




在我们日常办公中,经常使用到PDF格式的文件。比如打印投标文件采用PDF格式打印,材料采用PDF格式共享,电子合同采用PDF格式留存。但是因为PDF格式文件不能直接编辑、修改,很多人对PDF的第一印象就是“”麻烦、不好用”!
虽然PDF这么难用,但是为什么还这么多人和企业要求使用呢,主要有以下几个原因:
-
兼容性好:PDF格式可在几乎所有平台上使用,包括Windows、Mac和Linux等,而且现在不同浏览器都可以直接打开PDF格式文件,无需安装专门的PDF查看软件。
-
容量体积小:PDF文件通常比其他格式的文档更小,小体积文件更容易共享和下载(比如很多投标系统、带附件管理的平台,都要求上传PDF格式文件)。
-
安全性高:支持通过加密、签证、水印等操作来保护PDF文档,防止未经授权的用户访问和查看文档内容,同时,PDF格式很难编辑,这有助于原始内容不易被修改。
当然了,市面上也有支持修改PDF格式文件的软件,比如个人电脑安装的:国外的 Adobe Acrobat,国内的福昕PDF等。但是无论是Adobe Acrobat 还是福昕PDF,都需要激活码才能使用编辑等功能。
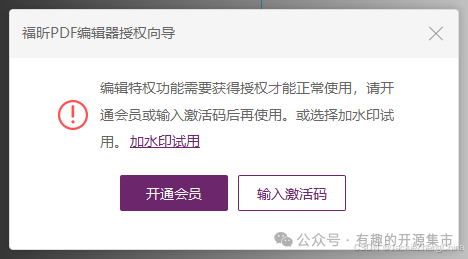
无需安装的在线PDF编辑也很多,但是很多时候先不说效果怎么样,很多在线编辑都是需要注册才可以使用。更有一些网站“玩套路”,在使用的时候,可以先上传文件,然后进行转换等处理,但是最后你点击下载文件时,才会提醒你需要注册登录,但是这个还不是最“套路的”,最套路的是,好不容易了注册才提示需要充值才能下载转换后的文档。


所以,今天给大家介绍一款可以本地部署、开源的,还没有任何广告套路的在线PDF工具箱-Stirling-PDF
01
—
Stirling-PDF 介绍
一句话介绍Stirling-PDF:一个功能强大的、本地部署的、在线访问的PDF工具箱,企业个人皆可用,提供了一系列丰富的PDF操作功能,通过简单的操作,就可以实现PDF合并、分割P、压缩、格式转换等功能。

🏠 项目信息
#github地址https://github.com/Stirling-Tools/Stirling-PDF#项目地址https://stirlingtools.com/
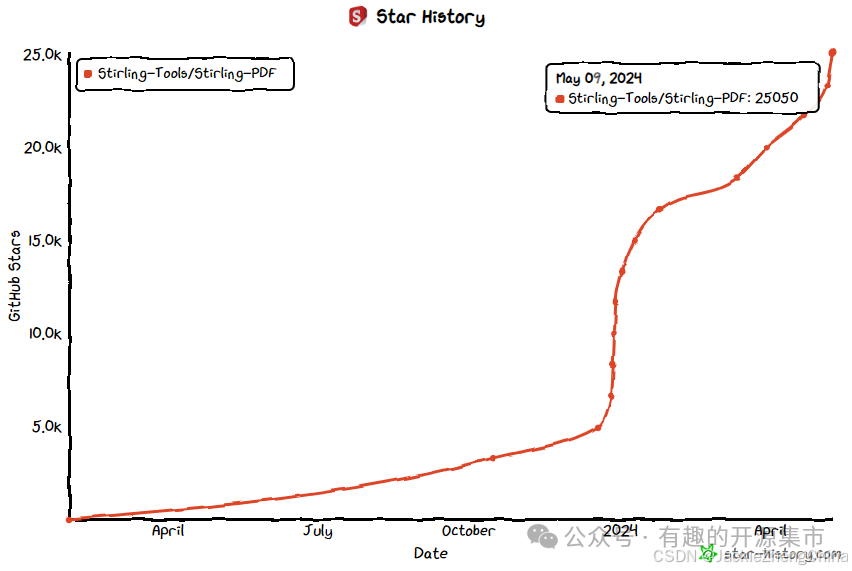
项目发布几个月的时间,Star 涨到了25K+,可见其受欢迎程度:
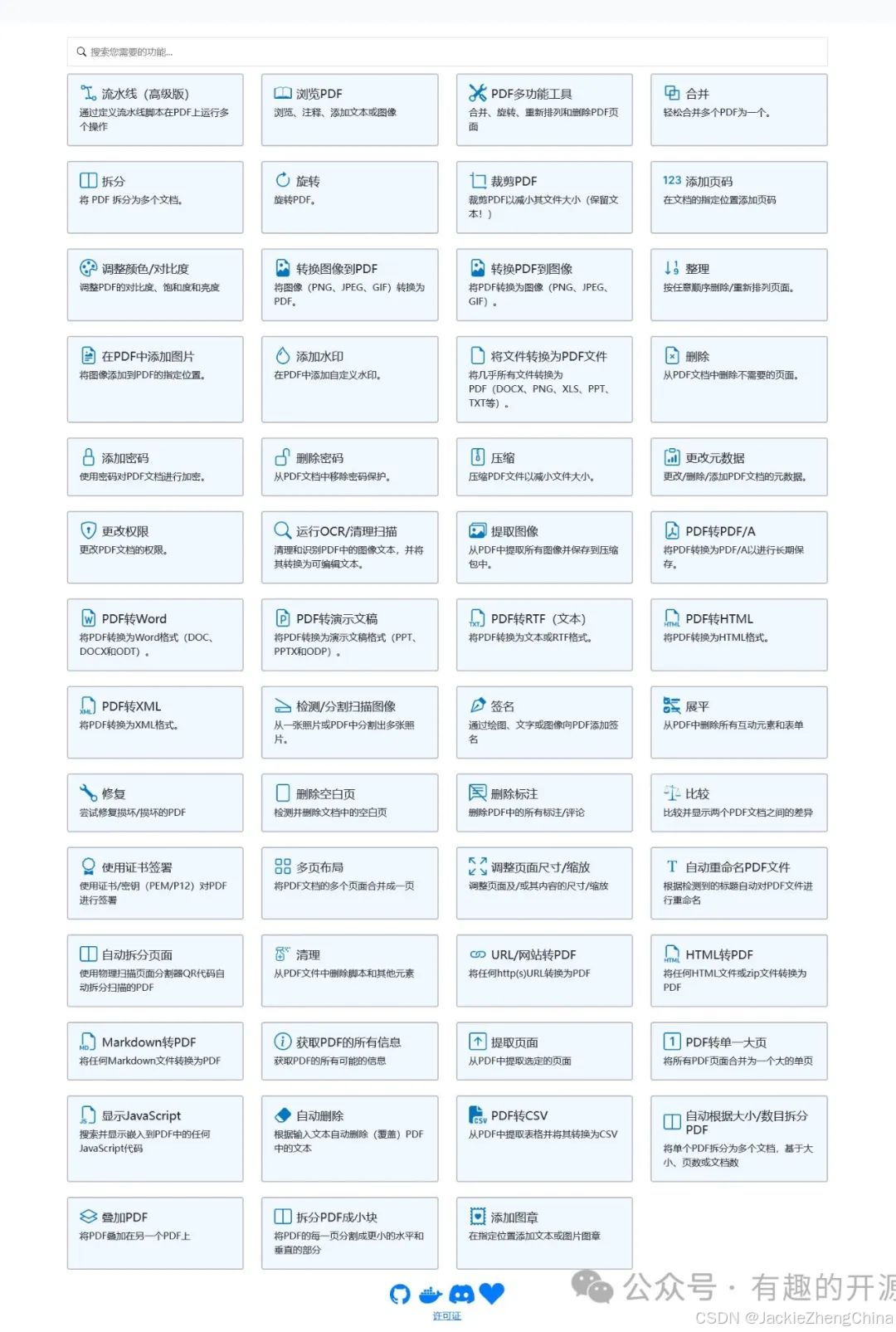
🚀功能特性
一页截图都放不下的功能:
02
—
Stirling-PDF 安装
一、Docker安装
Stirling-PDF提供了三种Docker镜像,不同的镜像除了大小不一样外,提供的功能也不一样,可以按照功能需求部署。(本文采用的full版本,最大的镜像)
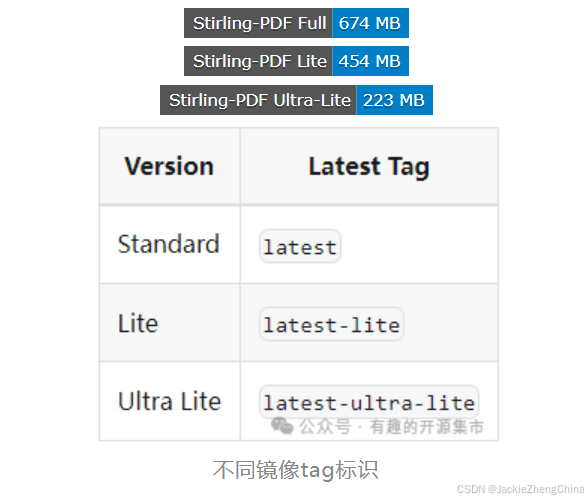
不同镜像提供的功能列表如下:
|
功能 |
Ultra-Lite |
Lite |
Full |
| 附加密码 | ✔️ | ✔️ | ✔️ |
| 加水印 | ✔️ | ✔️ | ✔️ |
| 证书签名 | ✔️ | ✔️ | ✔️ |
| 更改元数据 | ✔️ | ✔️ | ✔️ |
| 更改权限 | ✔️ | ✔️ | ✔️ |
| 对比 | ✔️ | ✔️ | ✔️ |
| 提取图像 | ✔️ | ✔️ | ✔️ |
| 压缩 | ✔️ | ✔️ | ✔️ |
| 图片转换PDF | ✔️ | ✔️ | ✔️ |
| 合并PDF | ✔️ | ✔️ | ✔️ |
| 多页布局 | ✔️ | ✔️ | ✔️ |
| PDF转换成图片 | ✔️ | ✔️ | ✔️ |
| 删除页面 | ✔️ | ✔️ | ✔️ |
| 删除密码 | ✔️ | ✔️ | ✔️ |
| 旋转页面 | ✔️ | ✔️ | ✔️ |
| 缩放页面 | ✔️ | ✔️ | ✔️ |
| PDF分割 | ✔️ | ✔️ | ✔️ |
| 添加图片 | ✔️ | ✔️ | ✔️ |
| 文件转换PDF格式 | ✔️ | ✔️ | |
| PDF转换HTML | ✔️ | ✔️ | |
| PDF转换TEXT | ✔️ | ✔️ | |
| PDF转换Word | ✔️ | ✔️ | |
| PDF转换XML | ✔️ | ✔️ | |
| PDF转换HTML | ✔️ | ✔️ | |
| PDF修复 | ✔️ | ✔️ | |
| xlsx转换PDF | ✔️ | ✔️ | |
| OCR提取 | ✔️ | ||
| 删除空白 | ✔️ |
#采用 docker run 部署全部功能版本的Stirling-PDFdocker run -d \-p 8080:8080 \-v /opt/trainingData:/usr/share/tessdata \-v /opt/extraConfigs:/configs \-v /opt/logs:/logs \-v /opt/customFiles:/customFiles \-e DOCKER_ENABLE_SECURITY=false \-e INSTALL_BOOK_AND_ADVANCED_HTML_OPS=false \-e LANGS=zh_CN \--name stirling-pdf \frooodle/s-pdf:latest
#采用 docker compose 部署全部功能版本的Stirling-PDFversion: '3.3'services:stirling-pdf:image: frooodle/s-pdf:latestports:- '8080:8080'volumes:- /opt/trainingData:/usr/share/tessdata #Required for extra OCR languages- /opt/extraConfigs:/configs- /opt/customFiles:/customFiles/- /opt/logs:/logs/environment:- DOCKER_ENABLE_SECURITY=false- INSTALL_BOOK_AND_ADVANCED_HTML_OPS=false- LANGS=zh_CNdocker-compose up -d
安装完成后,访问 http://hostip:8080,默认账号密码[demo/demo]。
二、Windows安装
如采用Windows安装,可以直接在github release界面下载EXE文件安装即可,下载链接:https://github.com/Stirling-Tools/Stirling-PDF/releases
03
—
Stirling-PDF 使用
Stirling-PDF 提供的功能很多,本章节只做简单介绍。
-
第一步,先调整为中文
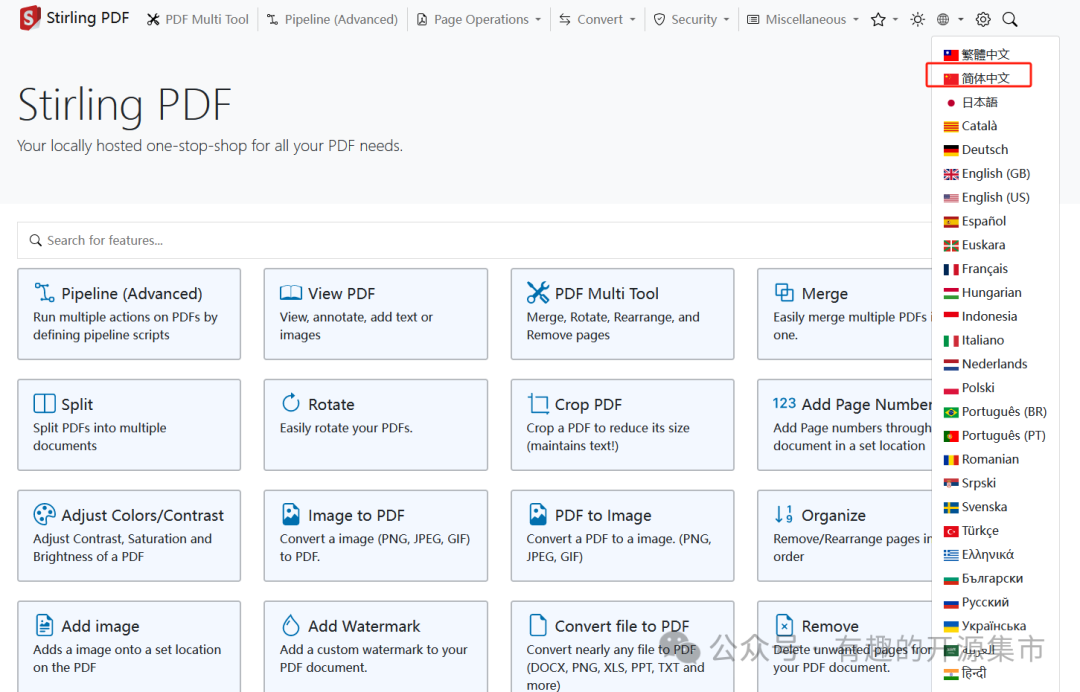
调整前
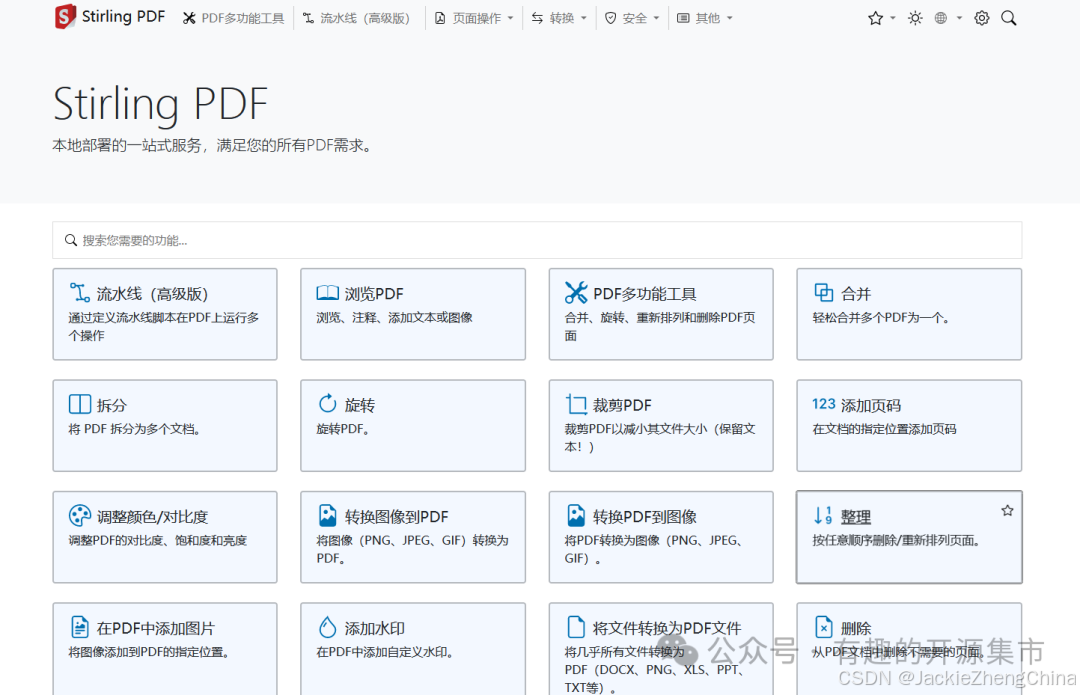
调整后
-
PDF转PPT(用的最多的功能)
# 转换后文件大小有点失真,但是微调编辑后即可,比一般工具效果要好(很多工具都是直接截图后转成PPT,无法编辑)
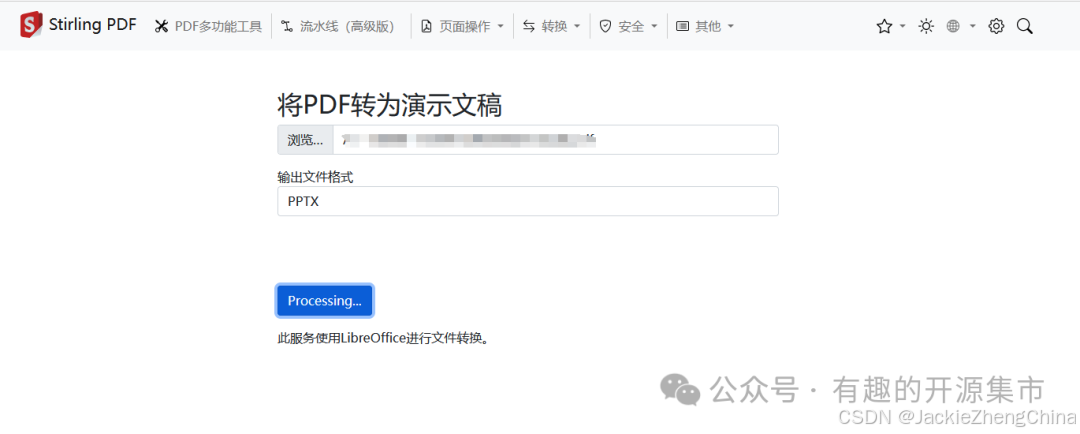
转换过程中,转换后浏览器会自动下载
-
浏览PDF

-
单个PDF文件合并、旋转、排序、删除
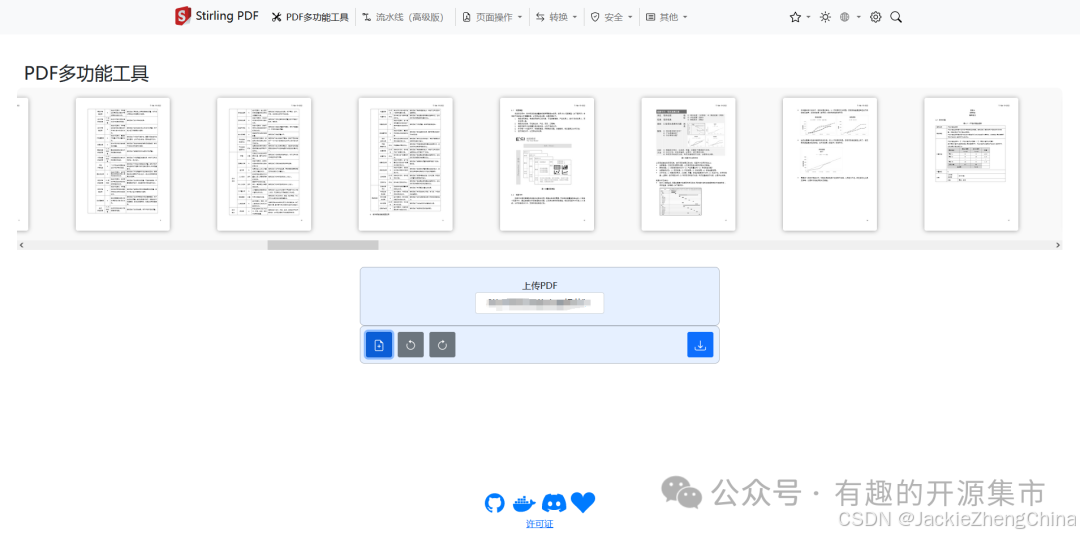
-
多个PDF合并
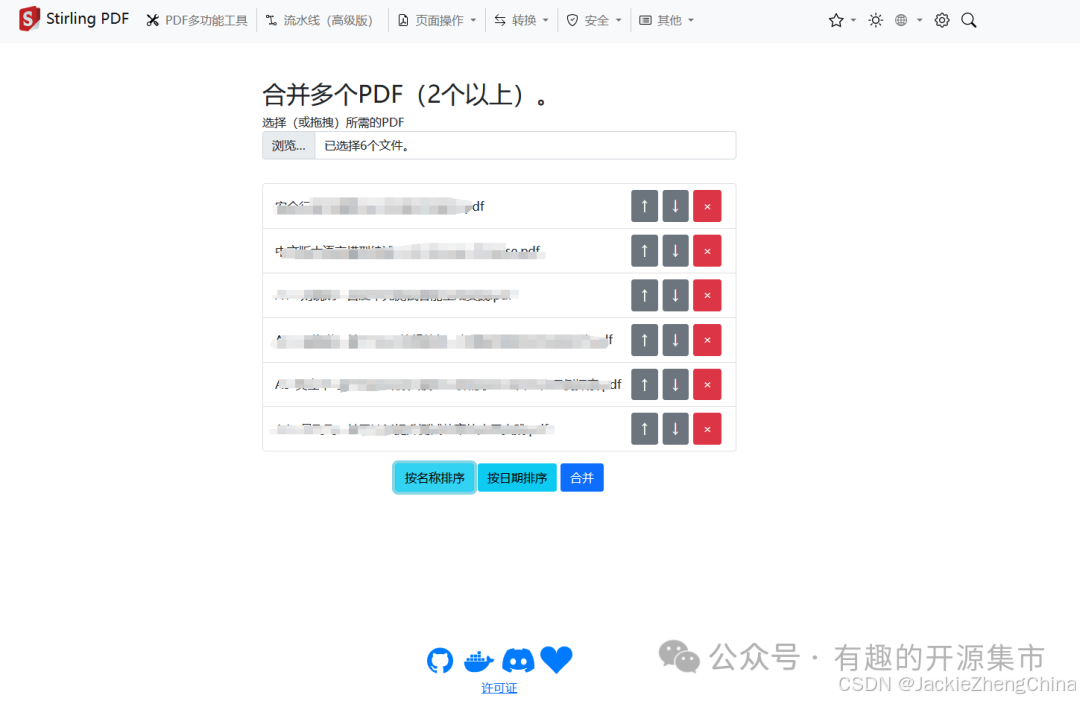
-
PDF添加水印
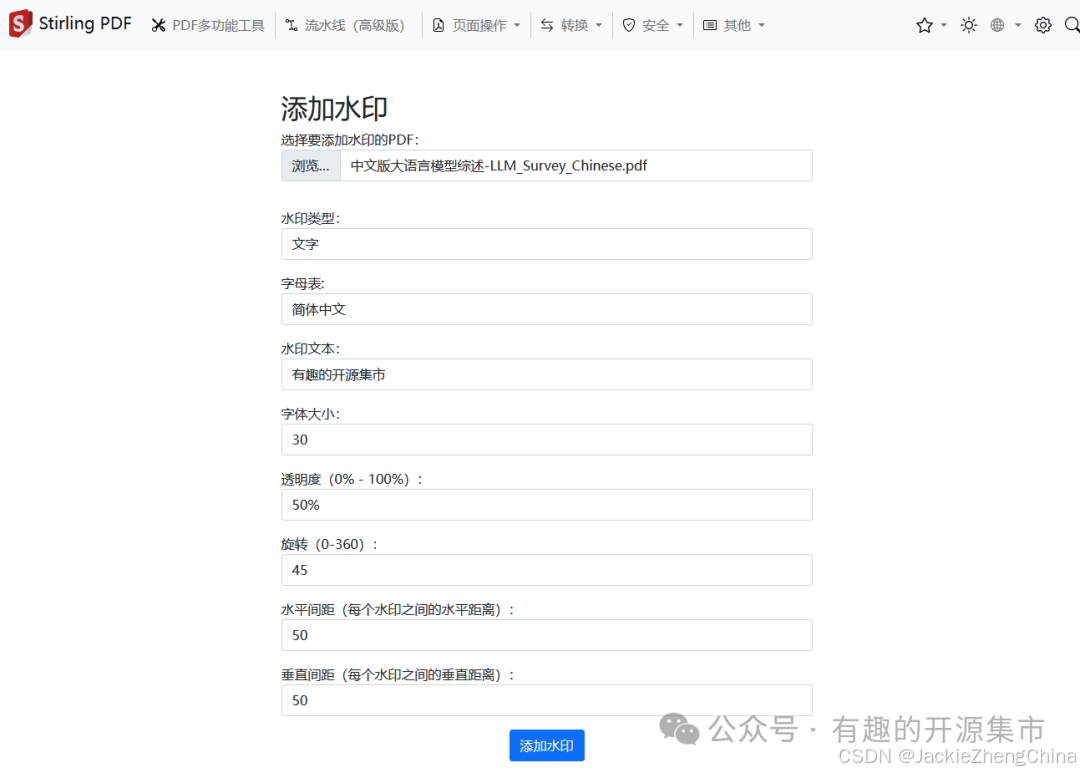
添加后,浏览器自动下载

添加效果
-
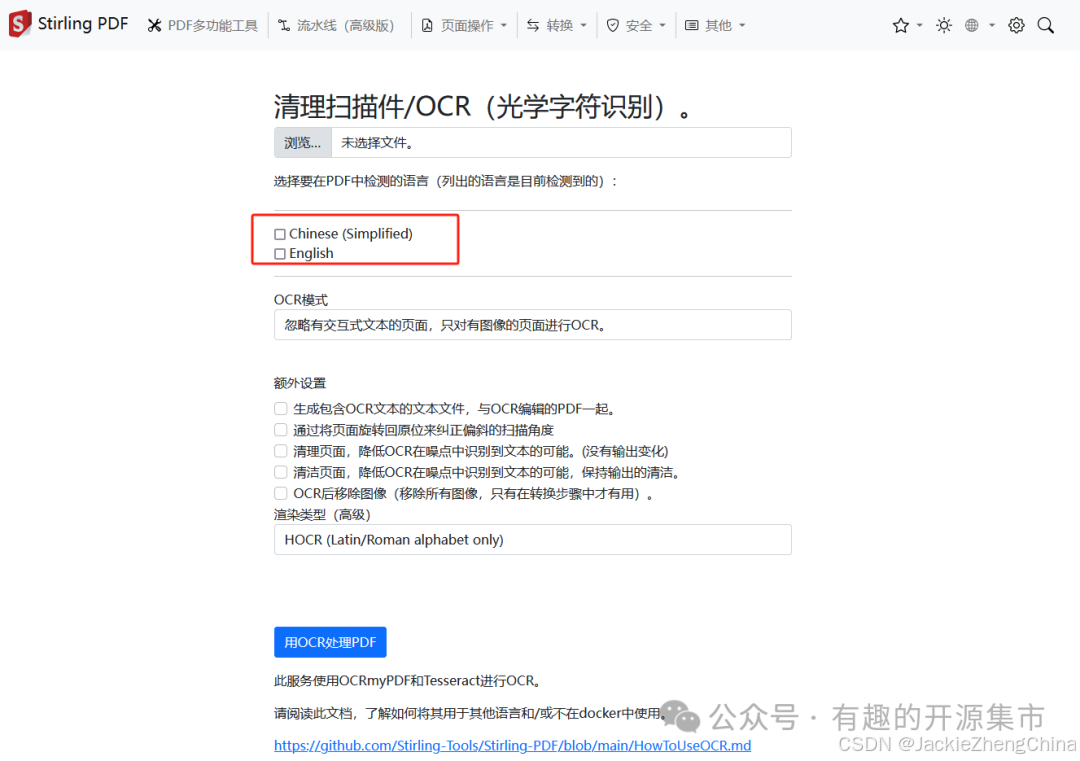
OCR扫描
默认的OCR扫描只支持英文的,需要自行下载中文模型:
# 参考文档地址https://github.com/Stirling-Tools/Stirling-PDF/blob/main/HowToUseOCR.md#
在tessdata 项目(https://github.com/tesseract-ocr/tessdata)中下载简体中文语言包:
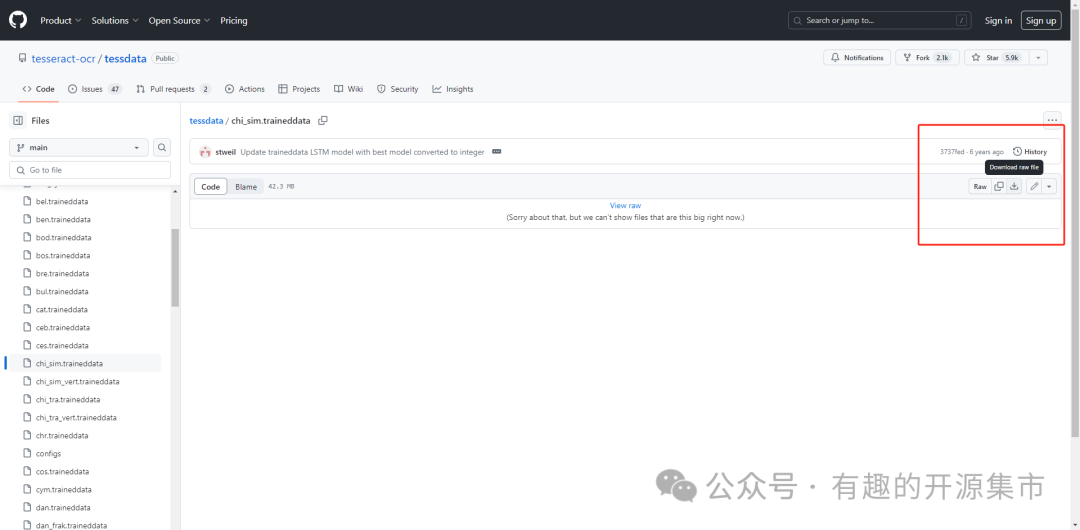
下载完成后,上传到部署服务 /opt/trainingData(需要参考上文docker部署的映射的目录地址) 目录下:
# 拷贝语言包至ocr目录mv chi_sim.traineddata /opt/trainingData
打开Stirling-PDF ORC 界面,可以看到已经具有中文识别选项:
识别后效果

04
—
最后
本文只是简单介绍了下 stirling-pdf 的使用,stirling-pdf 还具备很多其他的功能,如下图:

如果你已经受够了某些商业在线网站提供的PDF编辑功能,那么不防试试 stirling-pdf ,真的很强大!


















 4515
4515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









