







本課課程:
- Spark源码中的Scala的 implicit 的使用
- Scala的 implicit 编程操作实战
- Scala的 implicit 企业级最佳实践
Spark源码中的Scala的 implicit 的使用
這個東西意義非常重大,RDD 本身沒有所謂的 Key, Value,只不過是自己本身解讀的時候把它變成 Key Value 的方法去解讀,RDD 本身就是一個 Record。
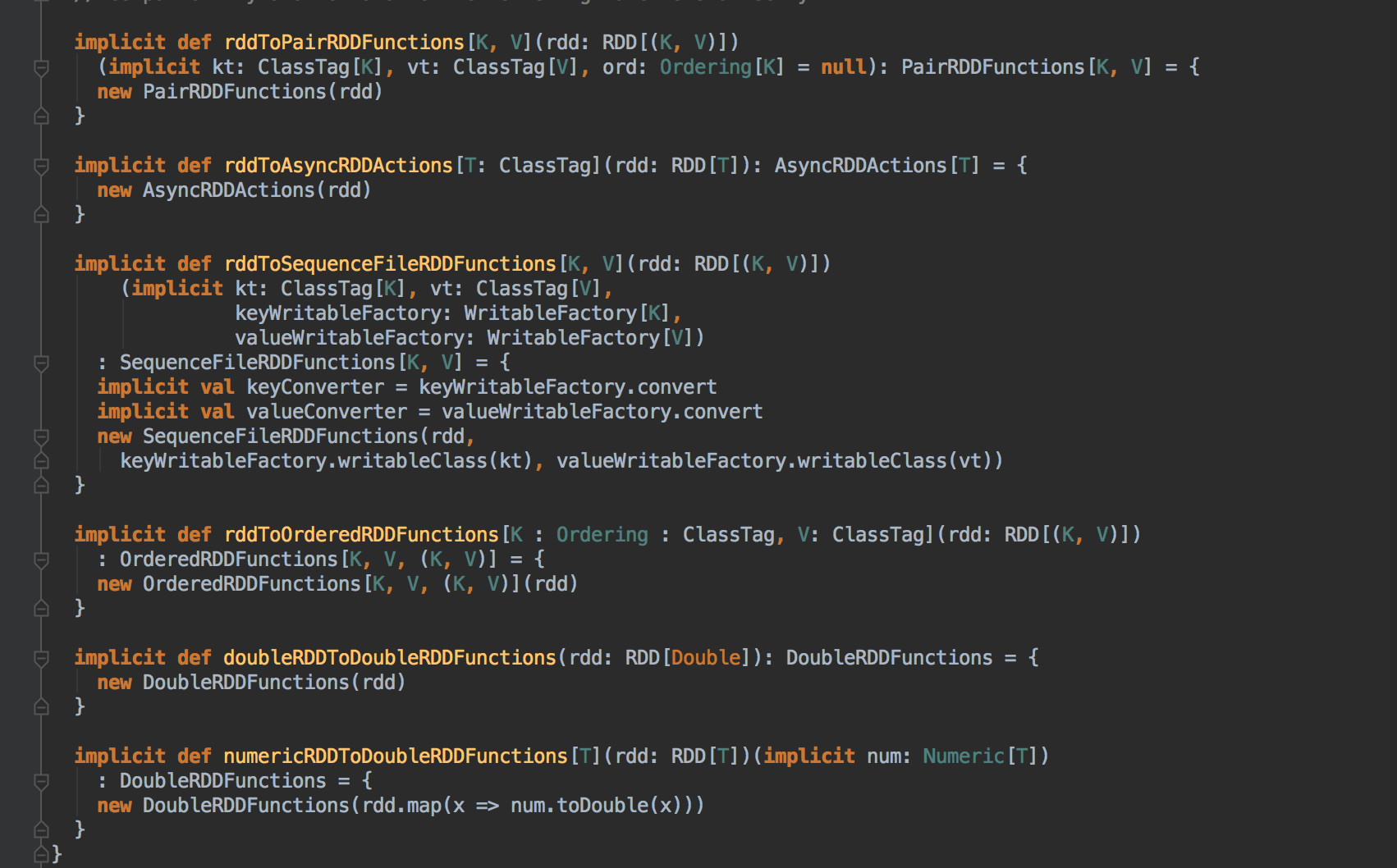
RDD 本身沒有 reduceByKey,它是用了隐式转换,转换了PairRDDPartition 類裡的 reduceByKey 方法

它只看類型,看到自己需要的是 RDD,然後返回的是代碼需要的 PairRDDFunction ,就會調用這個隐式转换的方法。


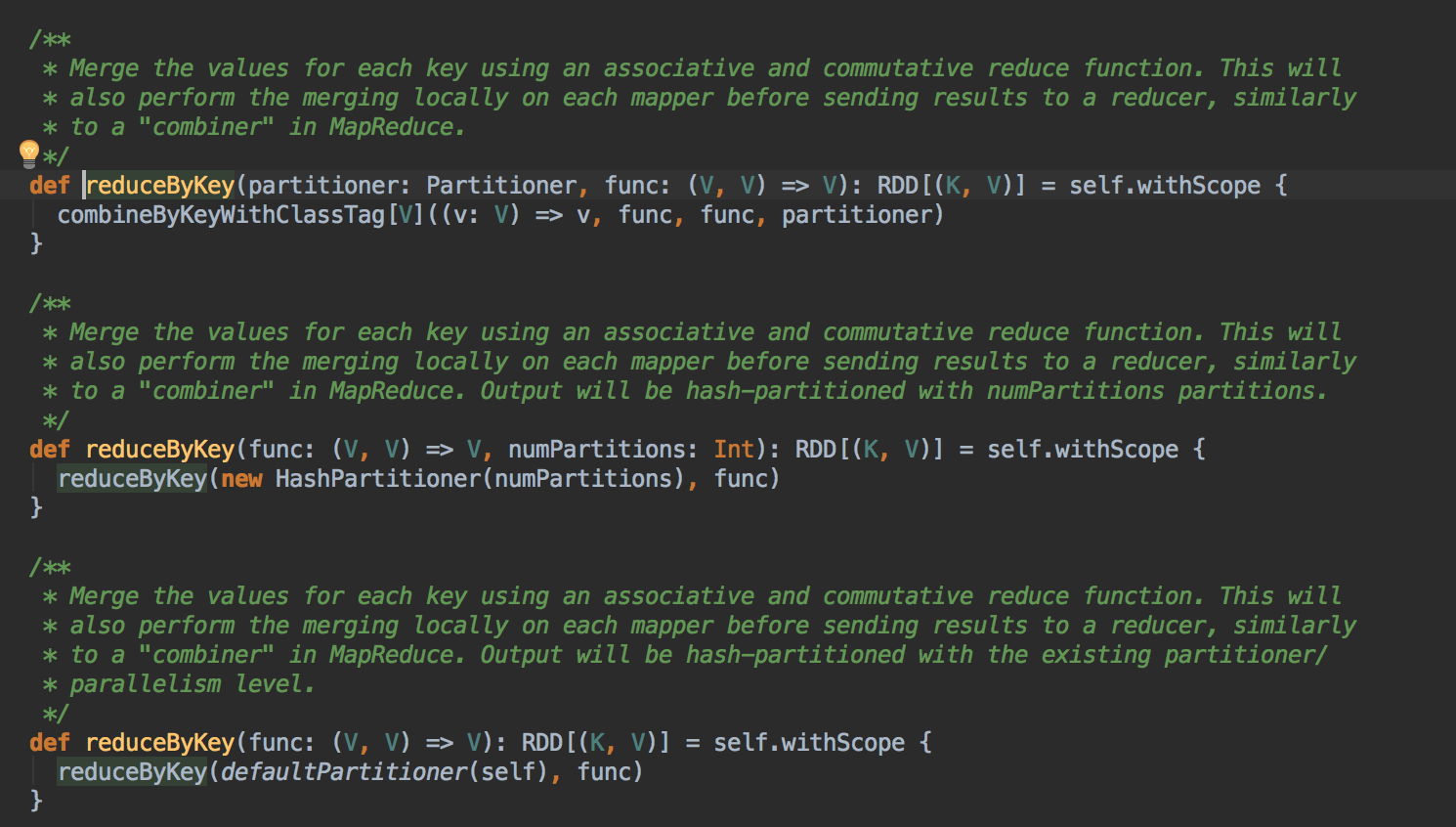
如果源對象、目標對象、伴生類、伴生對象都找不到這個隐式转换的話,就需要手動把它導進來,這對於代碼的重構也是非常重要的。
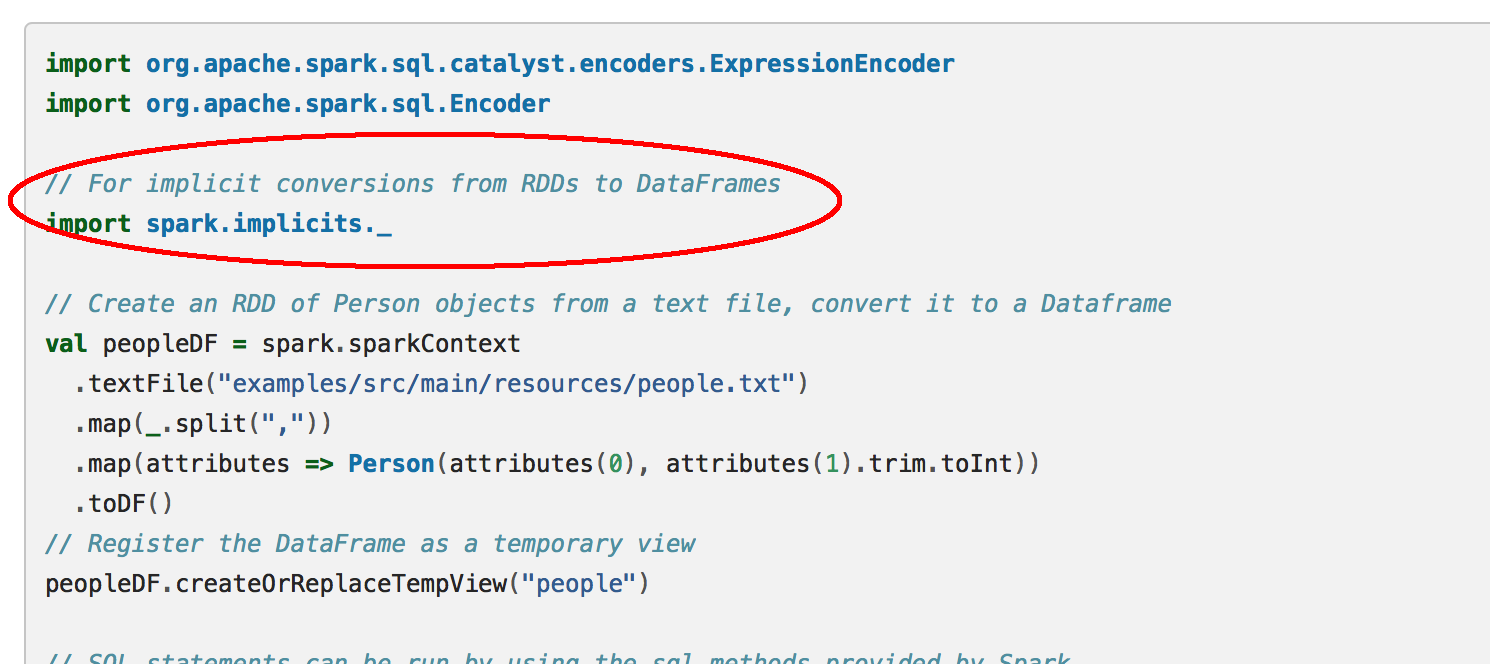
Scala的 implicit 编程操作实战
隐式转换有很多不同的部份,包括隐式參數、隐式转换、隐式類和隐式對象,隐式转换是 Scala 的特色。Scala 語言因為有隐式转换所以有出錯之前會判斷一下自己的伴生對象裡面有無 implicit 這種意義中可以出皇軍團能力的功能,如果有的話它就會調用隐式转换的方法來完成這次转换。
Scala 隐式转换有以下幾個方法
- 在伴生對象裡創建隐式转换的方法:
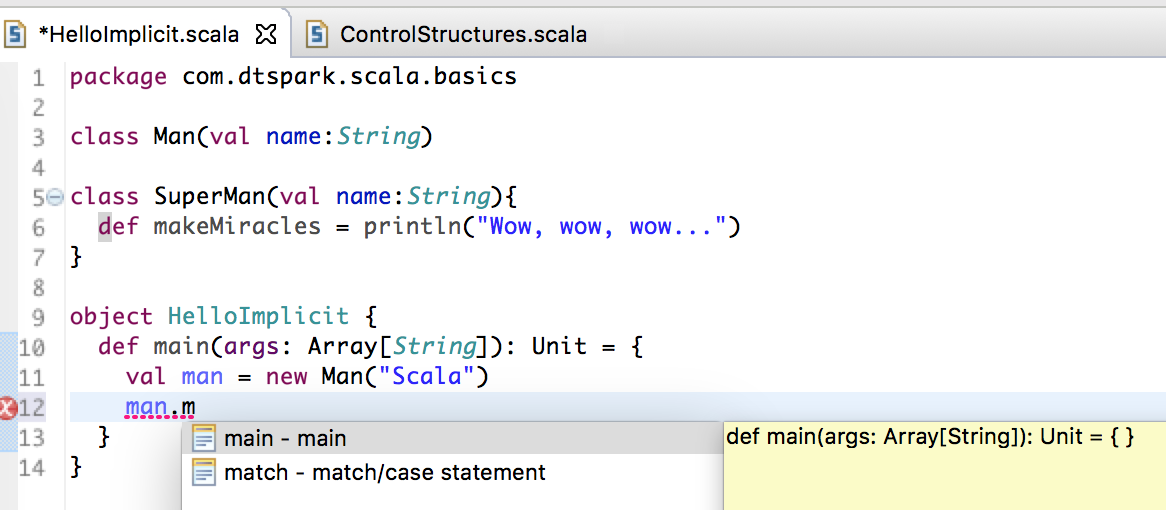
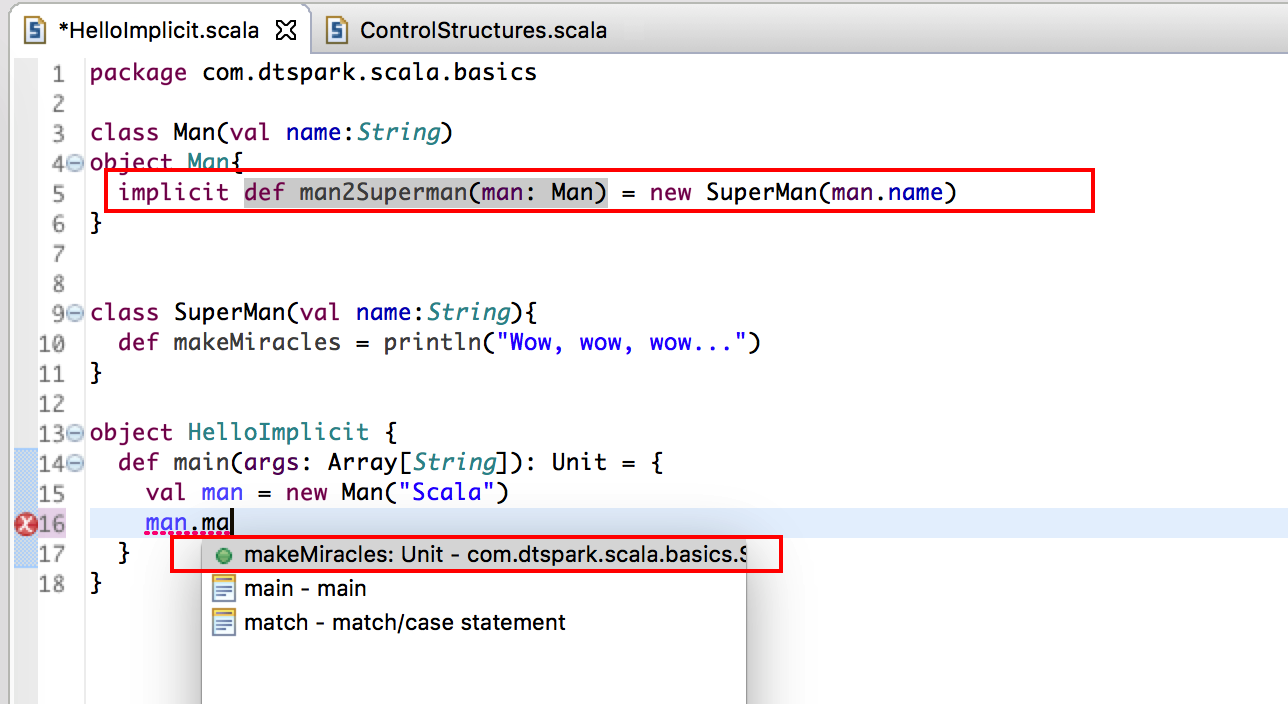
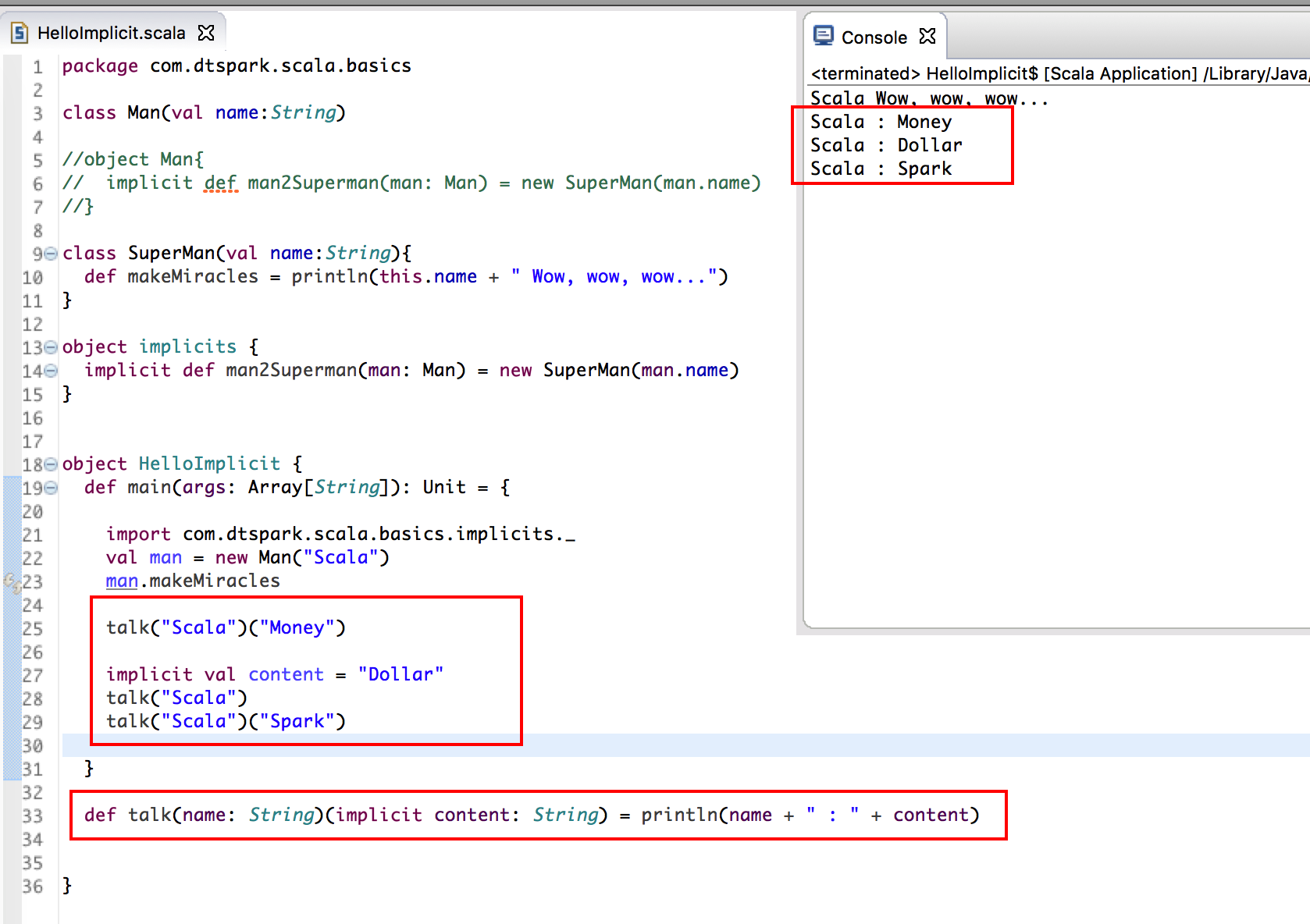
class Man 本身沒有 makeMiracles 的方法,如果想調用的話根本不可能。
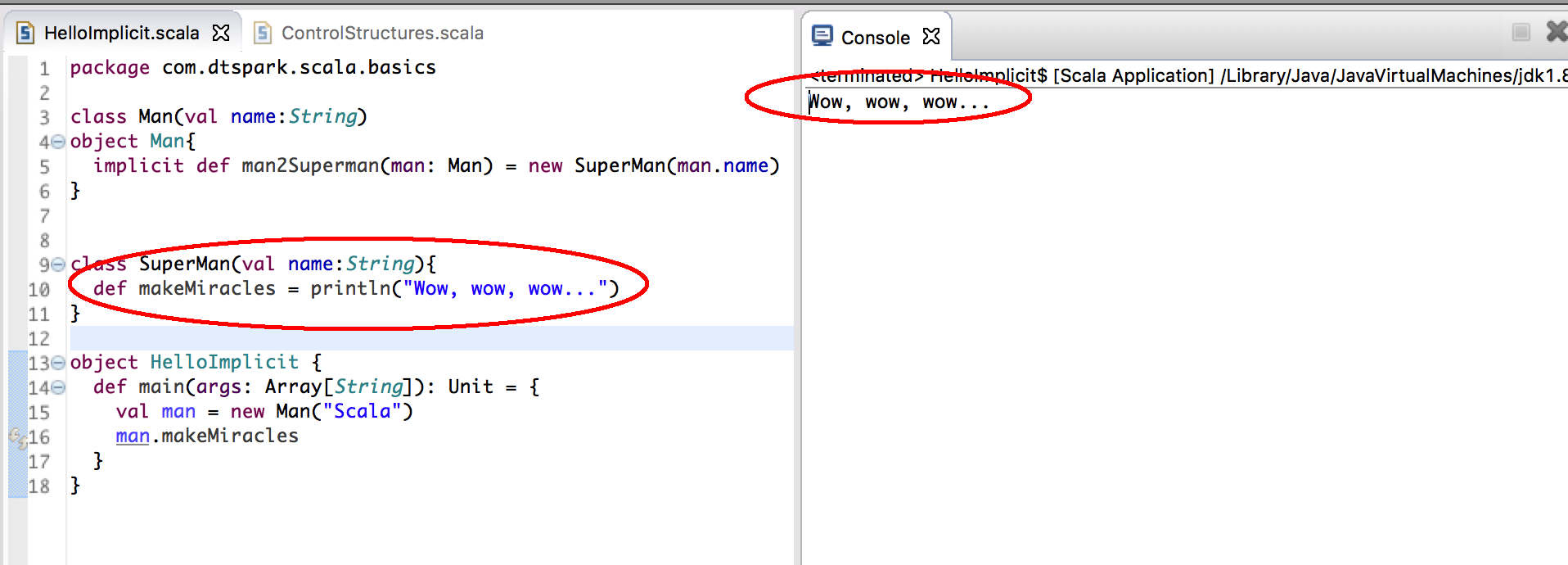
創建一個 Man 的 Object,如果在 Man 自己的伴生對象中加入了 implicit 的功能,它會在報錯的最後一刻找自己的伴生對象裡的功能!看看有沒有隐式转换的方法,發現有了!就會自動有 makeMiracles 的方法。隐式转换的成功!在這裡是加入隐式转换的功能,意義上是擴展了 class Man 的功能
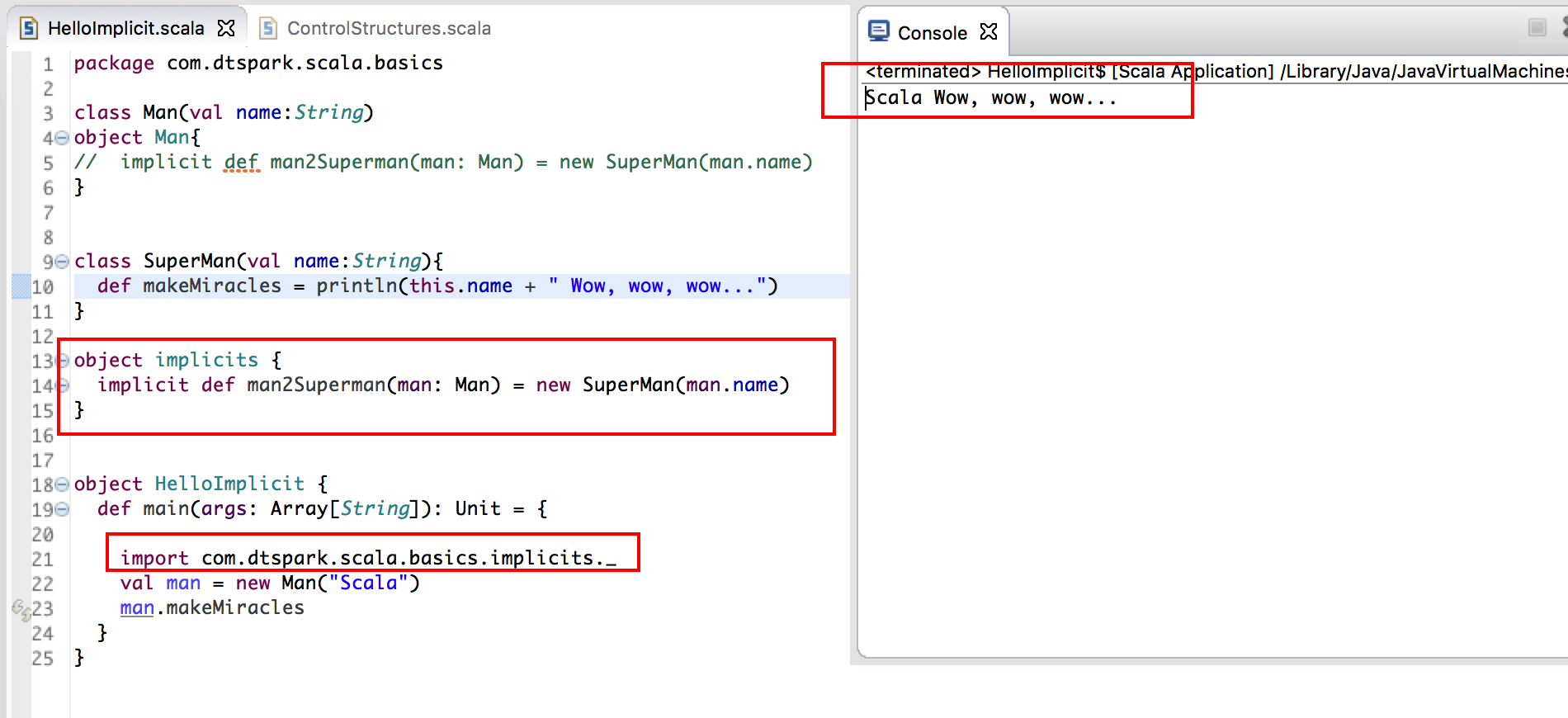
- 直接導入 implicit 的方法,在這個 SparkSQL 的例子中 implicit 是一個 object
在以下例子,也是首先創建了一個 implicit 的 object,然後把這個類的功能 import 進來,然後 man 也可以根據 implicit object 裡的功能進行隐式转换。
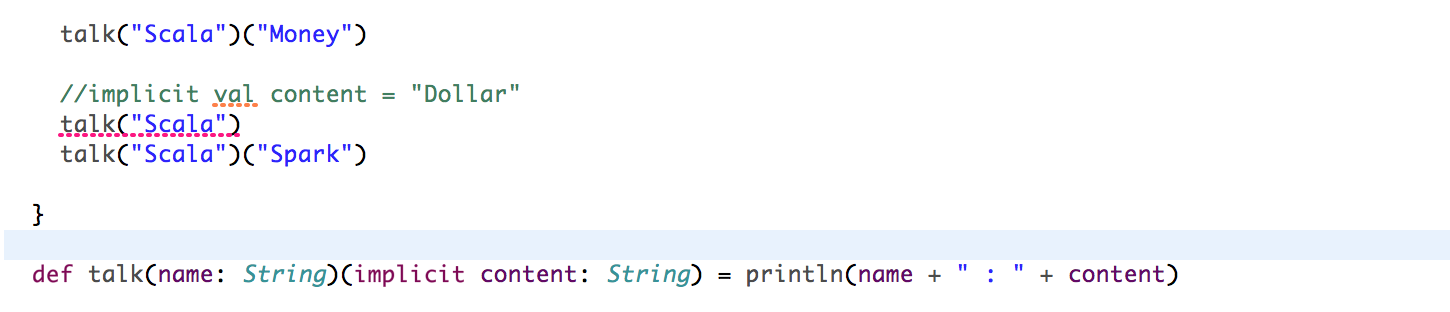
- 隐式參數,可以代為一個默認參數那樣把參數傳進去
先寫一個 Function: def talk(name: String)(implicit content: String) = println(name + " : " + content),第2個參數是一個隐式參數,然後調用 talk 方法,如果沒有隐式參數的話編譯器會報異常!此時,就可以定義一個隐式參數,這樣隐式转换成功啦!
















 772
772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









