with open('./articles.txt', 'r',encoding='utf-8') as f: for line in f.readlines(): line=line.strip('[SUCC]') with open('./articles2.txt', 'a',encoding='utf-8') as ff: ff.write(line.strip()) # 把末尾的'\n'删掉 ff.write("\n")
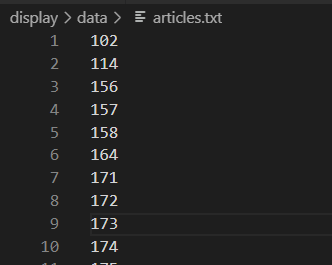
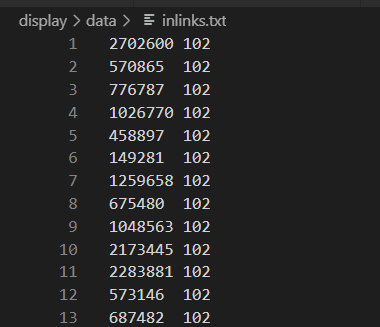
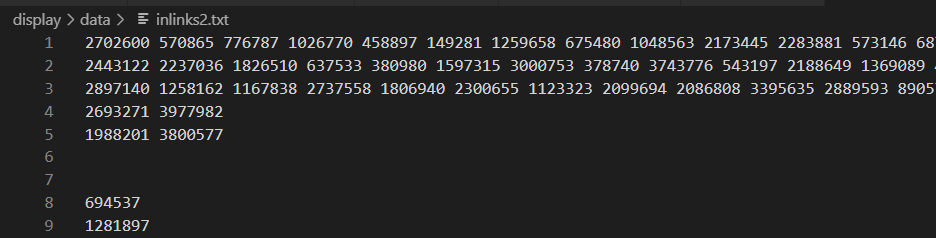
2.inlink.txt 里面的形式原本是 被引用论文id 引用论文id:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
//这个效率慢,不好! with open('./articles.txt', 'r', encoding='utf-8') as a: for id in a.readlines(): print(id.strip()) with open('./inlinks.txt', 'r', encoding='utf-8') as f: with open('./inlinks2.txt', 'a', encoding='utf-8') as ff: for line in f.readlines(): line = line.strip() line = line.split() # print(line[1]) if(id.strip() == line[1]): ff.write(line[0]) ff.write(" ") ff.write("\n")
# with open('./articles2.txt', 'a',encoding='utf-8') as ff: # ff.write(line.strip()) # 把末尾的'\n'删掉 # ff.write("\n")









 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 486
486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









