






AlexNet相关理论(参考链接)
AlexNet的结构如图所示:
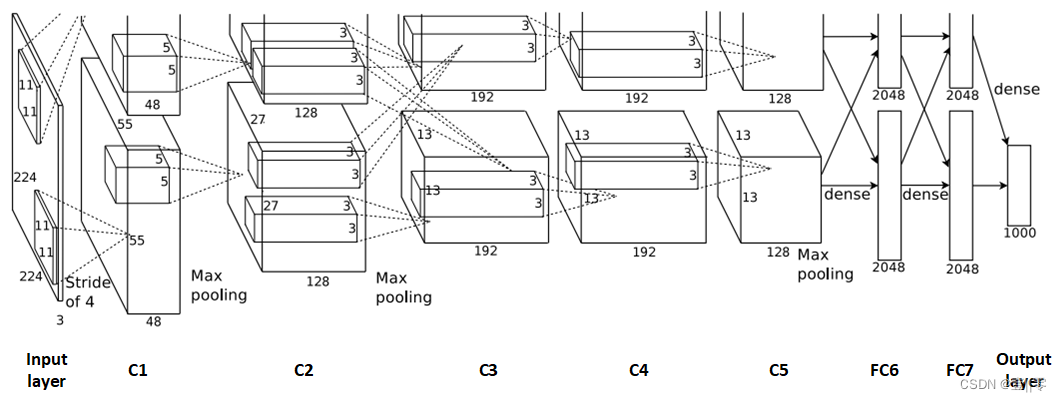
结构图进一步理解:
在整个图中,我是这样理解的:input layer是输入的图像,C1是第一个卷积层,第一个卷积层的卷积核作者画在了输入的图像上,卷积核的大小为11×11×3;以此理解,C2卷积层的卷积核画在了C1的特征图上,卷积核大小为5×5×96(两个GPU,每一个都是48,故为2×48=96)。
为什么图分为上下两层呢?这是因为作者在训练网络时用了两块GPU,两块做的操作是一样的,所以图看起来是上下对称的。
图中的虚线是什么?因为是两块GPU,虚线可以看作是在描述两层之间的对应联系,即,卷积层 C2、C4、C5中的卷积核只和位于同一GPU的上一层的特征图相连,C3的卷积核与两个GPU的上一层的特征图都连接。
图整体结构讲解:
如图所示,该网络包含八个带有权重的层;前五个是卷积的,其余三个是全连接的。最后一个全连接层的输出被馈送到 1000 路 softmax,生成 1000 个类标签的分布。第二、第四和第五卷积层的内核仅连接到驻留在同一 GPU 上的前一层中的内核映射。第三卷积层的内核连接到第二层中的所有内核映射。全连接层中的神经元与前一层中的所有神经元连接。响应归一化层位于第一和第二卷积层之后。最大池化层位于响应归一化层和第五个卷积层之后。 ReLU 非线性应用于每个卷积层和全连接层的输出。(处理流程为:卷积–>ReLU–>局部响应归一化(LRN)–>池化)
第一个卷积层使用 96 个大小为 11×11×3 的核,步长为 4 个像素,对 224×224×3 输入图像进行过滤。第二个卷积层将第一个卷积层的(响应归一化和池化)输出作为输入,并使用 256 个大小为 5 × 5 × 48 的内核对其进行过滤。第三、第四和第五卷积层相互连接,无需任何中间的池化或标准化层。第三个卷积层有 384 个大小为 3 × 3 ×256 的内核,连接到第二个卷积层的(归一化、池化)输出。第四个卷积层有 384 个大小为 3 × 3 × 192 的内核,第五个卷积层有 256 个大小为 3 × 3 × 192 的内核。每个全连接层有 4096 个神经元。
网络参数
AlexNet神经元数量
| 层数 | 说明 | 神经元数量 |
|---|---|---|
| C1 | C1层的FeatureMap的神经元个数 | 55x55x48x2=290400 |
| C2 | C2层的FeatureMap的神经元个数 | 27x27x128x2=186624 |
| C3 | C3层的FeatureMap的神经元个数 | 13x13x192x2=64896 |
| C4 | C4层的FeatureMap的神经元个数 | 13x13x192x2=64896 |
| C5 | C5层的FeatureMap的神经元个数 | 13x13x128x2=43264 |
| FC6 | FC6层的FeatureMap的神经元个数 | 4096 |
| FC7 | FC7层的FeatureMap的神经元个数 | 4096 |
| Output layer | Output layer层的FeatureMap的神经元个数 | 1000 |
整个AlexNet网络包含的神经元个数为:
290400 + 186624 + 64896 + 64896 + 43264 + 4096 + 4096 + 1000 = 659272。大约65万个神经元。
AlexNet参数数量
| 层数 | 说明 | 参数数量 |
|---|---|---|
| C1 | 卷积核11x11x3,96个卷积核,偏置参数 | (11x11x3+1)x96=34944 |
| C2 | 卷积核5x5x48,128个卷积核,2组,偏置参数 | (5x5x48+1)x128x2=307456 |
| C3 | 卷积核3x3x256,192个卷积核,2组,偏置参数 | (3x3x256+1)x192×2=885120 |
| C4 | 卷积核3x3x192,192个卷积核,2组,偏置参数 | (3x3x192+1)x192x2=663936 |
| C5 | 卷积核3x3x192,128个卷积核,2组,偏置参数 | (3x3x192+1)x128x2=442624 |
| FC6 | 卷积核6x6x256,4096个神经元,偏置参数 | (6x6x256+1)x4096=37752832 |
| FC7 | 全连接层,4096个神经元,偏置参数 | (4096+1)x4096=16781312 |
| Output layer | 全连接层,1000个神经元 | 4096×1000=4096000 |
整个AlexNet网络包含的参数数量为:
34944 + 307456 + 885120 + 663936 + 442624 + 37752832 + 16781312 + 4096000 = 60964224。大约6千万个参数。
AlexNet相关代码复现:
说明:
- 采用PyTorch框架;
- 数据集用的是“猫狗大战”数据集,数据集链接:https://pan.baidu.com/s/197tr1RxDK3p4xzhIn9F3Jg?pwd=0xrl
提取码:0xrl
代码复现过程:
1.项目文件结构:
2.制作数据集标签文件:
import os #导入 os 模块,用于操作文件和目录。
train_txt_path=os.path.join("data","catVSdog","train.txt") #定义训练集文本文件的路径。
train_dir=os.path.join("data","catVSdog","train_data") #定义训练集图像数据的路径。
valid_tat_path=os.path.join("data","catVSdog","test.txt")
valid_dir=os.path.join("data","catVSdog","test_data")
def gen_txt(txt_path,img_dir): #定义一个函数,用于生成文本文件。
f=open(txt_path,'w') #以写入模式打开文本文件
for root,s_dirs,_ in os.walk(img_dir,topdown=True):#遍历img_dir目录及其子目录
for sub_dir in s_dirs: #遍历子目录
i_dir=os.path.join(root,sub_dir) #获取子目录的绝对路径
img_list=os.listdir(i_dir) #获取子目录下所有文件的列表
for i in range(len(img_list)): #遍历文件列表
if not img_list[i].endswith('jpg'): #判断文件是否以jpg结尾
continue
label=img_list[i].split('.')[0] #将文件名分割,获取第0个位置的文件名中的标签(‘cat’ 或 ‘dog’)
if label=='cat':
label='0' #注意要使用'0'而不是0,即要使用str类型而非int类型
else:
label='1'
img_path=os.path.join(i_dir,img_list[i])#获取图像文件的绝对路径
line=img_path+' '+label+'\n' #生成一行文本,包含图像路径和标签,以空格分隔。每生成一行,换行
f.write(line) #将文本写入文件中
f.close() #关闭文件
if __name__=='__main__':
gen_txt(train_txt_path,train_dir)
gen_txt(valid_tat_path,valid_dir)
运行代码之后会在./data/catVSdog/目录下生成train.txt和test.txt两个数据集标签文件。
3.dataset数据预处理dataset.py
import matplotlib.pyplot as plt
import numpy as np
import torch.utils.data
from PIL import Image #导入了 PIL 库中的 Image 模块,用于处理图像。
from torch.utils.data import Dataset #导入了 torch.utils.data 库中的 Dataset 类,用于定义数据集。
from torchvision import transforms
#因为使用的是自己的数据集,所以要写一个Dataset类
class MyDataset(Dataset):
def __init__(self,txt_path,transform=None,target_transform=None):
"""txt_path 是一个文本文件的路径,该文件包含图像文件名和对应的标签。
transform 和 target_transform 是可选参数,分别表示对输入图像和标签进行预处理的函数。"""
fh=open(txt_path,'r')
imgs=[]
for line in fh:
line=line.rstrip() #rstrip()用于去除结尾的空格、换行符等
words=line.split() #分割
imgs.append((words[0],int(words[1]))) #添加到列表中
self.imgs=imgs
self.transform=transform
self.target_transform=target_transform
def __getitem__(self,index):
fn,label=self.imgs[index] #self.imgs是一个list,self.imgs[index]是一个str,包含图片路径,图片标签
img=Image.open(fn).convert('RGB') #打开图像文件并转换为RGB格式
if self.transform is not None:
img=self.transform(img) #self.transform(img)对图片进行处理
return img,label
def __len__(self):
return len(self.imgs) #返回数据集中图像的数量
"""对数据进行预处理操作,这部分和LeNet-5中的预处理操作一样"""
pipline_train=transforms.Compose([
#随机旋转图片
transforms.RandomHorizontalFlip(),
#将图片尺寸resize到227*227
transforms.Resize((227,227)),
#将图片转为tensor格式
transforms.ToTensor(),
#正则化
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))#均值,方差
])
pipline_test=transforms.Compose([
transforms.Resize((227,227)),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])
train_data=MyDataset('./data/catVSdog/train.txt',transform=pipline_train)
test_data=MyDataset('./data/catVSdog/test.txt',transform=pipline_test)
#train_data和test_data有很多的训练数据与测试数据,调用DataLoader批量加载
trainloader=torch.utils.data.DataLoader(dataset=train_data,batch_size=64,shuffle=True)
testloader=torch.utils.data.DataLoader(dataset=test_data,batch_size=32,shuffle=False)
#类别信息也是我们给定的
classes=('cat','dog')
# #下面只是对上面操作的可视化效果的展示,可以不要
# examples=enumerate(trainloader)
# batch_idx,(example_data,example_label)=next(examples)
# #批量展示图片
# for i in range(4):
# plt.subplot(1,4,i+1)
# plt.tight_layout() #自动调整子图参数,使之填充整个图像区域
# img=example_data[i]
# img=img.numpy() # FloatTensor转为ndarray
# img=np.transpose(img,(1,2,0)) # 把channel那一维放到最后
# img=img*[0.5,0.5,0.5]+[0.5,0.5,0.5]
# plt.imshow(img)
# plt.title("label:{}".format(example_label[i]))
# plt.xticks([])
# plt.ylabel([])
# plt.show()
4.AlexNet网络结构AlexNet.py
import torch
import torch.nn as nn
import torch.optim as optim
import time
import torch.nn.functional as F
import dataset
from matplotlib import pyplot as plt
from dataset import MyDataset
class AlexNet(nn.Module):
def __init__(self,num_classes=2):
super().__init__()
self.net=nn.Sequential(
#第一层
nn.Conv2d(in_channels=3,out_channels=96,kernel_size=11,stride=4),
nn.ReLU(),
nn.LocalResponseNorm(size=5,alpha=0.0001,beta=0.75,k=2), #全部按照论文中的来的。局部相应归一化(LRN)
nn.MaxPool2d(kernel_size=3,stride=2),
#第二层
nn.Conv2d(in_channels=96,out_channels=256,kernel_size=5,padding=2),
nn.ReLU(),
nn.LocalResponseNorm(size=5,alpha=0.0001,beta=0.75,k=2),
nn.MaxPool2d(kernel_size=3,stride=2),
#第三层
nn.Conv2d(in_channels=256,out_channels=384,kernel_size=3,padding=1),
nn.ReLU(),
#第四层
nn.Conv2d(in_channels=384,out_channels=384,kernel_size=3,padding=1),
nn.ReLU(),
#第五层
nn.Conv2d(in_channels=384,out_channels=256,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2)
)
#分类,也是后三个全连接层
self.classifier=nn.Sequential(
#第一个全连接层
nn.Dropout(p=0.5,inplace=True),
nn.Linear(in_features=(256*6*6),out_features=500),
nn.ReLU(),
#第二个全连接层
nn.Dropout(p=0.5,inplace=True),
nn.Linear(in_features=500,out_features=20), #注意:这儿的20以及num_classes是根据这个数据集所设置的,若用论文中的数据集应该分别为XXX,1000
nn.ReLU(),
#第三个全连接层
nn.Linear(in_features=20,out_features=num_classes)
)
#前向传播
def forward(self, x):
x=self.net(x)
x=x.view(-1,256*6*6)
return self.classifier(x)
#创建模型,部署到GPU上
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
model=AlexNet().to(device)
#定义优化器
optimizer=optim.Adam(model.parameters(),lr=0.001)
#定义训练过程(和LeNet-5的一样,具体的代码讲解去看LeNet-5的)
def train_runner(model,device,trainloader,optimizer,epoch):
# 训练模型, 启用 BatchNormalization 和 Dropout, 将BatchNormalization和Dropout置为True
model.train()
total=0
correct=0.0
# enumerate迭代已加载的数据集,同时获取数据和数据下标
for i,data in enumerate(trainloader,0):
inputs,labels=data
#把模型部署到device上
inputs,labels=inputs.to(device),labels.to(device)
#初始化梯度
optimizer.zero_grad()
#保存训练结果
outputs=model(inputs)
# 计算损失和
# 多分类情况通常使用cross_entropy(交叉熵损失函数), 而对于二分类问题, 通常使用sigmod
loss=F.cross_entropy(outputs,labels)
# 获取最大概率的预测结果
#dim=1返回每一行的最大值对应的下标
predict=outputs.argmax(dim=1)
total+=labels.size(0)
correct+=(predict==labels).sum().item()
#反向传播
loss.backward()
#更新参数
optimizer.step()
if i % 100==0:
#loss.item()表示当前loss的数值
print("Train Epoch{} \t Loss: {:.6f}, accuracy: {:.6f}%".format(epoch, loss.item(), 100 * (correct / total)))
Loss.append(loss.item())
Accuracy.append(correct/total)
return loss.item(),correct/total
#定义测试过程(和LeNet-5的一样,具体的代码讲解去看LeNet-5的)
def test_runner(model,device,testloader):
# 模型验证, 必须要写, 否则只要有输入数据, 即使不训练, 它也会改变权值
# 因为调用eval()将不启用 BatchNormalization 和 Dropout, BatchNormalization和Dropout置为False
model.eval()
# 统计模型正确率, 设置初始值
correct = 0.0
test_loss = 0.0
total = 0
# torch.no_grad将不会计算梯度, 也不会进行反向传播
with torch.no_grad():
for data,label in testloader:
data, label = data.to(device), label.to(device)
output = model(data)
test_loss+=F.cross_entropy(output,label).item()
predict=output.argmax(dim=1)
#计算正确数量
total+=label.size(0)
correct+=(predict==label).sum().item()
# 计算损失值
print("test_avarage_loss: {:.6f}, accuracy: {:.6f}%".format(test_loss / total, 100 * (correct / total)))
#开始运行
epoch=20
Loss=[]
Accuracy=[]
for epoch in range(1,epoch+1):
print("start_time",time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
loss,acc=train_runner(model,device,dataset.trainloader,optimizer,epoch)
Loss.append(loss)
Accuracy.append(acc)
test_runner(model,device,dataset.testloader)
print("end_time: ",time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())),'\n')
print('Finished Training')
plt.subplot(2,1,1)
"""plt.subplot(2, 1, 1)是matplotlib.pyplot库中的一个函数,用于在一张图中创建多个子图。这个函数的参数表示子图的布局和当前激活的子图。
在这个例子中,`2` 表示子图的行数,`1` 表示子图的列数,`1` 表示当前激活的子图索引。因此,这行代码将创建一个包含两行一列子图的图,并激活第一个子图"""
plt.plot(Loss)
plt.title('Loss')
plt.show()
plt.subplot(2,1,2)
plt.plot(Accuracy)
plt.title('Accuracy')
plt.show()
#保存模型
print(model)
torch.save(model,'./models/AlexNet-catVSdog.pth') #保存模型结构和参数
5.测试test.py
import matplotlib.pyplot as plt
from PIL import Image
import torch
import numpy as np
from torchvision.transforms import transforms
import torch.nn.functional as F
import torch.nn as nn
import dataset
class AlexNet(nn.Module):
def __init__(self,num_classes=2):
super().__init__()
self.net=nn.Sequential(
#第一层
nn.Conv2d(in_channels=3,out_channels=96,kernel_size=11,stride=4),
nn.ReLU(),
nn.LocalResponseNorm(size=5,alpha=0.0001,beta=0.75,k=2), #全部按照论文中的来的。局部相应归一化(LRN)
nn.MaxPool2d(kernel_size=3,stride=2),
#第二层
nn.Conv2d(in_channels=96,out_channels=256,kernel_size=5,padding=2),
nn.ReLU(),
nn.LocalResponseNorm(size=5,alpha=0.0001,beta=0.75,k=2),
nn.MaxPool2d(kernel_size=3,stride=2),
#第三层
nn.Conv2d(in_channels=256,out_channels=384,kernel_size=3,padding=1),
nn.ReLU(),
#第四层
nn.Conv2d(in_channels=384,out_channels=384,kernel_size=3,padding=1),
nn.ReLU(),
#第五层
nn.Conv2d(in_channels=384,out_channels=256,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2)
)
#分类,也是后三个全连接层
self.classifier=nn.Sequential(
#第一个全连接层
nn.Dropout(p=0.5,inplace=True),
nn.Linear(in_features=(256*6*6),out_features=500),
nn.ReLU(),
#第二个全连接层
nn.Dropout(p=0.5,inplace=True),
nn.Linear(in_features=500,out_features=20), #注意:这儿的20以及num_classes是根据这个数据集所设置的,若用论文中的数据集应该分别为XXX,1000
nn.ReLU(),
#第三个全连接层
nn.Linear(in_features=20,out_features=num_classes)
)
#前向传播
def forward(self, x):
x=self.net(x)
x=x.view(-1,256*6*6)
return self.classifier(x)
if __name__=='__main__':
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model=AlexNet()#先加载自己的模型(先实例化),要不然在下面加载模型时会重新训练一遍
print("加载模型")
model=torch.load('./models/AlexNet-catVSdog.pth')
print("模型加载成功")
model=model.to(device)
model.eval() #把模型转为test模式
#读取要预测的图片
img=Image.open("./images/dog.10010.jpg")
#导入图片,图片扩展后为[1,1,32,32]
trans=transforms.Compose([
transforms.Resize((227,227)),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))
])
img=trans(img)
img=img.to(device)
img=img.unsqueeze(0) #图片扩展多一维,因为输入到保存的模型中是4维的[batch_size,通道,长,宽],而普通图片只有三维,[通道,长,宽]
#预测
classes=('cat','dog')
output=model(img)
prob=F.softmax(output,dim=1)
print("概率:",prob)
value,predicted=torch.max(output.data,1)
predict=output.argmax(dim=1)
pred_class=classes[predicted.item()]
print("预测类别:",pred_class)
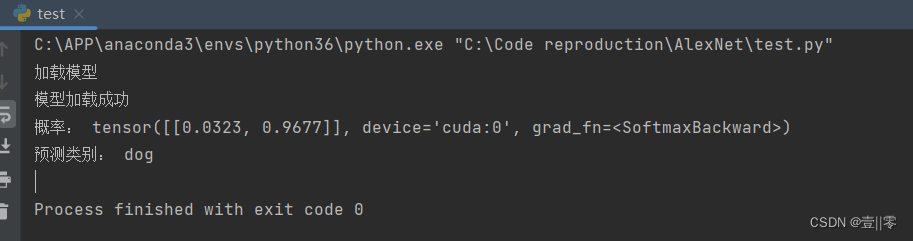
6.测试结果
识别图片:

结果:
7.总结
- 在test.py中一定要有类class AlexNet(nn.Module): ,并且要和AlexNet.py中的类class AlexNet(nn.Module):保持一模一样(就算注释及其位置也要一样),要不然会报错。
- 一定要记得在后面实例化类(test.py中),即 model=AlexNet(),要不然和在test.py中没加类class AlexNet(nn.Module): 一样,在后面加载模型时,会重新再执行一遍AlexNet.py。
- 教训:以后一定先设置epoch=1试一遍能不能正常运行。















 797
797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









