







1.准备工作
1.1 新建hadoop用户,修改主机名
1.2 设置静态ip
1.3 设置su
1.4 修改hosts文件
1.5 安装ssh,生成key 无密码登陆
1.6 卸载原生jdk ,安装jdk 1.7
1.7 复制源文件:maven hadoop spark caffe caffeonspark cuda驱动 cudnn,并且修改文件所属用户,文件权限
2.install hadoop
2.1 修改各种配置文件
2.2 检验hadoop是否安装成功
3.install spark
3.1 修改配置文件
3.2 验证spark 是否安装成功
3.3 运行spark demo
4. 修改bashrc 完成所有环境变量设置
5.安装caffe
5.1 cuda驱动安装
5.2 安装caffe
6. 安装caffeonspark
7. 运行 caffeonspark mnist demo
8 参考资料
1.准备工作
1.1 新建hadoop用户,修改主机名
切换到root用户下:
创建hadoop用户组 sudo addgroup hadoop
创建hadoop用户 sudo adduser -ingroup hadoop hadoop
给hadoop用户添加权限,打开/etc/sudoers文件 sudo gedit /etc/sudoers
给hadoop用户赋予root用户同样的权限 在root ALL=(ALL:ALL) ALL下添加hadoop ALL=(ALL:ALL) ALL
脚本:
sudo addgroup hadoop
sudo adduser -ingroup hadoop hadoop
echo "hadoop ALL=(ALL:ALL) ALL" >> /etc/sudoers #最后最佳写入
修改主机名:
sudo gedit /etc/hosts :区分主机名和用户名区别,各个节点通过主机名通信
1.2 设置静态ip
在Ubuntu右上角,右键网络连接,点击Edit Connection (对应的wifi名),出现如图所示:
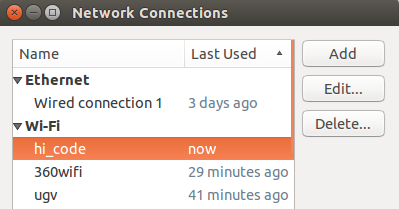
点击Edit,出现如下图:
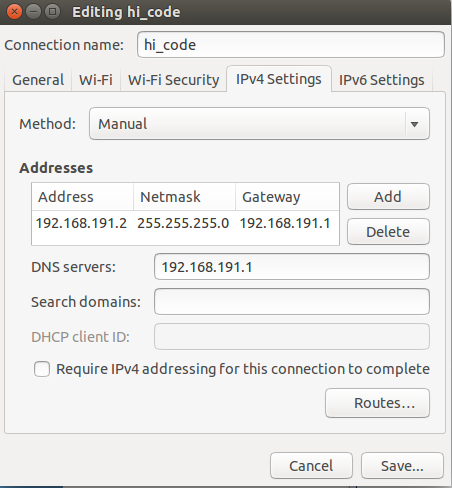
其中,选择ipv4,使用自定义即Manual设置,设置ip地址和网关等如图,点击save,然后重启网络连接即可。
注意:
1.修改ip地址需要重启电脑
2.关闭防火墙 ufw disable
3.用猎豹wifi,数据共享模式:nat。 不能用360wifi
1.3 设置su (需要手动设置)
登录su (如果没有设置root 密码,执行命令:sudo passwd root 然后输入密码)
sudo passwd <user> 即可输入简单密码
1.4 修改hosts文件,新添加节点时,修改hosts文件
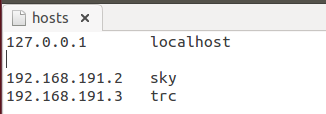
1.5 安装ssh,生成key 无密码登陆
1.5.1 sudo apt-get install openssh-server
1.5.2 产生密钥
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
1.5.3 需要让机器间都能相互访问,就把每个机子上的id_rsa.pub发给master节点,传输公钥可以用scp来传输
scp ~/.ssh/id_rsa.pub hadoop@sky:~/.ssh/id_rsa.pub.slave1
1.5.4 在master上,将所有公钥加到用于认证的公钥文件authorized_keys中
cat ~/.ssh/id_rsa.pub* >> ~/.ssh/authorized_keys
1.5.5 将公钥文件authorized_keys分发给每台slave
scp ~/.ssh/authorized_keys hadoop@slaves:~/.ssh/
1.5.6 在每台机子上验证SSH无密码登录
1.6 卸载原生jdk ,安装jdk 1.7
卸载原生jdk:apt-get purge openjdk*
安装jdk1.7
sudo apt-get-repository ppa:openjdk-r/ppa
sudo apt-get updata
sudo apt-get install openjdk-7-jre
sudo apt-get install openjdk-7-jdk
jdk:默认安装位置 /usr/lib/jvm/java-1.7.0-openjdk-amd64
1.7 复制源文件:maven hadoop spark caffe caffeonspark cuda驱动 cudnn,并且修改文件所属用户,文件权限
文件夹:deep_learning 文件夹复制到/home/hadoop/目录下 chmod -R 775 deep_learning/ chown -R hadoop:hadoop deep_learning/
文件夹:hadoop解压后 复制到 /usr/目录下 chmod -R 775 hadoop/ chown -R hadoop:hadoop hadoop
2.install hadoop
修改各种配置文件
hadoop/etc/hadoop进入hadoop配置目录,需要配置有以下7个文件:hadoop-env.sh,yarn-env.sh,slaves,core-site.xml,hdfs-site.xml,maprd-site.xml,yarn-site.xml。
hadoop-env.sh中配置JAVA_HOME
yarn-env.sh中配置JAVA_HOME
slaves中配置slave节点的ip或者host
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://sky:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/tmp</value>
</property>
hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>sky:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>sky:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>sky:19888</value>
</property>
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>sky:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>sky:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>sky:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>sky:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>sky:8088</value>
</property>
<property>
<name>yarn.nodemanager.disk-health-checker.enable</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>98</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
2.2 检验hadoop是否安装成功 ref :http://blog.csdn.net/xiaoxiangzi222/article/details/52757168 hadoop 提交mapreduce任务demo
启动hadoop,进入hadoop安装目录
bin/hdfs namenode -format
sbin/start-all.sh
3)启动后分别在master, node下输入jps查看进程
看到下面的结果,则表示成功。
Master(必须有四个):

node(必须有三个):

3.install spark
![]()
3.1 修改配置文件
spark-1.6.1-bin-hadoop2.6/conf 修改两个文件: spark-env.sh slaves
spark-env.sh修改:
export SPARK_HOME=/home/hadoop/deep_learning/spark-1.6.0-bin-hadoop2.6
export SCALA_HOME=/home/hadoop/deep_learning/scala-2.10.4
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-amd64
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_IP=192.168.191.2
SPARK_LOCAL_DIRS=/home/hadoop/deep_learning/spark-1.6.0-bin-hadoop2.6
SPARK_DRIVER_MEMORY=4G
export SPARK_LIBARY_PATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$HADOOP_HOME/lib/native
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native"
slaves :添加新节点时,所有都需要修改slave
3.3 运行spark demo
本例以集群模式运行SparkPi实例程序(deploy-mode 设置为cluster)
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 1G --executor-memory 1G --executor-cores 1 lib/spark-examples-1.6.1-hadoop2.6.0.jar 40
注意 Spark on YARN 支持两种运行模式,分别为yarn-cluster和yarn-client,yarn-cluster适用于生产环境;而yarn-client适用于交互和调试,因为能在客户端终端看到程序输出.
4. 修改bashrc 完成所有环境变量设置
export M2_HOME=/home/hadoop/deep_learning/apache-maven-3.5.0
export PATH=$M2_HOME/bin:$PATH
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-amd64
export JRE_HOME=/usr/lib/jvm/java-1.7.0-openjdk-amd64/jre
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export HADOOP_HOME=/usr/hadoop
export YARN_HOME=/usr/hadoop
export YARN_CONF_DIR=${YARN_HOME}/etc/hadoop
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native"
export CAFFE_ON_SPARK=/home/hadoop/deep_learning/CaffeOnSpark
export SPARK_HOME=/home/hadoop/deep_learning/spark-1.6.0-bin-hadoop2.6
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export PATH=${HADOOP_HOME}/bin:${SPARK_HOME}/bin:${PATH}
export LD_LIBRARY_PATH=${CAFFE_ON_SPARK}/caffe-public/distribute/lib:${CAFFE_ON_SPARK}/caffe-distri/distribute/lib
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/cuda-7.5/lib64
source ~/.bashrc
5.安装caffe
5.1 cuda驱动安装
5.2 安装caffe
6. 安装caffeonspark ref: https://github.com/yahoo/CaffeOnSpark/wiki/GetStarted_yarn
pushd ${CAFFE_ON_SPARK}/caffe-public/
cp Makefile.config.example Makefile.config
echo "INCLUDE_DIRS += ${JAVA_HOME}/include" >> Makefile.config
修改config文件
USE_CUDNN := 1 #if you want to use CUDNN
make build
${HADOOP_HOME}/bin/hdfs namenode -format
${HADOOP_HOME}/sbin/start-dfs.sh
${HADOOP_HOME}/sbin/start-yarn.sh
hadoop fs -mkdir -p /projects/machine_learning/image_dataset
${CAFFE_ON_SPARK}/scripts/setup-mnist.sh
hadoop fs -put -f ${CAFFE_ON_SPARK}/data/mnist_*_lmdb hdfs:/projects/machine_learning/image_dataset/
export SPARK_WORKER_INSTANCES=1
export DEVICES=1
hadoop fs -rm -f hdfs:///mnist.model
hadoop fs -rm -r -f hdfs:///mnist_features_result
spark-submit --master yarn --deploy-mode cluster \
--num-executors ${SPARK_WORKER_INSTANCES} \
--files ${CAFFE_ON_SPARK}/data/lenet_memory_solver.prototxt,${CAFFE_ON_SPARK}/data/lenet_memory_train_test.prototxt \
--conf spark.driver.extraLibraryPath="${LD_LIBRARY_PATH}" \
--conf spark.executorEnv.LD_LIBRARY_PATH="${LD_LIBRARY_PATH}" \
--class com.yahoo.ml.caffe.CaffeOnSpark \
${CAFFE_ON_SPARK}/caffe-grid/target/caffe-grid-0.1-SNAPSHOT-jar-with-dependencies.jar \
-train \
-features accuracy,loss -label label \
-conf lenet_memory_solver.prototxt \
-devices ${DEVICES} \
-connection ethernet \
-model hdfs:///mnist.model \
-output hdfs:///mnist_features_result
hadoop fs -ls hdfs:///mnist.model
hadoop fs -cat hdfs:///mnist_features_result/*
${HADOOP_HOME}/sbin/stop-yarn.sh
${HADOOP_HOME}/sbin/stop-dfs.sh
rm -rf ${HADOOP_HOME}/tmp/hadoop-${USER}
rm -rf ${HADOOP_HOME}/logs
8.参考资料















 6144
6144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









