 深度残差学习在图像识别中的优势
深度残差学习在图像识别中的优势








 深度残差网络解决了深度学习中网络加深导致准确率下降的问题。通过优化残差,网络能更轻松地训练出高效模型。在ImageNet上,152层的残差网络取得了3.57%的错误率,优于浅层网络。
深度残差网络解决了深度学习中网络加深导致准确率下降的问题。通过优化残差,网络能更轻松地训练出高效模型。在ImageNet上,152层的残差网络取得了3.57%的错误率,优于浅层网络。
概要
证明了残差网络更容易训练,而且网络更深的时候能够取得更高的准确率。在ImageNet数据集上我们使用152层的残差网络并取得了3.57%的错误率。
简介
深度网络一直存在梯度消散的问题,但最近这个问题已经被normalized initialization和batch normalization很大程度的解决了。另一个问题是网络效果变差,当网络深度增加的时候,准确率反而比层数低的网络要差,但它并不是因为Overfitting变差的,因为即使在训练集上,更深的网络的Train error比浅网络的Train error还要高。为什么会这样,论文没有很好的解释,只是说也许很难对更深的网络进行优化:如果对一个网络不断的加Layer,每一层新的Layer都是恒等变换,那么按理说新的网络最优的结果至少和旧的网络一样好甚至更好。但实验发现通过训练连达到旧网络的效果都很难。
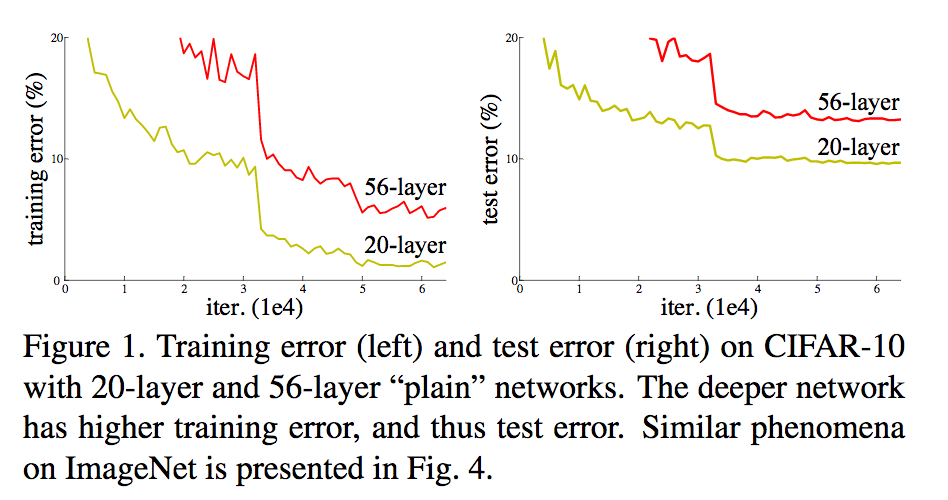
为了解决的这个问题,我们提出了深度残差网络,作者的观察是:与其让网络优化出我们想要的层与层间的参数(比如至少是恒等变换),不如我们直接让这些层去优化一个残差网络。优化一个残差网络要比优化原来的网络更容易。一个比较正式的描述是:假设H(x)是最优的参数,我们让网络是优化另一个参数F(X) = H(X) - X。这样,最坏情况下,假设是恒等变换,比起训练出恒等变换,训练出F(X)=0要简单得多。 这个方法的好处是它没有增加需要训练的参数个数,也没有增加训练的计算量,而且容易实现。

深度残差学习
残差网络模块可以包括许多个Layer,关键的地方是在模块输入和输出之间加一条恒等映射的边。在Fig
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1776
1776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









