







Python中的模块
# 模块(module)
# 模块化,模块化指将一个完整的程序分解为一个一个小的模块
# 通过将模块组合,来搭建出一个完整的程序
# 不采用模块化,统一将所有的代码编写到一个文件中
# 采用模块化,将程序分别编写到多个文件中
# 模块化的特点:
# ① 方便开发
# ② 方便维护
# ③ 模块可以复用!
创建一个test_module.py文件
# _*_ coding : utf-8 _*_
# @Time : 2023/6/17 8:45
# @Author : scx
# @File : test_module
# @Project : test02
print('打印test_module~~~')
创建一个module01.py文件
# 在Python中一个py文件就是一个模块,要想创建模块,实际上就是创建一个python文件
# 注意:模块名要符号标识符的规范
# 在一个模块中引入外部模块
# ① import 模块名 (模块名,就是python文件名字,注意不要带后缀.py)
# ② import 模块名 as 模块别名
# - 可以引入同一个模块多次,但是模块的实例只会创建一个
# - import可以在程序的任意位置调用,但是一般情况下,import语句都会统一写在程序的开头
# - 在每一个模块内部都有一个__name__属性,通过这个属性可以获取到模块的名字
# - __name__属性值为__maim__的模块是主模块,一个程序中只会有一个主模块
# 主模块就是我们直接通过python执行的模块
import test_module
import test_module
import test_module
#像上面这样引入多次,但是只会创建一个实例,即实际只被引入一次
import test_module as test
print(test.__name__) # 打印外部test模块的__name__属性值
print(__name__) # 打印当前主模块的__name__属性值
模块的具体使用
创建一个m.py文件
# _*_ coding : utf-8 _*_
# @Time : 2023/6/17 9:03
# @Author : scx
# @File : m
# @Project : test02
# 可以在模块中定义变量,在模块中定义的变量,在引入模块后,就可以直接使用了
a = 10
b = 20
# 添加了_的变量,只能在模块内部访问,在通过import * 引入时,不会引入_开头的变量
_c = 30
# 可以在模块中定义函数,同样可以通过模块访问到
def test():
print('test')
def test2():
print('test2')
# 也可以在模块中定义类,同样可以通过模块访问到
class Person:
def __init__(self, name):
self._name = name
@property
def name(self):
return self._name
# 编写测试代码,这部分代码,只要当前文件作为主模块的时候才需要执行
# 而当模块被其他模块引入时,不需要执行的,此时我们就必须要检查当前模块是否是主模块,否则将在其他引入此模块的主模块中被执行
if __name__ == '__main__':
test()
test2()
p = Person('孙悟空')
print(p.name)
创建一个module02.py文件,并引入m.py模块
# _*_ coding : utf-8 _*_
# @Time : 2023/6/17 9:05
# @Author : scx
# @File : module02
# @Project : test02
import m
# 访问模块中的变量 : 模块名.变量名
print(m.a, m.b)
m.test2()
p = m.Person('关云长')
print(p.name)
def test2():
print('这是主模块中的test2()函数~~~')
# 也可以引入模块中的部分内容
# 语法 from 模块名 import 变量,变量....
# from m import Person
# from m import test
# from m import Person, test
# from m import * # 引入模块中所有内容,一般不会使用
# p1 = Person('xxx')
# print(p1)
# test()
# 引入模块 就相当于将引入的模块中代码拷贝到当前模块内,如果有重名的方法怎么办?
# 在主模块中也定义一个test2()函数
# 在python中可以定义同名同参数类型的同作用域的方法,但是位置处于下面的会覆盖掉上面定义的方法。
# 如果主模块的test2函数的定义位置,在引入的模块此方法的定义的位置的上面,
# 则引入模块的中的此方法覆盖主模块中的此方法。
# 但是一般情况下,我们都把引入模块的语句写在最上面,所以一般情况下是,主模块中的此同名方法覆盖掉引入模块的此同名方法
# test2()
# 我们还想同时保留的话,可以这样引入外部模块的此方法,以至于不会覆盖掉主模块中的方法
# 可以这样为引入的变量使用别名
# 语法: from 模块名 import 变量 as 别名
from m import test2 as new_test2
test2()
new_test2()
Python中的包
创建一个python的包,也可以手动创建一个文件夹。手动创建的文件下,没有__init__.py文件,需要手动创建。而使用pycharm工具创建的包,会自动生成__init__.py文件。


a.py和b.py是pkg包下手动创建的两个模块
a.py内容:
# _*_ coding : utf-8 _*_
# @Time : 2023/6/17 10:07
# @Author : scx
# @File : a.py
# @Project : test02
c = 30
b.py内容:
# _*_ coding : utf-8 _*_
# @Time : 2023/6/17 10:07
# @Author : scx
# @File : b.py
# @Project : test02
d = 40
e = 50
创建一个package01.py文件
# _*_ coding : utf-8 _*_
# @Time : 2023/6/17 10:05
# @Author : scx
# @File : package01
# @Project : test02
# 包 Package
# 包也是一个模块
# 当我们模块中代码过多时,或者一个模块需要被分解为多个模块时,这时就需要使用到包
# 普通的模块就是一个py文件,而包是一个文件夹
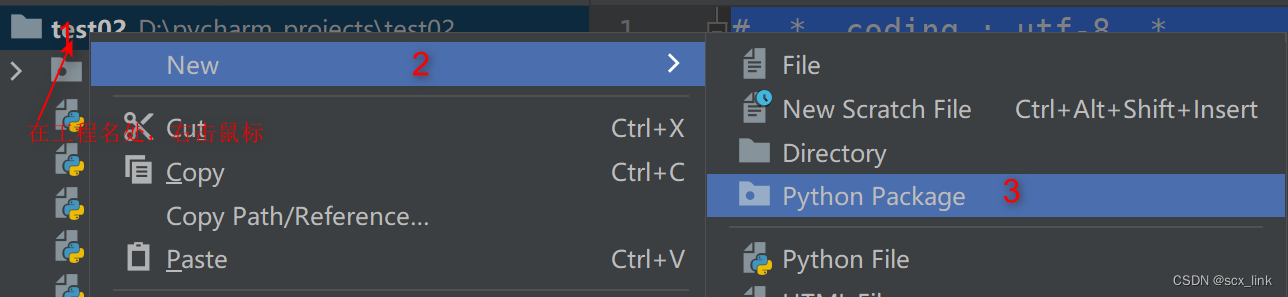
# 包中必须要有一个__init__.py文件,在Pycharm中右键点击工程名-->New-->Python Package,
# 在生成包后,会自动生这个__init__.py文件,这个文件中可以包含包中的主要内容
from pkg import a, b
print(a.c)
print(b.d)
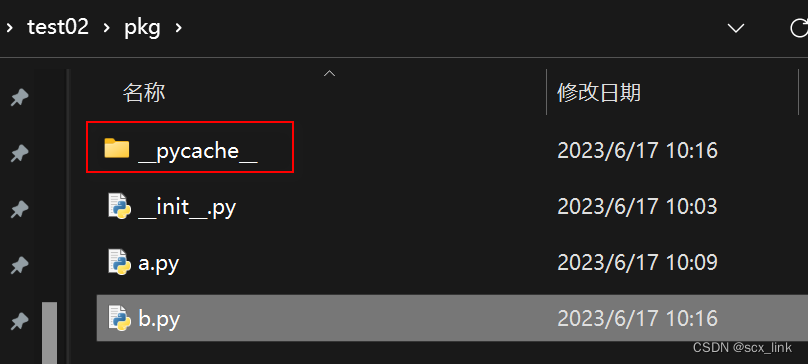
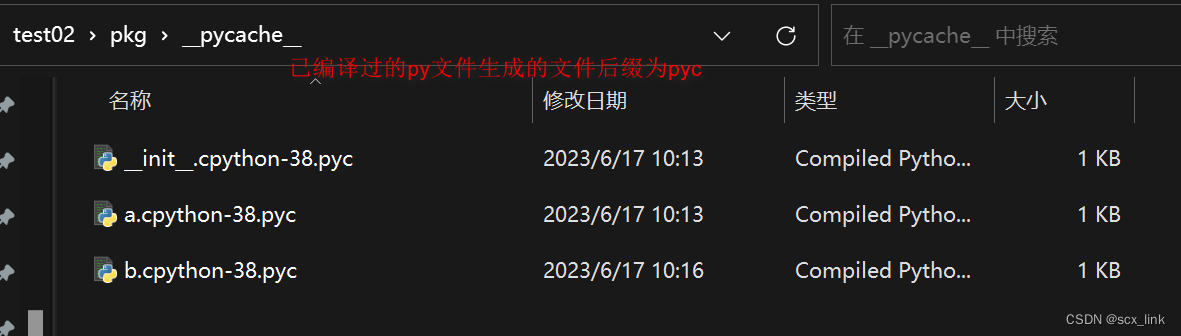
# __pycache__是模块的缓存文件,再模块(包)首次被加载时
# py代码在执行前,需要被解释器先转为机器码,然后再执行
# 所以我们在使用模块(包)时,也需要将模块的代码先转换为机器码然后再交由计算机执行
# 而为了提高程序运行的性能,python会在编译过一次以后,将代码保存到一个缓存文件中
# (再包中的py文件内容没有发生变化时)这样在下次加载这个模块(包)时,就可以不再重新编译而是直接加载缓存中编译好的代码即可
# (再包中的py文件内容有发生变化时)在下次加载这个模块(包)时,只会重新编译被修改的py文件。
注意:__pycache__文件在pycharm上不显示,看不到,我们需要通过文件管理器来看如下:















 900
900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









