







一、实验原理
MPEG-1 Audio LayerII编码器原理
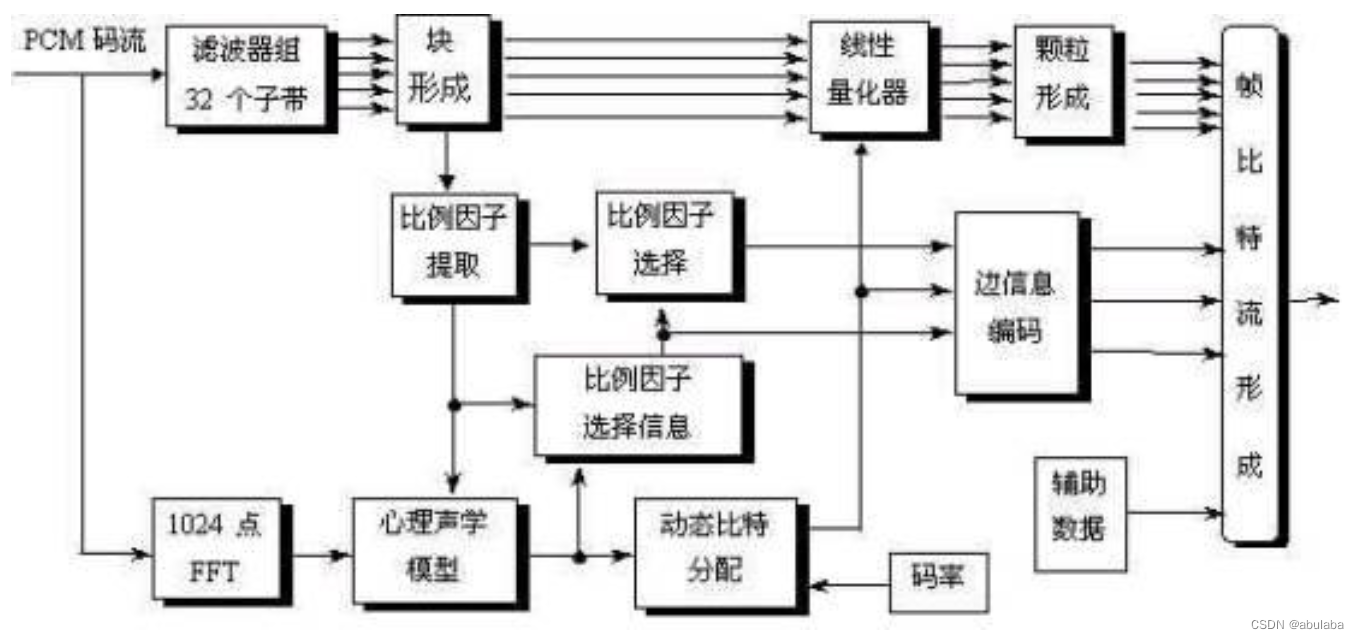
输入声音信号经过一个多相滤波器组,变换到多个子带。 同时经过“心理声学模型”计算以频率为自变量的噪声掩蔽 阈值。量化和编码部分用信掩比 SMR 决定分配给子带信号 的量化位数,使量化噪声<掩蔽域值。最后通过数据帧包装 将量化的子带样本和其它数据按照规定的帧格式组装成比特 数据流。
两条线
时间的瞬时特性
频域分析
时-频分析的矛盾
在低频部分,LayerI/II的带宽明显大于临界带宽
解决方法:提高频域分辨率(更多子带),同时保证向后兼容
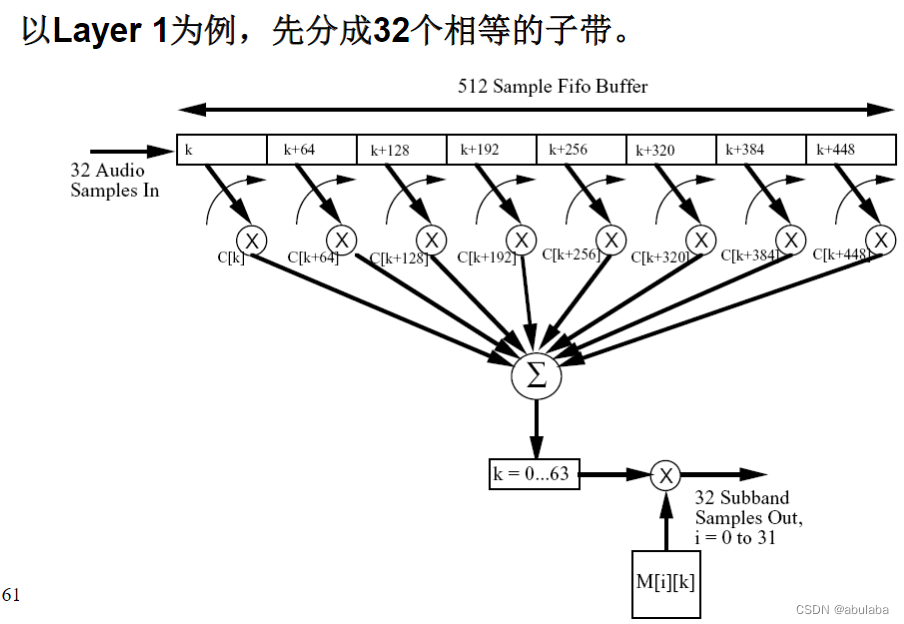
( 1 )多相滤波器组,用来分割子带
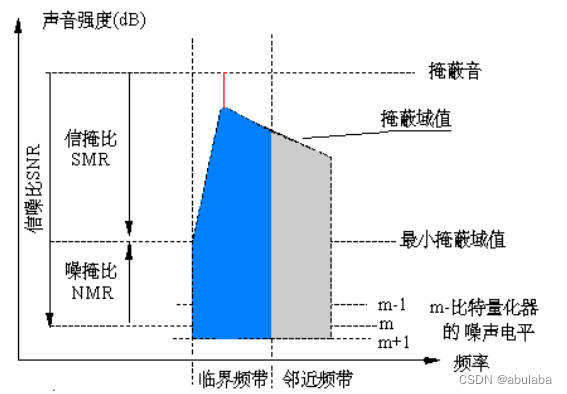
( 2 )量化和编码 – 比例因子的取值和编码
(3)数据帧包装


心理声学模型的实现过程
MPEG-I 标准定义了两个模型:
心理声学模型1: 计算复杂度低;但对假设用户听不到的部分压缩太严重
心理声学模型2 : 提供了适合Layer III编码的更多特征
实际实现的模型复杂度取决所需要的压缩因子。
心理声学模型I
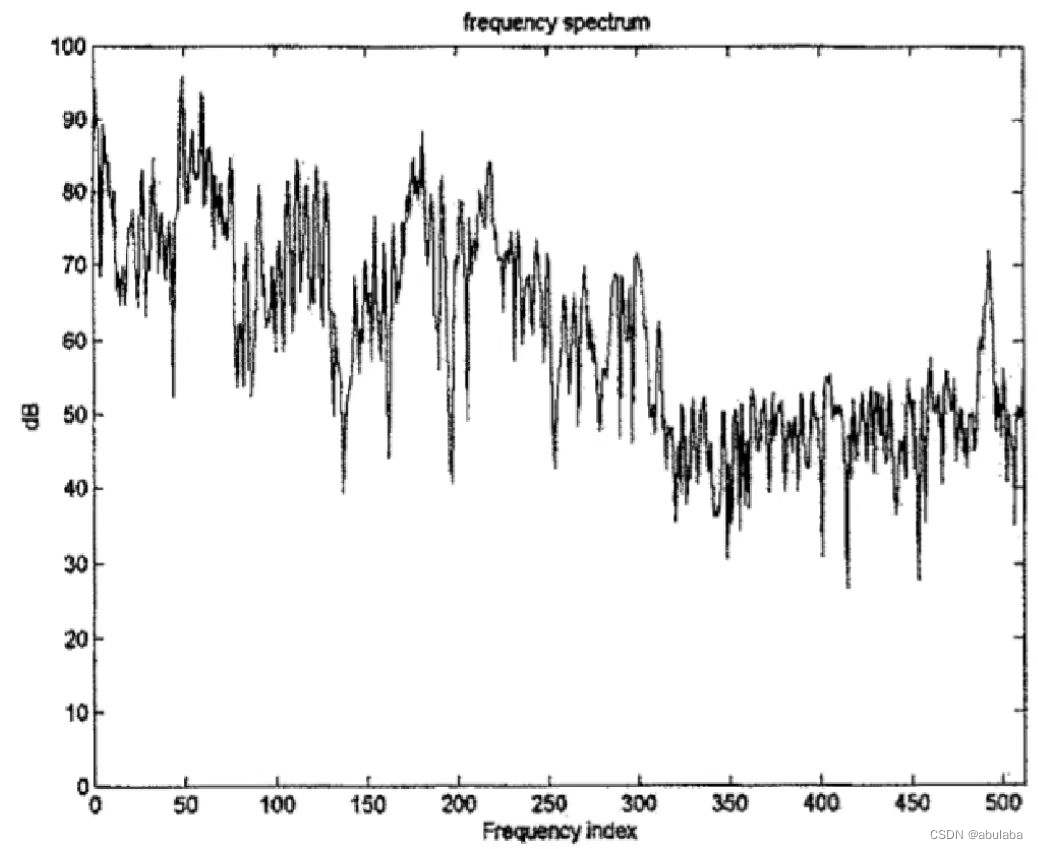
实现:
1、将样本变换到频域
32个等分的子带信号并不能精确地反映人耳的听觉特性。引入FFT补偿频率分辨率不足的问题。
2、确定子带声压级别
3、考虑安静时阈值,即绝对阈值
在标准中有根据输入PCM信号的采样率编制的“频率、临界频带率和绝对阈值”表。
4、将音频信号分解成“乐音(tones)” 和“非乐音/噪声”部分
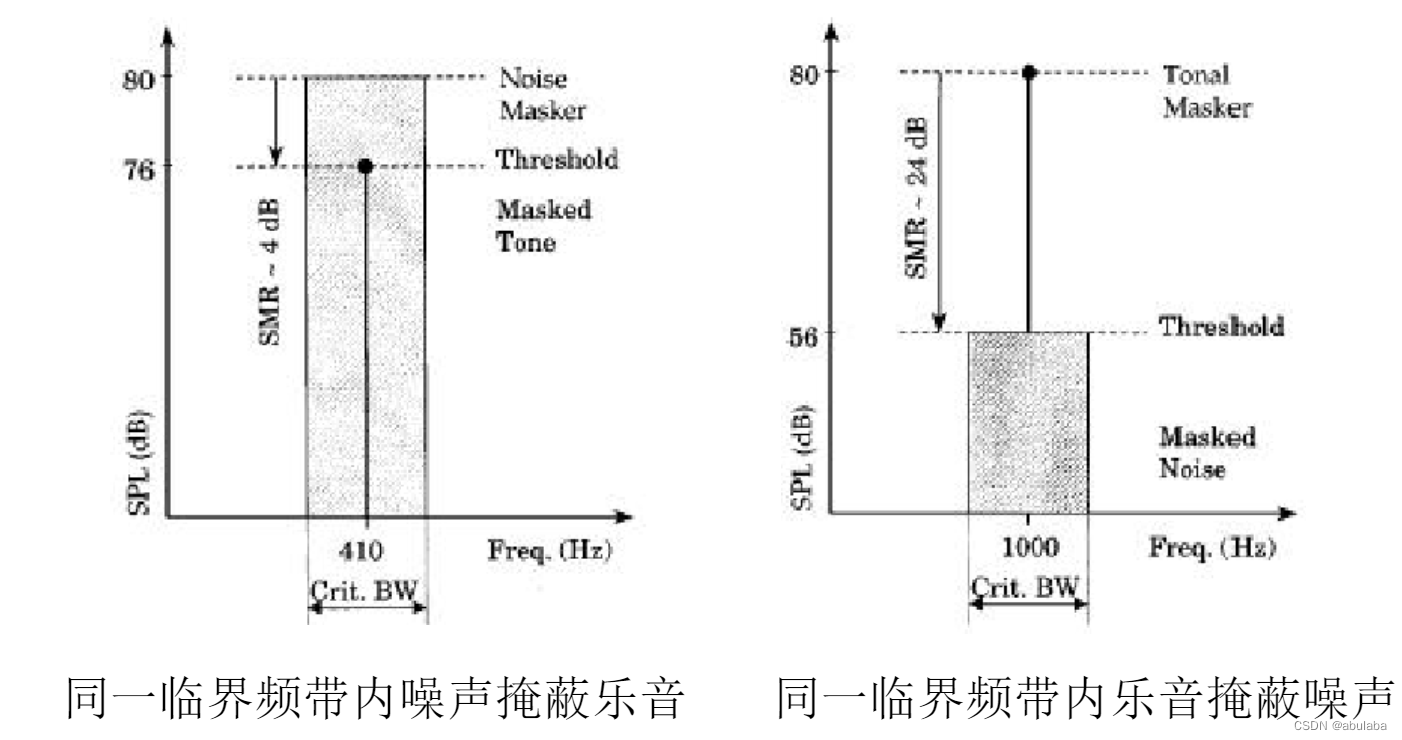
两种信号的掩蔽能力不同。根据音频频谱的局部功率最大值确定乐音成分局部峰值为乐音,然后将本临界频带内的剩余频谱合在一起,组成一个代表噪声频率(无调成份)
5、音调和非音调掩蔽成分的消除
利用标准中给出的绝对阈值消除被掩蔽成分;考虑在每个临界频带内,小于0.5Bark的距离中只保留最高功率的成分
6、单个掩蔽阈值的计算
音调成分和非音调成分单个掩蔽阈值根据标准中给出的算法求得。
7、全局掩蔽阈值的计算

还要考虑别的临界频带的影响。一个掩蔽信号会对其它频带上的信号产生掩蔽效应
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 423
423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









