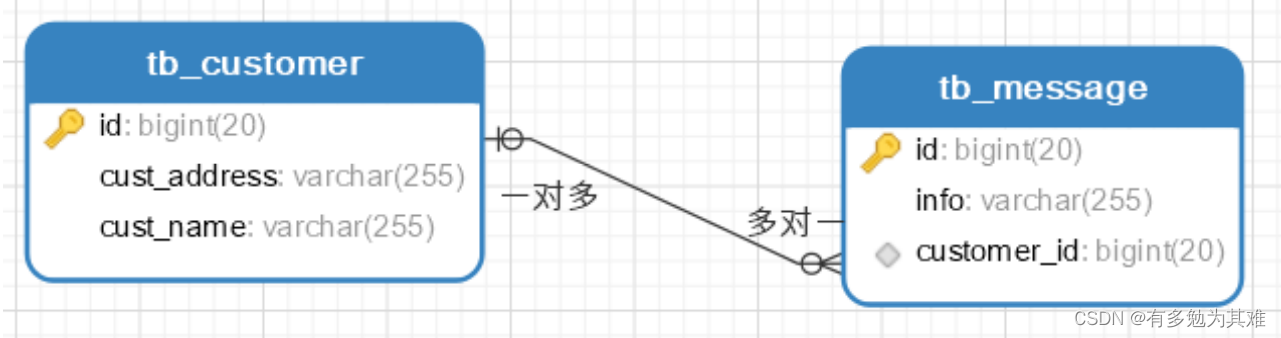
实现:
- 配置管理关系
@OneToMany
@JoinColumn(name=“customer_id”)
// 一对多
// fetch 默认是懒加载 懒加载的优点( 提高查询性能)
@OneToMany(cascade = CascadeType.ALL,fetch = FetchType.LAZY)
@JoinColumn(name="customer_id")
private List<Message> messages;
- 配置关联操作:
//一对多
//fetch默认是懒加载
@OneToMany(cascade = cascadeType.ALL,fetch = FetchType.EAGER)
@JoinColumn(name="customer_id")
private List<Message> messages;
测试:
@ContextConfiguration(classes = SpringDataJPAConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class OneToManyTest {
@Autowired
CustomerRepository repository;
// 插入
@Test
public void testC(){
List<Message> messageList=new ArrayList<>();
messageList.add(new Message("您好"));
messageList.add(new Message("在吗?"));
Customer customer = new Customer();
customer.setCustName("徐庶帅哥");
customer.setMessages(messageList);
repository.save(customer);
}
// 插入
@Test
@Transactional(readOnly = true)
public void testR(){
// 懒加载过程:
// 1.findById 只会查询Customer 和其他关联的立即加载
Optional<Customer> customer = repository.findById(1L);
System.out.println("=====================");
// 由于输出, 会自动调用customer.toString()
System.out.println(customer);
}
// 插入
@Test
public void testD(){
repository.deleteById(2L);
}
@Test
@Transactional
@Commit
public void testU(){
Optional<Customer> customer = repository.findById(19L);
customer.get().setCustName("xxx");
}
}
多对一
实现:
- 配置管理关系
@ManyToOne
@JoinColumn(name=“customer_id”)
@ManyToOne
@JoinColumn(name="customer_id")
private List<Message> message;
@ManyToOne
@JoinColumn(name="customer_id")
private Customer customer
- 配置关联操作:
// 单向多对多
@ManyToMany(cascade = CascadeType.ALL)
/*中间表需要通过@JoinTable来维护外键:(不设置也会自动生成)- name 指定中间表的名称
- joinColumns 设置本表的外键名称
- inverseJoinColumns 设置关联表的外键名称
- */
@JoinTable(
name=“tb_customer_role”,
joinColumns = {@JoinColumn(name=“c_id”)},
inverseJoinColumns = {@JoinColumn(name=“r_id”)}
)
private List roles;
测试:
@ContextConfiguration(classes = SpringDataJPAConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class ManyToOneTest {
@Autowired
MessageRepository repository;
// 多对一 插入
// 得出: 当插入"多"的数据的时候,使用多对一的关联关系是更加合理
@Test
public void testC(){
// 一
Customer customer = new Customer();
customer.setCustName("司马懿");
// 多
List<Message> list=new ArrayList<>();
list.add(new Message("你好",customer));
list.add(new Message("在吗?",customer));
repository.saveAll(list);
}
// 多对一:根据客户id查询对应的所有信息
// 通过“一”进行条件查询, 在一对多中实现是更合理的
@Test
public void testR(){
Customer customer = new Customer();
customer.setCustId(1L);
customer.setCustName("xxx");
List<Message> messages = repository.findByCustomer(customer);
// 隐式调用toString()
System.out.println(messages);
}
@Test
public void testD(){
Customer customer = new Customer();
customer.setCustId(1L);
List<Message> messages = repository.findByCustomer(customer);
repository.deleteAll(messages);
}
}
多对多
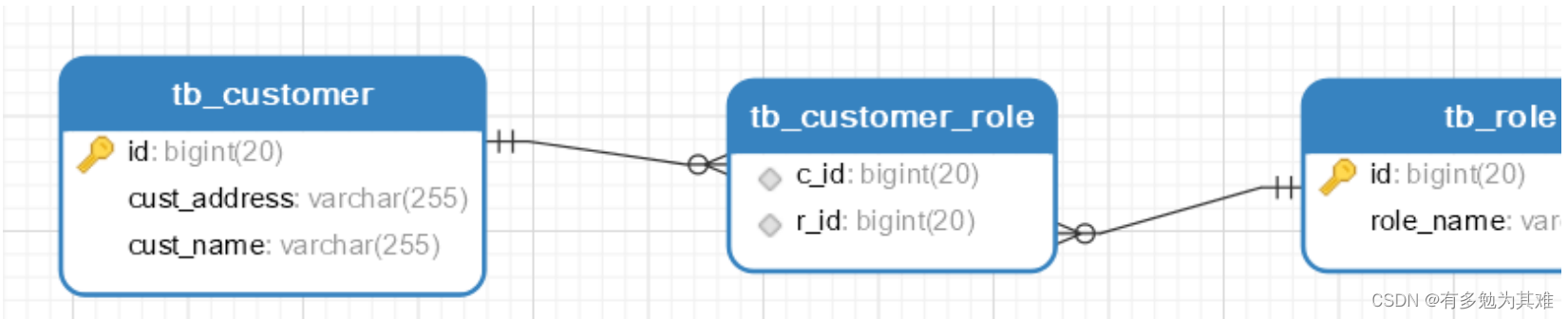
- 配置管理关系
@ManyToMany
@JoinColumn(name=“customer_id”)
@ManyToMany(cascade = CascadeType.ALL)
private List<Role> roles;
- 配置关联操作:
// 单向多对多
@ManyToMany(cascade = CascadeType.ALL)
/*中间表需要通过@JoinTable来维护外键:(不设置也会自动生成)
* name 指定中间表的名称
* joinColumns 设置本表的外键名称
* inverseJoinColumns 设置关联表的外键名称
* */
@JoinTable(
name="tb_customer_role",
joinColumns = {@JoinColumn(name="c_id")},
inverseJoinColumns = {@JoinColumn(name="r_id")}
)
private List<Role> roles;
- 测试
// 保存
/*
1.如果保存的关联数据 希望使用已有的 ,就需要从数据库中查出来(持久状态)。否则 提示 游离状态不能持久化
2.如果一个业务方法有多个持久化操作, 记得加上@Transactional ,否则不能共用一个session
3. 在单元测试中用到了@Transactional , 如果有增删改的操作一定要加@Commit
4. 单元测试会认为你的事务方法@Transactional, 只是测试而已, 它不会为你提交事务, 需要单独加上 @Commit
*/
@Test
@Transactional
@Commit
public void testC() {
List<Role> roles=new ArrayList<>();
roles.add(roleRepository.findById(9L).get());
roles.add(roleRepository.findById(10L).get());
Customer customer = new Customer();
customer.setCustName("诸葛");
customer.setRoles(roles);
repository.save(customer);
}
@Test
@Transactional(readOnly = true)
public void testR() {
System.out.println(repository.findById(14L));
//repository.save(customer);
}
/*
注意加上
@Transactional
@Commit
多对多其实不适合删除, 因为经常出现数据出现可能除了和当前这端关联还会关联另一端,此时删除就会: ConstraintViolationException。
要删除, 要保证没有额外其他另一端数据关联 42
*/
@Test
@Transactional
@Commit
public void testD() {
Optional<Customer> customer = repository.findById(14L);
repository.delete(customer.get());
}
实体类:
Account:
/**
*
* 一对一
* 一个客户对一个账户
*/
@Entity
@Table(name="tb_account")
@Data
/*@Getter // 生成所有属性的get方法
@Setter // 生成所有属性的set方法
@RequiredArgsConstructor // 生成final属性的构造函数, 如果没有final就是无参构造函数
@EqualsAndHashCode*/
public class Account {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
private String password;
@OneToOne
@JoinColumn(name="customer_id")
private Customer customer;
}
Customer:
@Entity // 作为hibernate 实体类
@Table(name = "tb_customer") // 映射的表明
@Data
@EntityListeners(AuditingEntityListener.class)
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Long custId; //客户的主键
@Column(name = "cust_name")
private String custName;//客户名称
@Column(name="cust_address")
private String custAddress;//客户地址
// 单向关联 一对一
/*
* cascade 设置关联操作
* ALL, 所有持久化操作
PERSIST 只有插入才会执行关联操作
MERGE, 只有修改才会执行关联操作
REMOVE, 只有删除才会执行关联操作
fetch 设置是否懒加载
EAGER 立即加载(默认)
LAZY 懒加载( 直到用到对象才会进行查询,因为不是所有的关联对象 都需要用到)
orphanRemoval 关联移除(通常在修改的时候会用到)
一旦把关联的数据设置null ,或者修改为其他的关联数据, 如果想删除关联数据, 就可以设置true
optional 限制关联的对象不能为null
true 可以为null(默认 ) false 不能为null
mappedBy 将外键约束执行另一方维护(通常在双向关联关系中,会放弃一方的外键约束)
值= 另一方关联属性名
**/
@OneToOne(mappedBy = "customer",
cascade = CascadeType.ALL,fetch = FetchType.LAZY,orphanRemoval=true/*,optional=false*/)
// 设置外键的字段名
@JoinColumn(name="account_id")
private Account account;
// 一对多
// fetch 默认是懒加载 懒加载的优点( 提高查询性能)
@OneToMany(cascade = CascadeType.ALL,fetch = FetchType.LAZY)
@JoinColumn(name="customer_id")
private List<Message> messages;
// @Override
// public String toString() {
// return "Customer{" +
// "custId=" + custId +
// ", custName='" + custName + '\'' +
// ", custAddress='" + custAddress + '\'' +
// ", account=" + account +
// ", messages=" + messages.toString() + // 会用到懒加载的数据, 用到的时候就会执行懒加载查询
// '}';
// }
// 单向多对多
@ManyToMany(cascade = CascadeType.ALL)
/*中间表需要通过@JoinTable来维护外键:(不设置也会自动生成)
* name 指定中间表的名称
* joinColumns 设置本表的外键名称
* inverseJoinColumns 设置关联表的外键名称
* */
@JoinTable(
name="tb_customer_role",
joinColumns = {@JoinColumn(name="c_id")},
inverseJoinColumns = {@JoinColumn(name="r_id")}
)
private List<Role> roles;
private @Version Long version;
@CreatedBy
String createdBy;
@LastModifiedBy
String modifiedBy;
/**
* 实体创建时间
*/
@Temporal(TemporalType.TIMESTAMP)
@CreatedDate
protected Date dateCreated = new Date();
/**
* 实体修改时间
*/
@Temporal(TemporalType.TIMESTAMP)
@LastModifiedDate
protected Date dateModified = new Date();
}
Message:
/***
* 一(客户)对多(信息)
*/
@Entity
@Table(name="tb_message")
@Data
public class Message {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String info;
public Message(String info) {
this.info = info;
}
public Message(String info, Customer customer) {
this.info = info;
this.customer = customer;
}
// 一定要有、否则查询就会有问题
public Message() {
}
// 多对一
@ManyToOne(cascade = {CascadeType.PERSIST,CascadeType.REMOVE})
@JoinColumn(name="customer_id")
private Customer customer;
@Override
public String toString() {
return "Message{" +
"id=" + id +
", info='" + info + '\'' +
", customerId=" + customer.getCustId() +
", customerName=" + customer.getCustName() +
'}';
}
}
Role:
/***
* 多(用户)对多(角色)
*/
@Entity
@Table(name="tb_role")
@Data
public class Role {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name="role_name")
private String rName;
public Role(String rName) {
this.rName = rName;
}
public Role(Long id, String rName) {
this.id = id;
this.rName = rName;
}
public Role() {
}
@ManyToMany(cascade = CascadeType.ALL)
private List<Role> roles;
}
乐观锁
hibernate
防并发修改
//需要加锁的字段加上@Version
private @Version Long version;
审计
如何使用审计功能
首先申明实体类,需要在类上加上注解@EntityListeners(AuditingEntityListener.class),其次在application启动类中加上注解 EnableJpaAuditing,同时在需要的字段上加上@CreatedDate、@CreatedBy、@LastModifiedDate、@LastModifiedBy等注解。 这个时候,在jpa.save方法被调用的时候,时间字段会自动设置并插入数据库,但是CreatedBy和LastModifiedBy并没有赋值,因为需要 实现AuditorAware接口来返回你需要插入的值。
- 编写AuditorAware
/**
监听
@CreatedBy
@LastModifiedBy
自动注入用户名
*/
@Configuration
public class UserAuditorAware implements AuditorAware<String> {
@Override
public Optional<String> getCurrentAuditor() {
//TODO: 根据实际情况取真实用户
return Optional.of("admin");
}
}
- 在实体类中声明@EntityListeners和相应的注解
考虑到所有实体都需要声明,就写在BaseEntityModel 中
@MappedSuperclass
@EntityListeners(AuditingEntityListener.class)
public class BaseEntityModel implements Serializable {
private static final long serialVersionUID = ‐6163675075289529459L;
@JsonIgnore
String entityName = this.getClass().getSimpleName();
@CreatedBy
String createdBy;
@LastModifiedBy
String modifiedBy;
/**
* 实体创建时间
*/
@Temporal(TemporalType.TIMESTAMP)
@CreatedDate
protected Date dateCreated = new Date();
/**
* 实体修改时间
*/
@Temporal(TemporalType.TIMESTAMP)
@LastModifiedDate
protected Date dateModified = new Date();
//todo 省略getter setter
}
- 在Application 中启用审计@EnableJpaAuditing
@EnableJpaAuditing
<!‐‐spring‐test ‐‐>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring‐aspects</artifactId>
<version>5.3.10</version>
<scope>test</scope>
</dependency>
经过测试如果你的实体类上面的多个字段使用了@CreatedBy这样的注解,只会有一个生效,也就是说在一次请求中,只会被调用一 次
原理
- 源码(难道)
- 对java高级知识 反射、动态代理。
- 对spring源码有一定了解
- 尽量当做之前没有学习过任何一个源码框架来进行讲解
- 手写核心机制的源码
- 总结、画图
- 先关注主线、 细节
- 记关键点
Repository原理
- 核心机制:
- 动态代理 :
- JdkDynamicAopProxy#invoke
- 调用JPA的Repository统一实现
- SimpleJpaRepository
- 就是去通过JPA的API完成的持久化操作
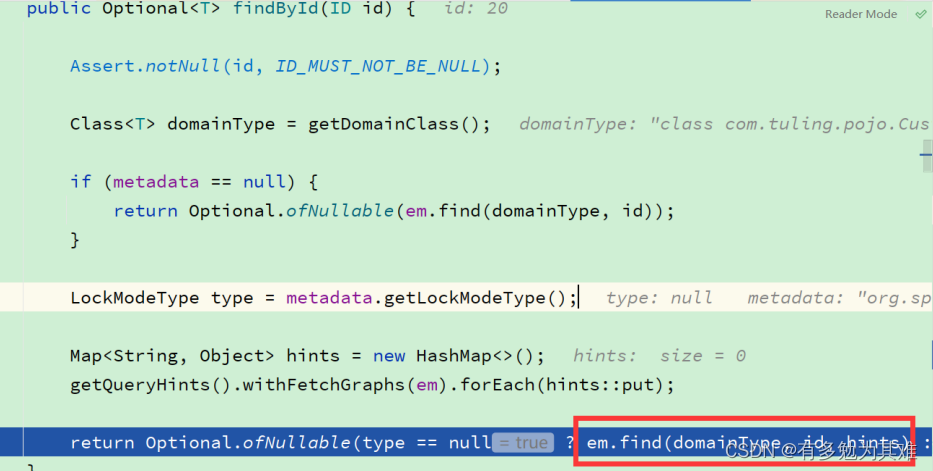
- SimpleJpaRepository
- 动态代理 :
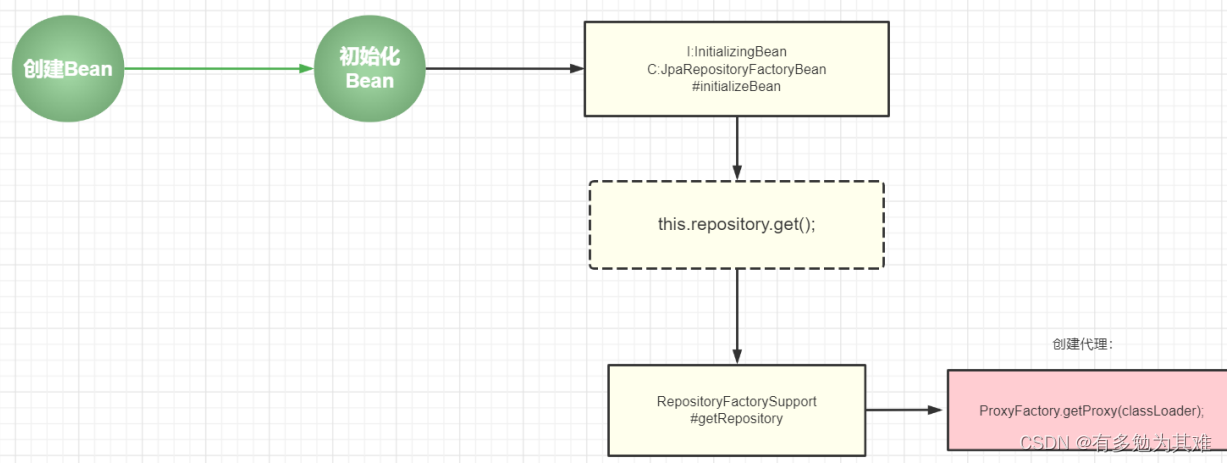
Spring整合jpa原理
手写核心流程
1. Spring怎么管理Repository( 怎么创建的Repository的Bean)
- @EnableJpaRepositories(basePackages=“com.tuling.repositories”)
- Spring容器启动的时候ioc 容器加载 根据 “com.tuling.repositories” 去创建Bean
Exception in thread "main" org.springframework.beans.factory.NoSuchBeanDefinitionException:
No qualifying bean of type 'com.tuling.repositories.CustomerRepository' available
- 没有找到Bean 解决思路: 应用层面:是不是配置不正确 ,配置正确 , 排除 底层层面:是不是spring底层扫描 排除。 (Bean —>对象)
- 同自定义扫描器, 让它将接口包含在内 , (必须实现Repository)
重写isCandidateComponent
@Override
protected boolean isCandidateComponent(AnnotatedBeanDefinition beanDefinition) {
AnnotationMetadata metadata = beanDefinition.getMetadata();
return metadata.isInterface();
}
- 实现BeanDefinitionRegistryPostProcessor ,动态注册BeanDefinition
调用自定义扫描器的scan 进行扫描
2. Spring怎么将动态代理创建bean
怎么将repository的BeanDefinition和动态代理结合:
有什么方式可以随意去控制bean实例化过程。
@Component
@Bean
FacotryBean动态设置Repository的接口类型, getObject() 自由控制实例化过程 —> 创建动态代理
Spring Data Jpa源码过程:
- @EnableJpaRepositories(basePackages=“com.tuling.repositories”)
- @Import(JpaRepositoriesRegistrar.class)
- JpaRepositoriesRegistrar实现了ImportBeanDefinitionRegistrar , 就拥有了动态注册 BeanDefinition的能力 = BeanDefinitionRegistryPostProcessor的功能
- 自定义扫描器RepositoryComponentProvider,重写排除接口的方法 isCandidateComponent
- 根据扫描成功候选BeanDefinition重写创建beanDefintion
- 设置新的beanDefintion为JpaRepositoryFactoryBean
- JpaRepositoryFactoryBean是一个BeanFactory
- JpaRepositoryFactoryBean 会创建动态代理
SpringBoot+SpringData Jpa 依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring‐boot‐starter‐data‐jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql‐connector‐java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring‐boot‐starter‐test</artifactId>
<scope>test</scope>
</dependency>
常用配置:
spring:
jpa:
hibernate:
# create ----每次运行该程序,没有表格会新建表格,表内有数据会清空;
# create-drop ----每次程序结束的时候会清空表
# update ---- 每次运行程序,没有表格会新建表格,表内有数据不会清空,只会更新
# validate ---- 运行程序会校验数据与数据库的字段类型是否相同,不同会报错。
# none —禁用 ddl 处理
ddl-auto: update
# 显示sql在控制台
show-sql: true
datasource:
url: jdbc:mysql://localhost:3306/springdata_jpa?serverTimezone=UTC
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
可配置项:
| 配置 | 说明 |
|---|---|
| spring.jpa.database | 要操作的目标数据库,默认自动检测。也可以使用"databasePlatform"属性进行设置。 |
| spring.jpa.database-platform | 要操作的目标数据库的名称,默认情况下自动检测。也可以使用“数据库"枚举进行设置。 |
| spring.jpa.generate-ddl | 是否在启动时初始化架构。true时会检测是否存在,不存在创建,存在更新,false关闭 |
| spring.jpa.hibernate.ddl-auto | DDL模式。这实际上是"hibernate.hbm2ddl.auto"属性的快捷方式。使用嵌入式数据库且未检测到模式管理器时,默认为"create-drop"。否则,默认为"无"。 |
| spring.jpa.hibernate.naming.implicit-strategy | 隐式命名策略的完全限定名称。 |
| spring.jpa.hibernate.naming.physical-strategy | 物理命名策略的完全限定名称。 |
| spring.jpa.hibernate.use-new-id-generator-mappings | 是否为AUTO、TABLE和SEQUENCE使用Hibernate较新的 ldentifierGenerator。这实际上是"hibernate.id.new_generator_mappings"属性的快捷方式。未指定时将默认为"true". |
| spring.jpa.mapping-resources | 映射资源(相当于persistence.xml 中的"mapping-file"条目)。 |
| spring.jpa.open-in-view | 默认true,注册OpenEntityManagerlnViewlnterceptor。将JPA EntityManager绑定到线程以完成请求的整个处理。 |
| spring.jpa.properties.* | 要在JPA提供程序上设置的其他本机属性。 |
| spring.jpa.show-sql | false是否启用SQL语句的日志记录。 |
- jpa.generate-ddl和jpa.hibernate.ddl-auto
jpa.generate-ddl和jpa.hibernate.ddl-auto都可以控制是否执行datasource.schema脚本,来初始化数据库结构,只要有一个为可执行 状态就会执行,比如jpa.generate-ddl:true或jpa.generate-ddl:update,并没有相互制约上下级的关系。 要想不执行,两者都必须是不可执行状态,比如false和none。 采用implicit-strategy和physical-strategy两个配置项分别控制命名策略 - naming.implicit-strategy和naming.physical-strategy
spring.jpa.hibernate.naming.implicit‐strategy=org.hibernate.boot.model.naming.ImplicitNamingStrategyJpaCompliantImpl
spring.jpa.hibernate.naming.physical‐strategy=org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
- implicit-strategy和physical-strategy的区别
- implicit-strategy负责模型对象层次的处理,将对象模型处理为逻辑名称。physical-strategy负责映射成真实的数据名称的处理, 将上述的逻辑名称处理为物理名称。
- 当没有使用@Table和@Column注解时,implicit-strategy配置项才会被使用,当对象模型中已经指定时,implicit-strategy并 不会起作用。
physical-strategy一定会被应用,与对象模型中是否显式地指定列名或者已经被隐式决定无关。
- implicit-strategy逻辑名称命名策略 有五个配置值:
不会去改:
ImplicitNamingStrategyJpaCompliantImpl:默认的命名策略,兼容JPA 2.0的规范;
ImplicitNamingStrategyLegacyHbmImpl:兼容Hibernate老版本中的命名规范;
ImplicitNamingStrategyLegacyJpaImpl:兼容JPA 1.0规范中的命名规范
ImplicitNamingStrategyComponentPathImpl:大部分与ImplicitNamingStrategyJpaCompliantImpl,但是对于@Embedded等注解标志的 组件处理是通过使用attributePath完成的,
因此如果我们在使用@Embedded注解的时候,如果要指定命名规范,可以直接继承这个类来实现;
默认为ImplicitNamingStrategyJpaCompliantImpl,后四者均继承自它。
3、physical-strategy物理名称命名策略
有两个配置值:
# 直接映射,不会做过多的处理
org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
# 表名,字段为小写,当有大写字母的时候会添加下划线分隔符号org.springframework.boot.orm.jpa.hibernate.SpringPhysicalNamingStrategy
# 默认为SpringPhysicalNamingStrategy
自动配置原理
通过JpaBaseConfiguration去配置我们以前集成spring data jpa的基本@Bean
JpaRepositoriesAutoConfiguration
@Import(JpaRepositoriesImportSelector.class)
JpaRepositoriesImportSelector又会注册一个ImportBeanDefinitionRegistrar 其实就是JpaRepositoriesRegistrar
‐‐‐‐JpaRepositoriesRegistrar 跟通过@EnableJpaRepositories 导入进来的组件是同一个
就相当于@EnableJpaRepositories
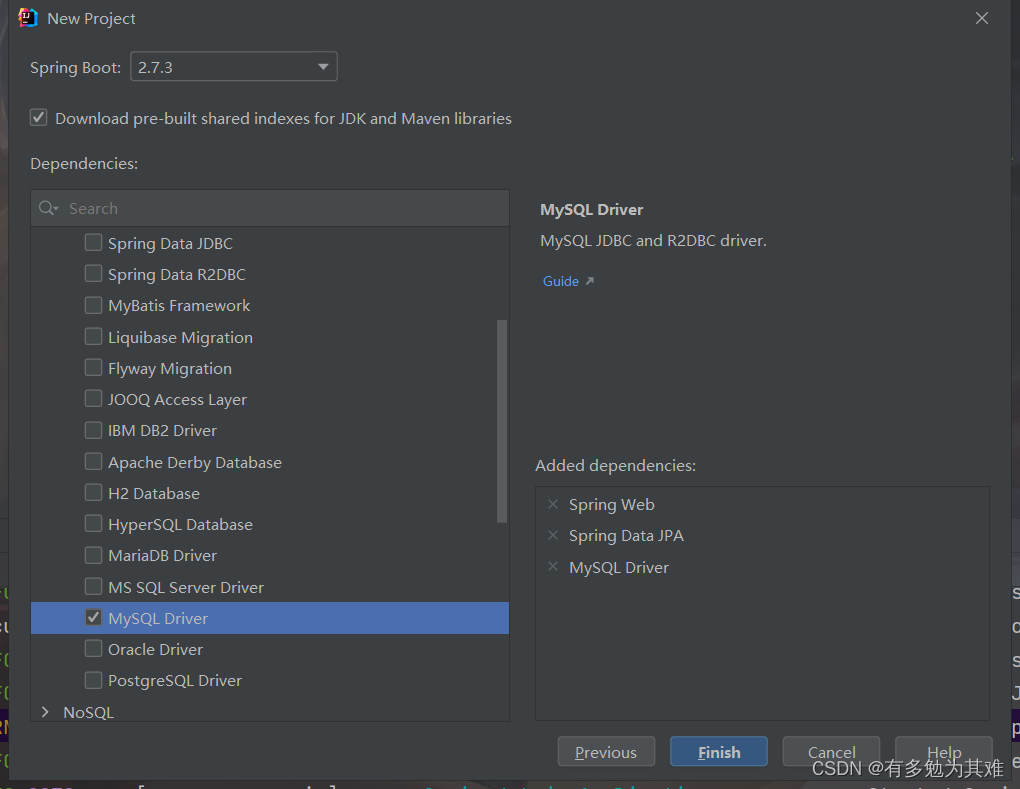
SpringBoot整合Spring Data Jpa
-
创建项目选择依赖web、jpa、mysq依赖
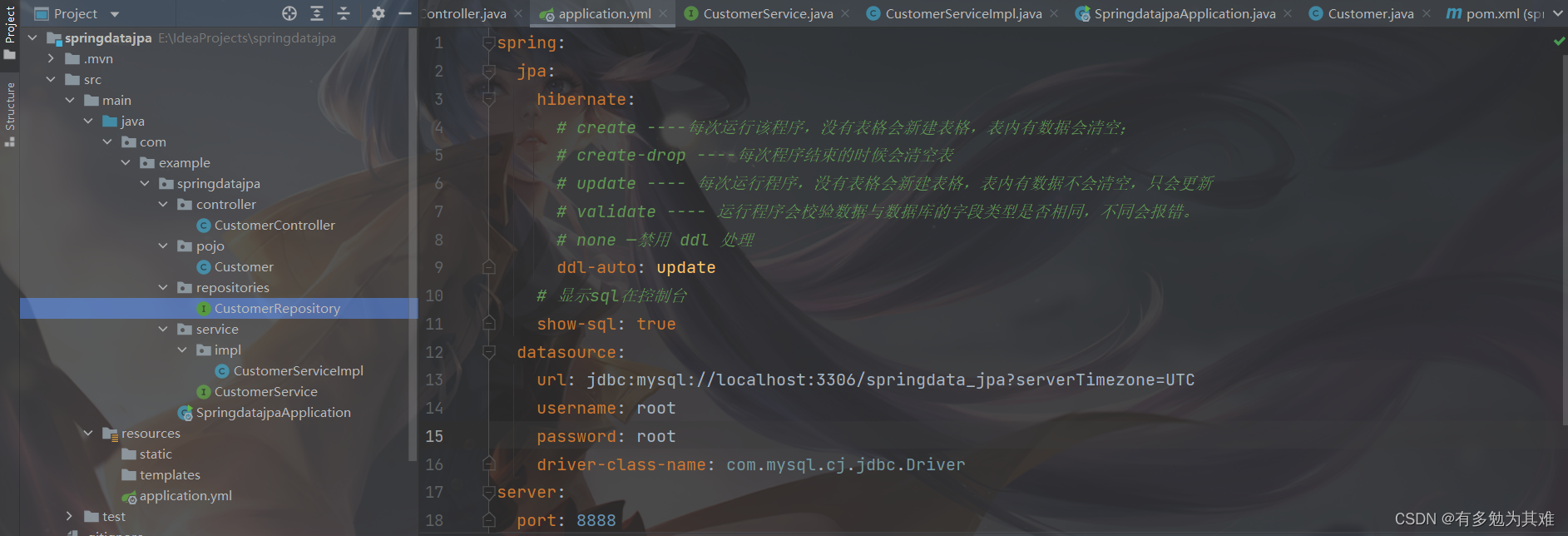
-
创建实体类、Controller、service、Repository
Customer:
package com.example.springdatajpa.pojo;
import lombok.Data;
import javax.persistence.*;
/**
* 客户实体类
* @author huangren
*/
@Entity // 作为hibernate 实体类
@Table(name = "tb_customer") // 映射的表明
@Data
public class Customer {
/**
* 客户的主键
*/
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Long custId;
/**
* 客户名称
*/
@Column(name = "cust_name")
private String custName;
/**
* 客户地址
*/
@Column(name="cust_address")
private String custAddress;
}
CustomerService:
package com.example.springdatajpa.service;
import com.example.springdatajpa.pojo.Customer;
public interface CustomerService{
Iterable<Customer> getAll();
}
CustomerServiceImpl:
package com.example.springdatajpa.service.impl;
import com.example.springdatajpa.pojo.Customer;
import com.example.springdatajpa.repositories.CustomerRepository;
import com.example.springdatajpa.service.CustomerService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class CustomerServiceImpl implements CustomerService {
@Autowired
private CustomerRepository customerRepository;
@Override
public Iterable<Customer> getAll() {
return customerRepository.findAll();
}
}
CustomerRepository:
package com.example.springdatajpa.repositories;
import com.example.springdatajpa.pojo.Customer;
import org.springframework.data.repository.PagingAndSortingRepository;
import org.springframework.stereotype.Component;
@Component
public interface CustomerRepository extends PagingAndSortingRepository<Customer,Long> {
}
CustomerController:
package com.example.springdatajpa.controller;
import com.example.springdatajpa.pojo.Customer;
import com.example.springdatajpa.service.CustomerService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/get")
public class CustomerController {
@Autowired
private CustomerService customerService;
@GetMapping("/customer/all")
public Iterable<Customer> getAll() {
return customerService.getAll();
}
}
application.yml:
spring:
jpa:
hibernate:
# create ----每次运行该程序,没有表格会新建表格,表内有数据会清空;
# create-drop ----每次程序结束的时候会清空表
# update ---- 每次运行程序,没有表格会新建表格,表内有数据不会清空,只会更新
# validate ---- 运行程序会校验数据与数据库的字段类型是否相同,不同会报错。
# none —禁用 ddl 处理
ddl-auto: update
# 显示sql在控制台
show-sql: true
datasource:
url: jdbc:mysql://localhost:3306/springdata_jpa?serverTimezone=UTC
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
server:
port: 8888
Spring Data Jpa分页和分页条件查询
/**
* 分页查询
*/
@Test
public void testQuery() {
Pageable pageable= PageRequest.of(0,5);//表示 第一页,每页5条
Page<Article> articleList=articleRepository.findAll(pageable);
System.out.println("====== 分页结果 0,5 ======");
articleList.stream().map(Objects::toString).forEach(System.out::println);
// 每页显示数量
System.out.println("每页显示数:"+articleList.getSize());
// 总页数
System.out.println("一共多少页:"+articleList.getTotalPages());
// 查询内容总数
System.out.println("一共多少条数据:"+articleList.getTotalElements());
//每页显示的内容列表
System.out.println("数据:"+articleList.getContent());
Pageable pageable1=PageRequest.of(1,5);//表示 第二页,每页5条
Page<Article> articleList1=articleRepository.findAll(pageable1);
System.out.println("====== 分页结果 1,5 ======");
articleList1.stream().map(Objects::toString).forEach(System.out::println);
// 每页显示数量
System.out.println("每页显示数:"+articleList1.getSize());
// 总页数
System.out.println("一共多少页:"+articleList1.getTotalPages());
// 查询内容总数
System.out.println("一共多少条数据:"+articleList1.getTotalElements());
//每页显示的内容列表
System.out.println("数据:"+articleList1.getContent());
}
/**
* 条件分页查询
*/
@Test
public void testQuery2() {
Article article = new Article();
article.setArticleContent("哇");
Pageable pageable = PageRequest.of(1 - 1, 5, Sort.by("dateCreated").descending());
Specification<Article> specification = (root, query, criteriaBuilder) -> {
List<Predicate> list = new ArrayList<>();
if (article.getArticleContent() != null) {
list.add(criteriaBuilder.like(root.get("articleContent").as(String.class), "%" + article.getArticleContent().trim() + "%"));
}
Predicate[] p = new Predicate[list.size()];
return criteriaBuilder.and(list.toArray(p));
};
Page<Article> articlePage = articleRepository.findAll(specification, pageable);
// 每页显示数量
System.out.println("每页显示数:"+articlePage.getSize());
// 总页数
System.out.println("一共多少页:"+articlePage.getTotalPages());
// 查询内容总数
System.out.println("一共多少条数据:"+articlePage.getTotalElements());
//每页显示的内容列表
System.out.println("数据:"+articlePage.getContent());
}
Spring Data Jpa条件查询
List<Long> OnShelfIds = commodityFeign.checkOnShelfCommodityRep(popularIds);
Specification<PopularCommodityDO> specification = (root, query, criteriaBuilder) -> {
List<Predicate> list = Lists.newArrayList();
list.add(criteriaBuilder.equal(root.get("type").as(Integer.class), finalType));
list.add(criteriaBuilder.in(root.get("commodityId")).value(OnShelfIds));
Predicate[] p = new Predicate[list.size()];
return criteriaBuilder.and(list.toArray(p));
};
List<PopularCommodityDO> commodityList = popularCommodityRepository.findAll(specification);
Spring Data Jpa多表连接查询
由于jpa关联的表是不能直接通过外键名称直接查询的,所以只能用该方法进行查询
Specification<MemberLoseCreditDO> specification = (root, query, criteriaBuilder) -> {
List<Predicate> list = Lists.newArrayList();
//join第一个参数为关联对象的属性名称,第二个参数为连接查询的方式(left,inner,right)
Join<MemberLoseCreditDO, MemberDO> memberJoin = root.join("member", JoinType.LEFT);
if(StringUtils.isNotBlank(creditVO.getName())) {
list.add(criteriaBuilder.like(memberJoin.get("name").as(String.class), "%" + creditVO.getName().trim() + "%"));
}
Join<MemberDO, RoleDO> roleJoin = memberJoin.join("roles", JoinType.LEFT);
if(creditVO.getMemberRole() != null){
Join<MemberTypeDO, RoleDO> roleTypeJoin = roleJoin.join("roleType", JoinType.LEFT);
list.add(criteriaBuilder.equal(roleTypeJoin.get("typeEnum").as(Integer.class), creditVO.getMemberRole()));
}
if(creditVO.getMemberTypeId() != null){
Join<MemberTypeDO, RoleDO> memberTypeJoin = roleJoin.join("memberType", JoinType.LEFT);
list.add(criteriaBuilder.equal(memberTypeJoin.get("typeEnum").as(Integer.class),creditVO.getMemberTypeId()));
}
list.add(criteriaBuilder.equal(root.get("status").as(Integer.class), 1));
if(StringUtils.isNotBlank(creditVO.getReason())){
list.add(criteriaBuilder.like(root.get("reason").as(String.class), "%"+creditVO.getReason().trim()+"%"));
}
if(creditVO.getRestriction() != null){
list.add(criteriaBuilder.equal(root.get("restriction").as(Integer.class), creditVO.getRestriction()));
}
query.distinct(true);
Predicate[] p = new Predicate[list.size()];
return criteriaBuilder.and(list.toArray(p));
};
Page<MemberLoseCreditDO> pageList = memberLoseCreditRepository.findAll(specification, page);
Spring Data Jpa同时使用and和or
这个方法多个or条件有效,只有一个的话,用and连接了,多个才会有括号
1. 同时使用and和or,并左连接查询
Long memberId = sysUser.getMemberId();
List<CowsCommodityRequestPage.WeightPair> weightPairs = request.getWeightPairs();
List<Long> categoryIds = request.getCustomerCategoryIds();
Pageable page = PageRequest.of(request.getCurrent() - 1, request.getPageSize(), Sort.by("createTime").descending());
Specification<Commodity> specification = (root, query, criteriaBuilder) -> {
List<Predicate> listAnd = new ArrayList<>();//组装and语句
if (memberId != null) {
listAnd.add(criteriaBuilder.equal(root.get("memberId").as(Long.class), memberId));
}
if (CollUtil.isNotEmpty(categoryIds)) {
// 连表查询会员品类id
Join<Object, Object> categoryJoin = root.join("customerCategory", JoinType.LEFT);
List<Long> categoryIdList = commodityRepository.getCategoryIdByCustomerCategoryId(categoryIds);
listAnd.add(criteriaBuilder.in(categoryJoin.get("id")).value(categoryIdList));
}
Predicate predicateAnd = criteriaBuilder.and(listAnd.toArray(new Predicate[listAnd.size()])); //AND查询加入查询条件
List<Predicate> listOr = new ArrayList<>();///组装or语句
// 查询重量区间在maxWeightInterval和minWeightInterval之间
if (CollUtil.isNotEmpty(weightPairs)) {
request.getWeightPairs().forEach(s->{
//千克转斤
Double maxWeightInterval = s.getMaxWeightInterval() == null ? 0 : s.getMaxWeightInterval() * 2;
Double minWeightInterval = s.getMinWeightInterval() == null ? 0 : s.getMinWeightInterval() * 2;
if (maxWeightInterval > 0 && minWeightInterval > 0) {
// 小于等于
listOr.add(criteriaBuilder.lessThanOrEqualTo(root.get("maxWeightInterval").as(Double.class), maxWeightInterval));
// 大于等于
listOr.add(criteriaBuilder.greaterThanOrEqualTo(root.get("minWeightInterval").as(Double.class), minWeightInterval));
} else {
if (minWeightInterval > 0) {
listOr.add(criteriaBuilder.greaterThanOrEqualTo(root.get("minWeightInterval").as(Double.class), minWeightInterval));
}
if ( maxWeightInterval > 0) {
listOr.add(criteriaBuilder.lessThanOrEqualTo(root.get("maxWeightInterval").as(Double.class), maxWeightInterval));
}
}
});
}
if (CollUtil.isNotEmpty(listOr)) {
Predicate predicateOR = criteriaBuilder.or(listOr.toArray(new Predicate[listOr.size()])); //OR查询加入查询条件
return query.where(predicateAnd,predicateOR).getRestriction();
} else {
return query.where(predicateAnd).getRestriction();
}
};
Page<Commodity> pageList = commodityRepository.findAll(specification, page);
2. 同时使用and和or
Long memberId = requestPage.getMemberId();
Long memberRoleId = requestPage.getMemberRoleId();
Date createTime = requestPage.getCreateTime();
String content = requestPage.getContent();
Pageable page = PageRequest.of(requestPage.getCurrent() - 1, requestPage.getPageSize(),Sort.by("createTime").descending());
Specification<OpinionDO> specification = (root, query, criteriaBuilder) -> {
List<Predicate> listAnd = new ArrayList<>();//组装and语句
if (memberId != null) {
listAnd.add(criteriaBuilder.equal(root.get("memberId").as(Long.class), memberId));
}
Predicate predicateAnd = criteriaBuilder.and(listAnd.toArray(new Predicate[listAnd.size()])); //AND查询加入查询条件
List<Predicate> listOr = new ArrayList<>();///组装or语句
if (memberRoleId != null) {
listOr.add(criteriaBuilder.equal(root.get("memberRoleId").as(Long.class), memberRoleId));
}
if (StrUtil.isNotBlank(content)) {
listOr.add(criteriaBuilder.like(root.get("content").as(String.class), "%" + content + "%"));
}
if (CollUtil.isNotEmpty(listOr)) {
Predicate predicateOR = criteriaBuilder.or(listOr.toArray(new Predicate[listOr.size()])); //OR查询加入查询条件
return query.where(predicateAnd,predicateOR).getRestriction();
} else {
return query.where(predicateAnd).getRestriction();
}
};
Page<OpinionDO> all = opinionRepository.findAll(specification, page);
select opiniondo0_.id as id1_2_, opiniondo0_.content as content2_2_, opiniondo0_.create_time as create_t3_2_, opiniondo0_.img_urls as img_urls4_2_, opiniondo0_.member_id as member_i5_2_, opiniondo0_.member_role_id as member_r6_2_ from ms_mc_opinion opiniondo0_ where (opiniondo0_.member_role_id=2 or opiniondo0_.content like ?) and opiniondo0_.member_id=1 order by opiniondo0_.create_time desc limit ?
Hibernate: select count(opiniondo0_.id) as col_0_0_ from ms_mc_opinion opiniondo0_ where (opiniondo0_.member_role_id=2 or opiniondo0_.content like ?) and opiniondo0_.member_id=1
3. 查询两个字段的or
if (StringUtils.hasLength(pageVO.getName())) {
Predicate orderNoPredicate = criteriaBuilder.like(root.get("orderNo").as(String.class), "%" + pageVO.getName() + "%");
Predicate namePredicate = criteriaBuilder.like(root.get("allCommodityName").as(String.class), "%" + pageVO.getName() + "%");
list.add(criteriaBuilder.or(orderNoPredicate, namePredicate));
}
4. 其他方式
//标题、内容 模糊搜索
list.add(criteriaBuilder.or(criteriaBuilder.like(root.get("title").as(String.class), "%"+request.getContnt()+"%"),criteriaBuilder.like(root.get("content").as(String.class), "%"+request.getContnt()+"%")));
Spring Data Jpa自动添加数据库注释
添加依赖
<dependency>
<groupId>com.github.biyanwen</groupId>
<artifactId>jpa-comment-spring-boot-starter</artifactId>
<version>1.0.0</version>
</dependency>
这个是根据swagger注解来实现的
Springboot整合Swaggerspringboot整合swagger
添加配置
spring.jpa.hibernate.ddl-auto=update
实体类中进行配置
@ApiModelProperty(value = “主键”)
新建表或者字段的时候才会触发 Jpa 自动建表/字段的功能,才会添加注释。
public class Author {
/**
* 作者 id
*/
@ApiModelProperty("作者 id")
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "author_id")
private Long authorId;
/**
* 作者 姓名
*/
@ApiModelProperty("作者 姓名")
@Column(name = "author_Name")
private String authorName;
/**
* 作者 简介
*/
@ApiModelProperty("作者 简介")
@Column(name = "author_referral")
private String authorReferral;
/**
* 实体创建时间
*/
@ApiModelProperty("实体创建时间")
@Temporal(TemporalType.TIMESTAMP)
@CreatedDate
protected Date dateCreated = new Date();
/**
* 实体修改时间
*/
@ApiModelProperty("实体修改时间")
@Temporal(TemporalType.TIMESTAMP)
@LastModifiedDate
protected Date dateModified = new Date();
}
Spring Data Jpa条件查询使用in方法
//将售后枚举存入list集合
List<Integer> sale = Arrays.asList(16,17,18);
if (request.getOrderStatus() != null && request.getOrderStatus() != 0) {
// 0:全部 1:6待付款 2:11待发货 3:13待收货 4:100已完成 5:待售后处理16,售后处理中17,售后处理成功18
// app端没有区分待售后处理16,售后处理中17,售后处理成功18,所以如果是16,17,18则使用in方法 in(16,17,18)
boolean contains = sale.contains(request.getOrderStatus());
if (!contains) {
list.add(criteriaBuilder.equal(root.get("outerStatus").as(Integer.class), request.getOrderStatus()));
} else {
list.add(criteriaBuilder.in(root.get("outerStatus")).value(sale));
}
}
排序问题
需求1:JPA 中 字段值为NULL时,不参与升序排序,放在最后
Pageable page = PageRequest.of(request.getCurrent() - 1, request.getPageSize(), Sort.by(new Sort.Order(Sort.Direction.DESC, "sendTime").nullsLast()));
或
List<Sort.Order> orders = new ArrayList<>();
Sort.Order order = new Sort.Order(Sort.Direction.DESC, "updatedAt", Sort.NullHandling.NULLS_LAST);
Sort sort = Sort.by(orders);
如果不生效只能修改配置文件
jpa:
show-sql: false
generate-ddl: false
open-in-view: true
properties:
hibernate.order_by.default_null_ordering: last
需求2:
优先排序isDefault然后再通过id排序
Pageable page = PageRequest.of(request.getCurrent() - 1, request.getPageSize(), Sort.by("isDefault","id").ascending());
demo:
List<Sort.Order> orders = new ArrayList<>();
Sort.Order sendTime = new Sort.Order(Sort.Direction.DESC, "sendTime", Sort.NullHandling.NULLS_LAST);
Sort.Order createTime = new Sort.Order(Sort.Direction.DESC, "createTime", Sort.NullHandling.NULLS_LAST);
orders.add(sendTime);
orders.add(createTime);
Pageable page = PageRequest.of(request.getCurrent() - 1, request.getPageSize(), Sort.by(orders));
//使用Specification构造模糊查询条件并查询
Specification<SmsMarketing> specification = (root, query, criteriaBuilder) -> {
List<Predicate> list = new ArrayList<>();
// 非admin
if (user != null && user.getMemberId() != 1) {
list.add(criteriaBuilder.equal(root.get("senderId").as(Long.class), user.getMemberId()));
}
if (request.getStatus() != null) {
list.add(criteriaBuilder.equal(root.get("status").as(Integer.class), request.getStatus()));
}
if (request.getSenderName() != null) {
list.add(criteriaBuilder.like(root.get("senderName").as(String.class), "%" + request.getSenderName() + "%"));
}
Predicate[] p = new Predicate[list.size()];
return criteriaBuilder.and(list.toArray(p));
};
Page<SmsMarketing> pageList = smsMarketingRepository.findAll(specification, page);
return Wrapper.success(new PageData<>(pageList.getTotalElements(), pageList.stream().map(s -> BeanUtil.copyProperties(s, SmsMarketingResponses.class)).collect(Collectors.toList())));
jpa在某个数据之间
public Wrapper<PageData<ContentPortalInfo>> page(UserLoginCacheDTO user, String platform, ContentPortalInfoPageRequest request) {
Pageable page = PageRequest.of(request.getCurrent() - 1, request.getPageSize(), Sort.by("createTime").descending());
Specification<ContentPortalInfo> specification = (root, query, criteriaBuilder) -> {
List<Predicate> list = new ArrayList<>();
if (request.getColumnType() != null) {
list.add(criteriaBuilder.equal(root.get("columnType").as(Integer.class), request.getColumnType()));
}
if (request.getStatus() != null) {
list.add(criteriaBuilder.equal(root.get("status").as(Integer.class), request.getStatus()));
}
// 查询createTime在startTime和endTime之间
if (request.getStartTime() != null && request.getEndTime() != null) {
list.add(criteriaBuilder.between(root.get("createTime").as(Long.class), request.getStartTime(), request.getEndTime()));
}
Predicate[] p = new Predicate[list.size()];
return criteriaBuilder.and(list.toArray(p));
};
Page<ContentPortalInfo> pageList = contentPortalInfoRepository.findAll(specification, page);
return Wrapper.success(new PageData<>(pageList.getTotalElements(), pageList.getContent()));
Spring Data Jpa删除和批量删除
1. deleteById()根据id删除
userRepository.deleteById(id);
2.delete()根据实体类删除
ContentNotice contentNotice = contentNoticeRepository.findById(request.getId()).orElse(null);
contentNoticeRepository.delete(contentNotice);
3. deleteAll()和deleteAllInBatch()全部删除
contentNoticeAutoPublishRepository.deleteAll();
contentNoticeAutoPublishRepository.deleteAllInBatch();
deleteAll()是删除全部,先findALL查找出来,再一条一条删除,最后提交事务。deleteAllInBatch()是删除全部,一条sql。显而易见,deleteAllInBatch()方法效率更高一些。
4.deleteAll(list)和deleteInBatch(list)批量删除一组集合数据
contentNoticeAutoPublishRepository.deleteAll(autoPublishList);
contentNoticeAutoPublishRepository.deleteInBatch(autoPublishList);
delete()方法打印的sql是一条一条删除的,而deleteInBatch()是一条sql语句删除的。
Spring Data Jpa实体类注解
1. @Entity
被Entity标注的实体类将会被JPA管理控制,在程序运行时,JPA会识别并映射到指定的数据库表
唯一参数name:指定实体类名称,默认为当前实体类的非限定名称。
若给了name属性值即@Entity(name=“pt_member_shop”),则jpa在仓储层(数据层)进行自定义查询时,所查的表名应是pt_member_shop。
如:
select s from pt_member_shop pms
一般不用指定name在@Table中指定
2. @Table
当你想生成的数据库表名与实体类名称不同时,使用 @Table(name=“数据库表名”),与@Entity标注并列使用
@Data
@Entity
@Table(schema = "public", name = "pt_member_shop")
public class MemberShop {
}
@Table中的参数(不常用)
catalog: 用于设置表所映射到的数据库的目录
schema: 用于设置表所映射到的数据库的模式
uniqueConstraints: 设置约束条件
3. @Id
@Id 用于实体类的一个属性或者属性对应的getter方法的标注,被标注的的属性将映射为数据库主键
4. @GeneratedValue
与@Id一同使用,用于标注主键的生成策略,通过 strategy 属性指定。默认是JPA自动选择合适的策略
在 javax.persistence.GenerationType 中定义了以下几种可供选择的策略:
- IDENTITY:采用数据库ID自增长的方式产生主键,Oracle 不支持这种方式。
- AUTO: JPA 自动选择合适的策略,是默认选项。
- SEQUENCE:通过序列产生主键,通过@SequenceGenerator标注指定序列名,MySQL 不支持这种方式。
- TABLE:通过表产生主键,框架借由表模拟序列产生主键,使用该策略更易于做数据库移植。
@Data
@Entity
@Table(schema = "public", name = "pt_member_shop")
public class MemberShop {
@Id
@GeneratedValue(strategy= GenerationType.IDENTITY)
private Long id;
}
5. @Basic
@Basic表示一个简单的属性到数据库表的字段的映射,对于没有任何标注的 getXxxx() 方法,默认即为@Basic(fetch=FetechType.EAGER)
@Basic参数:
- fetch 表示该属性的加载读取策略
1.1 EAGER 主动抓取 (默认为EAGER)
1.2 LAZY 延迟加载,只有用到该属性时才会去加载 - optional (默认为 true)
表示该属性是否允许为null
实际开发中暂时没有用到
6. @Column
通常置于实体的属性声明之前,可与 @Id 标注一起使用
@Column参数:
- name: 指定映射到数据库中的字段名
- unique: 是否唯一,默认为false
- nullable: 是否允许为null,默认为true
- insertable: 是否允许插入,默认为true
- updatetable: 是否允许更新,默认为true
- columnDefinition: 指定该属性映射到数据库中的实际类型,通常是自动判断,也可以使用该属性来指定类型并添加注释,还可以指定默认值。
在实际开发中,接触过的jpa项目都使用columnDefinition来指定数据库中的类型
/**
* 草稿状态,默认值为0,即false: true-是 false-否
*/
@ApiModelProperty(value = "草稿状态 true-是 false-否")
@Column(columnDefinition = "bit(1) default 0 COMMENT '草稿状态'")
private Boolean draftStatus = false;
7. @Transient
JPA会忽略该属性,不会映射到数据库中,即程序运行后数据库中将不会有该字段
/**
* 关联商品
*/
@Transient
private GoodsDetailDO goodsDetailDO;
8. @Temporal
Java中没有定义 Date 类型的精度,而数据库中,表示时间类型的数据有 DATE,TIME,TIMESTAMP三种精度
- @Temporal(TemporalType.DATE) 表示映射到数据库中的时间类型为 DATE,只有日期
- @Temporal(TemporalType.TIME) 表示映射到数据库中的时间类型为 TIME,只有时间
- @Temporal(TemporalType.TIMESTAMP) 表示映射到数据库中的时间类型为 TIMESTAMP,日期和时间都有
@Temporal(TemporalType.TIMESTAMP)
@Column(columnDefinition = "TIMESTAMP comment '提交时间'")
private Date commitTime;
9. @Embedded 和 @Embeddable
用于一个实体类要在多个不同的实体类中进行使用,而本身又不需要独立生成一个数据库表
10. @JoinColumn
定义表关联的外键字段名
常用参数有:
- name: 指定映射到数据库中的外键的字段名
- unique: 是否唯一,默认为false
- nullable: 是否允许为null,默认为true
- insertable: 是否允许插入,默认为true
- updatetable: 是否允许更新,默认为true
- columnDefinition: 指定该属性映射到数据库中的实际类型,通常是自动判断。
- foreignKey = @ForeignKey(name = “none”,value = ConstraintMode.NO_CONSTRAINT):指定外键相关信息,这里用法是指定外联关系但是不建立数据库外键
/**
* 一对一双向关联会员关系表
*/
@JsonBackReference//解决对象中存在双向引用导致的无限递归
@OneToOne(cascade = CascadeType.DETACH, fetch = FetchType.EAGER)
@JoinColumn(name="rel_id", referencedColumnName="id", foreignKey = @ForeignKey(name = "none",value = ConstraintMode.NO_CONSTRAINT))
private MemberRelationDO relation;
11. @OneToOne
参数:
-
targetEntity: 指定关联实体类型,默认为被注解的属性或方法所属的类
-
cascade 设置关联操作
- ALL, 所有持久化操作
- PERSIST 只有插入才会执行关联操作
- MERGE, 只有修改才会执行关联操作
- REMOVE, 只有删除才会执行关联操作
-
fetch 设置是否懒加载
- EAGER 立即加载(默认)
- LAZY 懒加载( 直到用到对象才会进行查询,因为不是所有的关联对象 都需要用到)
-
orphanRemoval 关联移除(通常在修改的时候会用到)
- 一旦把关联的数据设置null ,或者修改为其他的关联数据, 如果想删除关联数据, 就可以设置true
-
optional 限制关联的对象不能为null
- true 可以为null(默认 ) false 不能为null
-
mappedBy 将外键约束执行另一方维护(通常在双向关联关系中,会放弃一方的外键约束)
-
mappedBy 的值= 另一方关联属性名
mappedBy:
指定关联关系,该参数只用于关联关系被拥有方只用于双向关联@OneToOne,@OneToMany,@ManyToMany。而@ManyToOne中没有
@OneToOne(mappedBy = “xxx”) 表示xxx所对应的类为关系被拥有方,而关联的另一方为关系拥有方
关系拥有方:对应拥有外键的数据库表
关系被拥有方:对应主键被子表引用为外键的数据库表
- orphanRemoval:默认值为false
判断是否自动删除与关系拥有方不存在联系的关系被拥有方(关系被拥有方的一个主键在关系拥有方中未被引用,
当jpa执行更新操作时,是否删除数据库中此主键所对应的一条记录,若为true则删除)
12. @ManyToOne、@OneToMany
多对一(也可叫一对多,只是前后表颠倒一下而已),只有双向多对一时才用得到@OneToMany。多对一中多的一方必定是对应数据库中拥有外键的表,即是关系拥有方,@ManyToOne只用在多对一中代表多的一类中,因为mappedBy只用于关系被拥有方,所以@ManyToOne参数中不包含mappedBy。
@ManyToOne参数:
targetEntity: 指定关联实体类型,默认为被注解的属性或方法所属的类
- cascade: 级联操作策略
- CascadeType.ALL 级联所有操作
- CascadeType.PERSIST 级联新增
- CascadeType.MERGE 级联归并更新
- CascadeType.REMOVE 级联删除
- CascadeType.REFRESH 级联刷新
- CascadeType.DETACH 级联分离
fetch: fetch 表示该属性的加载读取策略(@ManyToOne 的默认值是 EAGER,@OneToMany 的默认值是 LAZY)
EAGER 主动抓取
LAZY 延迟加载,只有用到该属性时才会去加载
optional: 默认为true,关联字段是否为空
如果为false,则常与@JoinColumn一起使用
@OneToMany 参数除上述以外还有:
mappedBy: 指定关联关系,该参数只用于关联关系被拥有方
只用于双向关联@OneToOne,@OneToMany,@ManyToMany。而@ManyToOne中没有
@OneToMany(mappedBy = “xxx”)
表示xxx所对应的类为关系被拥有方,而关联的另一方为关系拥有方
关系拥有方:对应拥有外键的数据库表
关系被拥有方:对应主键被子表引用为外键的数据库表
orphanRemoval:默认值为false
判断是否自动删除与关系拥有方不存在联系的关系被拥有方(关系被拥有方的一个主键在关系拥有方中未被引用,
当jpa执行更新操作时,是否删除数据库中此主键所对应的一条记录,若为true则删除)
无论双向关联还是单向关联,数据库中均会在Emp表中自动生成一个外键(dept_d_id)
13. @ManyToMany
targetEntity: 指定关联实体类型,默认为被注解的属性或方法所属的类
cascade: 级联操作策略
1. CascadeType.ALL 级联所有操作
2. CascadeType.PERSIST 级联新增
3. CascadeType.MERGE 级联归并更新
4. CascadeType.REMOVE 级联删除
5. CascadeType.REFRESH 级联刷新
6. CascadeType.DETACH 级联分离
fetch: fetch 表示该属性的加载读取策略 (默认值为 LAZY)
- EAGER 主动抓取
- LAZY 延迟加载,只有用到该属性时才会去加载
mappedBy: 指定关联关系,该参数只用于关联关系被拥有方
只用于双向关联@OneToOne,@OneToMany,@ManyToMany。而@ManyToOne中没有。
@ManyToMany(mappedBy = “xxx”)
表示xxx所对应的类为关系被拥有方,而关联的另一方为关系拥有方:
关系拥有方:对应拥有外键的数据库表
关系被拥有方:对应主键被子表引用为外键的数据库表
14. @Enumerated
当实体类中有枚举类型的属性时,默认情况下自动生成的数据库表中对应的字段类型是枚举的索引值,是数字类型的,若希望数据库中存储的是枚举对应的String类型,在属性上加入@Enumerated(EnumType.STRING)注解即可。
15. @JsonIgnore和@JsonManagedReference/ @JsonBackReference
用于解决无限递归(StackOverflowError)@JsonIgnore并不是为了解决无限递归问题而设计的,它只是忽略了带注释的属性被序列化或反序列化。但是,如果字段之间存在双向链接,则由于会@JsonIgnore忽略带注释的属性,因此可以避免无限递归。在另一方面,@JsonManagedReference和@JsonBackReference旨在处理领域之间的双向联动,一个家长的角色,另一个用于儿童分别作用:为避免此问题,应处理链接,以使对带@JsonManagedReference注释的属性进行正常处理(正常序列化,无需反序列化的特殊处理),并且对带@JsonBackReference注释的属性不进行序列化。在反序列化期间,其值设置为具有“托管”(转发)链接的实例。回顾一下,如果您在序列化或反序列化过程中不需要这些属性,可以使用@JsonIgnore。否则,使用@JsonManagedReference/ @JsonBackReference对是可行的方法。
16. @ColumnDefault 默认值
@Column(nullable = false)
@ColumnDefault("'John'")
private String name;
17. 自动填充创建时间和更新时间
@CreationTimestamp
@Column(columnDefinition = "timestamp")
@ColumnDefault("CURRENT_TIMESTAMP")
private Date createTime;
@UpdateTimestamp
@Column(columnDefinition = "timestamp")
@ColumnDefault("CURRENT_TIMESTAMP")
private Date updateTime;
pageable和specification
-
pageable是组装分页条件 -
specification是组装查询条件
/**
* 品牌前Top5
*
* @return
*/
@Override
public Wrapper<PageData<BrandReportDO>> getBrandTop5() {
Pageable pageable = PageRequest.of(0, 5, Sort.by("brandSaleAmount","brandSaleSum").descending());
Page<BrandReportDO> all = brandReportRepository.findAll(pageable);
return Wrapper.success(new PageData<>(all.getTotalElements(), all.getContent()));
}
/**
* 地市销售金额Top5
*
* @return
*/
@Override
public Wrapper<PageData<CitiesReportDO>> getCitiesSaleSumTop5() {
Pageable pageable = PageRequest.of(0, 5, Sort.by("citiesSaleSum").descending());
Page<CitiesReportDO> all = citiesReportRepository.findAll(pageable);
return Wrapper.success(new PageData<>(all.getTotalElements(), all.getContent()));
}
/**
* 地市销售量Top5
*
* @return
*/
@Override
public Wrapper<PageData<CitiesReportDO>> getCitiesSaleAmountTop5() {
Pageable pageable = PageRequest.of(0, 5, Sort.by("citiesSaleAmount").descending());
Page<CitiesReportDO> all = citiesReportRepository.findAll(pageable);
return Wrapper.success(new PageData<>(all.getTotalElements(), all.getContent()));
}
/**
* 区县销售量Top10
*
* @return
*/
@Override
public Wrapper<PageData<CountyReportDO>> getCountySaleAmountTop10() {
Pageable pageable = PageRequest.of(0, 10, Sort.by("countySaleAmount","countySaleSum").descending());
Page<CountyReportDO> all = countyReportRepository.findAll(pageable);
return Wrapper.success(new PageData<>(all.getTotalElements(), all.getContent()));
}
Jpa存入多张图片解决方案
方案一:
思路: 转换成json存入
JpaJsonToStringListConverter
/**
* 将List<String>与json进行转换
*/
@Converter(autoApply = true)
public class JpaJsonToStringListConverter implements AttributeConverter<List<String>, String> {
private final static ObjectMapper OBJECT_MAPPER = new ObjectMapper();
@Override
public String convertToDatabaseColumn(List<String> attribute) {
try {
attribute = Objects.isNull(attribute) ? Collections.emptyList() : attribute;
return OBJECT_MAPPER.writeValueAsString(attribute);
} catch (Exception e) {
e.printStackTrace();
throw new BusinessException(ResponseCode.BUSINESS_ERROR, "数据库Json字段写入错误");
}
}
@Override
public List<String> convertToEntityAttribute(String dbData) {
try {
if (dbData == null) {
return new ArrayList<>();
}
return OBJECT_MAPPER.readValue(dbData, new TypeReference<List<String>>() {
});
} catch (Exception e) {
e.printStackTrace();
throw new BusinessException(ResponseCode.BUSINESS_ERROR, "数据库Json字段写入错误");
}
}
}
实体类中
/**
* 评价图片
*/
@Convert(converter = JpaJsonToStringListConverter.class)//指定类,将List<String>与json进行转换
@Column(columnDefinition = "text")//使用text类型存储
private List<String> pics;
方案二:
直接用list类型存
/**
* 评价图片
*/
@Column(columnDefinition = "text")//使用text类型存储
private List<String> pics;
则数据库中的存储为
["url1","url2"]
查询时也会自动转换为List
问题
1. Field ‘id’ doesn’t have a default value
修改实体主键的设置方式为int自增模式,也就是
/**
* id
*/
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
报错
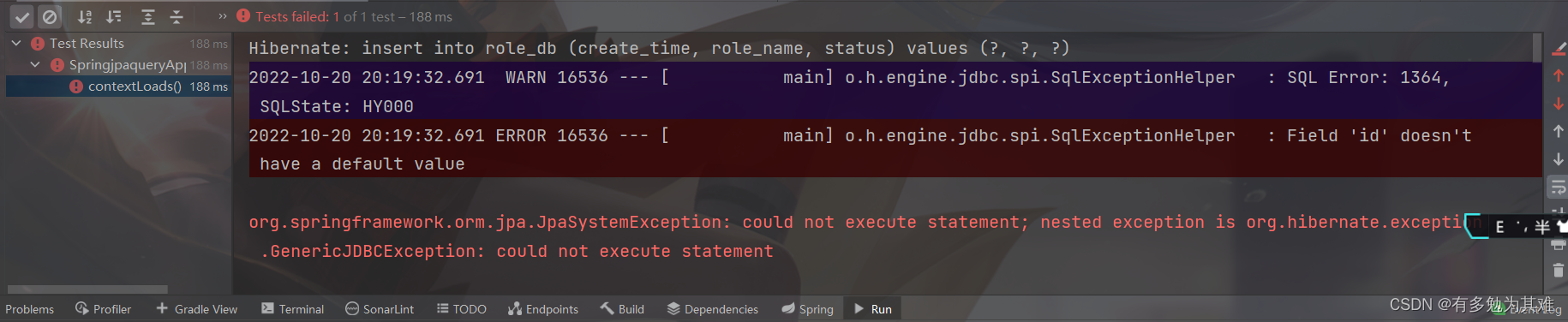
原因:
spring:
jpa:
open-in-view: false
hibernate:
# create ----每次运行该程序,没有表格会新建表格,表内有数据会清空;
# create-drop ----每次程序结束的时候会清空表
# update ---- 每次运行程序,没有表格会新建表格,表内有数据不会清空,只会更新
# validate ---- 运行程序会校验数据与数据库的字段类型是否相同,不同会报错。
# none —禁用 ddl 处理
ddl-auto: update
2. Unable to locate Attribute with the the given name [noticeId] on this ManageType [com.example.demo.entity.ContentNoticeAutoPublish]
原因:
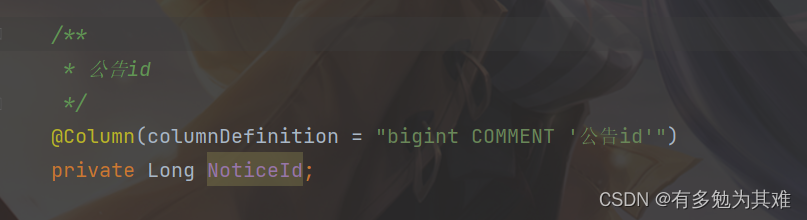
用了大写jpa找不到noticeId
解决方法:
字段命名应遵循驼峰命名法,改为noticeId即可
3. java.lang.IllegalArgumentException: org.hibernate.ObjectDeletedException: deleted instance passed to merge: [com.ssy.lingxi.product.entity.commodity.CommodityUnitPriceAndPic#]
今天处理了一个bug,是保存商品数据之前清理了中间表数据,想重新保存,但是保存报错了

原因:jpa在清除中间表数据之后,需要执行flush()操作使其实体状态在托管状态才能保存
解决方案:
xxxRepository.flush();















 4313
4313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









