







参考博文:https://www.cnblogs.com/zhangfengxian/p/10614608.html
一、基于概率论的分类方法:朴素贝叶斯(常用于文本分类)
常用公式
1.条件概率公式:其中P(AB)为联合概率,如果A、B相互独立P(AB)=P(A)P(B)
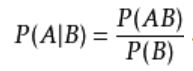

2.贝叶斯公式:其中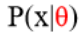
为似然函数

最大似然估计(maximum likelihood estimation ,MLE):


3.拉普拉斯平滑系数:
目的:防止计算出的分类概率为0
4.文本分类中朴素贝叶斯公式:


P(娱乐|影院,支付宝,云计算) =P(影院,支付宝,云计算|娱乐)P(娱乐) =P(影院|娱乐)*P(支付宝|娱乐)P(云计算|娱乐)P(娱乐)=)=(56+1/121+4)(15+1/121+4)(0+1/121+14)(60/90) = 0.00002
用到大数定理:概率=频率
二、R语言中朴素贝叶斯在文档分类中的应用
参考:https://www.cnblogs.com/wxyz94/p/8976407.html
接口:包:e1071 中的naiveBayes

setwd("D:\\")
x_train=read.csv("sms_train.csv")
x_train=as.matrix(x_train)
head(x_train)
str(x_train)
x_test=read.csv("sms_test.csv")
x_test=as.matrix(x_test)
y_train=read.csv("sms_train_labels.csv")
y_train=as.matrix(y_train)#数据框不支持,必须转换为矩阵
y_test=read.csv("sms_test_labels.csv")
y_test=as.matrix(y_test)
library(e1071)
?naiveBayes
model=naiveBayes(x =x_train,y=y_train,laplace = 1 )
y_predict <- predict(model,x_test)
library(gmodels)
CrossTable(y_predict,y_test,prop.chisq = FALSE,prop.t = FALSE,dnn=c(predicted,actual))
rm(list=ls())
三、python 代码:
多项式朴素贝叶斯接口:•sklearn.naive_bayes.MultinomialNB(alpha = 1.0)◦朴素贝叶斯分类
◦alpha:拉普拉斯平滑系数
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction import DictVectorizer
import pandas as pd
class Naive:
def naive_classifier(self):
x_train=pd.read_csv("D:\\sms_train.csv")
x_test=pd.read_csv("D:\\sms_test.csv")
y_train=pd.read_csv("D:\\sms_train_labels.csv")
y_test=pd.read_csv("D:\\sms_test_labels.csv")
#one-hot 编码
# dict = DictVectorizer(sparse=False)
# x_train=dict.fit_transform(x_train)
print(x_train)
pass
if __name__=="__main__":
naive=Naive()
naive.naive_classifier()
四、面试题汇总:
朴素贝叶斯为什么朴素?
它们相互独立,这就是他的朴素之处。
朴素对应英语单词naive,单纯的意思,所以也可以理解为很天真单纯的估计(把数据中的每个特征看作独立分布)。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









