







 本文介绍如何利用TensorFlow实现AlexNet,AlexNet是2012年ImageNet竞赛的胜出模型,适合初学者加深对深度学习及TensorFlow的理解。作者提供了GitHub代码链接,用于复现AlexNet的原始网络结构,并分享了模型测试过程。
本文介绍如何利用TensorFlow实现AlexNet,AlexNet是2012年ImageNet竞赛的胜出模型,适合初学者加深对深度学习及TensorFlow的理解。作者提供了GitHub代码链接,用于复现AlexNet的原始网络结构,并分享了模型测试过程。
转载注明出处:http://blog.csdn.net/accepthjp/article/details/69999309
AlexNet是2012年ImageNet比赛的冠军,虽然过去了很长时间,但是作为深度学习中的经典模型,AlexNet不但有助于我们理解其中所使用的很多技巧,而且非常有助于提升我们使用深度学习工具箱的熟练度。尤其是我刚入门深度学习,迫切需要一个能让自己熟悉tensorflow的小练习,于是就有了这个小玩意儿......
先放上我的代码:https://github.com/hjptriplebee/AlexNet_with_tensorflow
如果想运行代码,详细的配置要求都在上面链接的readme文件中了。本文建立在一定的tensorflow基础上,不会对太细的点进行说明。
模型结构
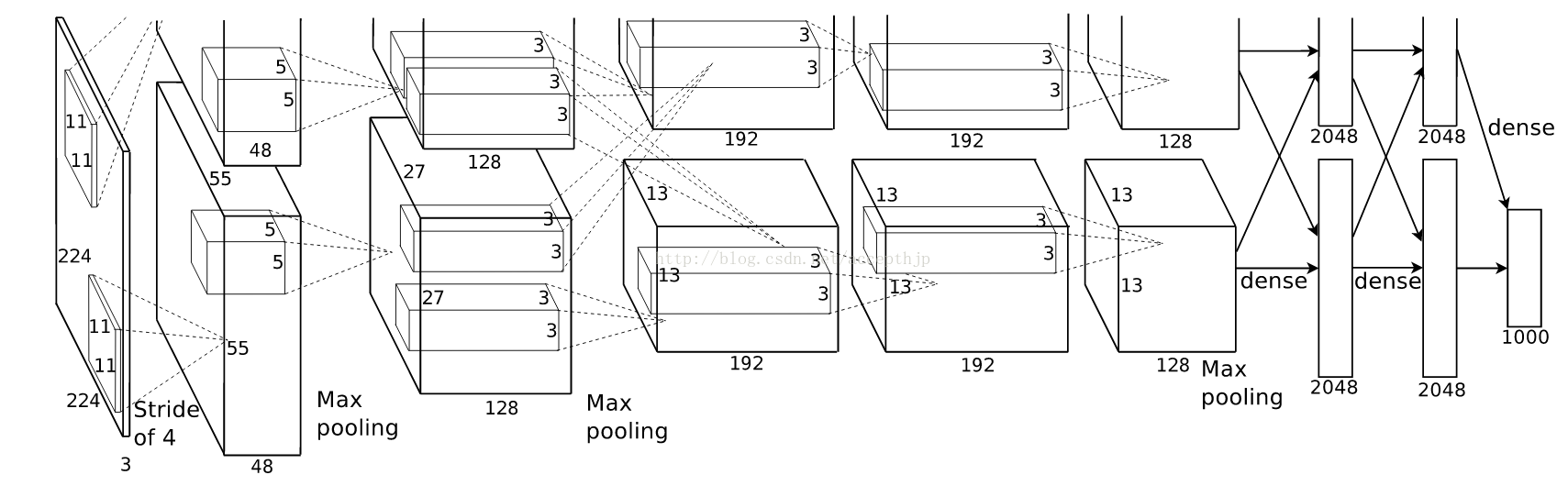
关于模型结构网上的文献很多,我这里不赘述,一会儿都在代码里解释。
有一点需要注意,AlexNet将网络分成了上下两个部分,在论文中两部分结构完全相同,唯一不同的是他们放在不同GPU上训练,因为每一层的feature map之间都是独立的(除了全连接层),所以这相当于是提升训练速度的一种方法。很多AlexNet的复现都将上下两部分合并了,因为他们都是在单个GPU上运行的。虽然我也是在单个GPU上运行,但是我还是很想将最原始的网络结构还原出来,所以我的代码里也是分开的。
模型定义
def maxPoolLayer(x, kHeight, kWidth, strideX, strideY, name, padding = "SAME"):
"""max-pooling" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3802
3802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









