







可与闭散列方式进行比较 >哈希表(闭散列)<
开散列
开散列法又叫链地址法(开链法)。
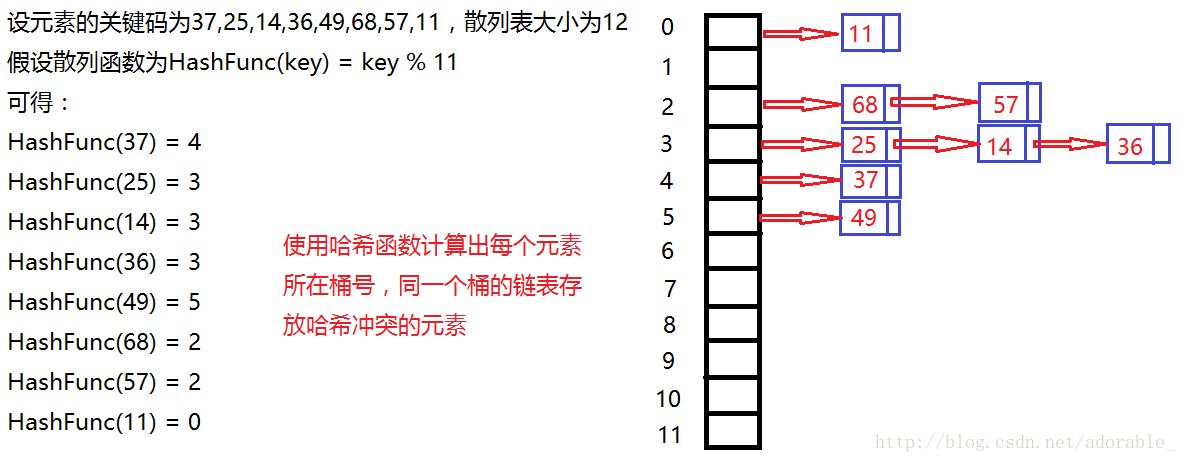
开散列法:首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各桶中的元素通过一个单链表链接起来,个链表的头结点存储在哈希表中。
基本原理如图所示:
具体实现代码:
①hash_table.h
#pragma once
#include <stddef.h>
#define HashMaxSize 1000
typedef int KeyType;
typedef int ValType;
typedef size_t(*HashFunc)(KeyType key);
typedef struct HashElem {
KeyType key;
ValType value;
struct HashElem* next;
} HashElem;
// 数组的每一个元素是一个不带头结点的链表
// 对于空链表, 我们使用 NULL 来表示
typedef struct HashTable {
HashElem* data[HashMaxSize];
size_t size;
HashFunc hash_func;
} HashTable;
void HashInit(HashTable* ht, HashFunc hash_func); //初始化
// 约定哈希表中不能包含 key 相同的值.
int HashInsert(HashTable* ht, KeyType key, ValType value); //插入
int HashFind(HashTable* ht, KeyType key, ValType* value); //查找
void HashRemove(HashTable* ht, KeyType key); //删除
size_t HashSize(HashTable* ht); //长度
int HashEmpty(HashTable* ht); //判空
void HashDestroy(HashTable* ht); //销毁
②hash_table.c
#include "hash_table.h"
#include <stdlib.h>
void HashInit(HashTable* ht, HashFunc hash_func) //初始化
{
if (ht == NULL)
{
return; //非法输入
}
ht->size = 0;
ht->hash_func = hash_func;
size_t i = 0;
for (; i < HashMaxSize; ++i)
{
ht->data[i] = NULL;
}
return;
}
HashElem* CreateHashElem(KeyType key, ValType value)
{
HashElem* new_node = (HashElem*)malloc(sizeof(HashElem));
new_node->key = key;
new_node->value = value;
new_node->next = NULL;
return new_node;
}
HashElem* HashBucketFind(HashElem* head, KeyType key)
{
HashElem *cur = head;
for (; cur != NULL; cur = cur->next)
{
if (cur->key == key)
{
return cur;
}
}
return NULL;
}
int HashInsert(HashTable* ht, KeyType key, ValType value) //插入
{
if (ht == NULL)
{
return 0; //非法输入
}
//1.根据hash函数将key转化成对应的数组下标
size_t offset = ht->hash_func(key);
//2.判定当前key在链表上是否存在
HashElem* ret = HashBucketFind(ht->data[offset], key);
// a)如果存在,插入失败
if (ret != NULL)
{
return 0;
}
// b)如果不存在,就用头插的方式将元素插入链表中
else
{
HashElem* new_node = CreateHashElem(key, value);
new_node->next = ht->data[offset];
ht->data[offset] = new_node;
ht->size++;
return 1;
}
}
int HashFind(HashTable* ht, KeyType key, ValType* value) //查找
{
if (ht == NULL || value == NULL)
{
return 0; //非法输入
}
//1.根据key找到对应的哈希桶
size_t offset = ht->hash_func(key);
//2.对该哈希桶进行链表查找
HashElem* ret = HashBucketFind(ht->data[offset], key);
// a)如果链表上没有找到对应的key,查找失败
if (ret == NULL)
{
return 0;
}
// b)如果链表上已存在对应的key,就把对应的节点的value返回出来
else
{
*value = ret->value;
return 1;
}
}
int HashBucketFindCurAndPre(HashElem* head, KeyType key, HashElem** cur_output, HashElem** pre_output)
{
HashElem* pre = NULL;
HashElem* cur = head;
for (; cur != NULL; pre = cur, cur = cur->next)
{
if (cur->key == key)
{
*pre_output = pre;
*cur_output = cur;
return 1;
}
}
return 0;
}
void DestroyHashElem(HashElem* elem)
{
free(elem);
}
void HashRemove(HashTable* ht, KeyType key) //删除
{
if (ht == NULL)
{
return; //非法输入
}
//1.根据key找到对应的哈希桶
size_t offset = ht->hash_func(key);
//2.对该哈希桶进行链表查找
HashElem* cur = NULL;
HashElem* pre = NULL;
int ret = HashBucketFindCurAndPre(ht->data[offset], key, &cur, &pre);
// a)如果链表上没有找到对应的key,删除失败
if (ret == 0)
{
return;
}
// b)如果链表上已存在对应的key,就把key从链表中删除
if (cur == ht->data[offset])
{
//刚好要删除的是头节点
ht->data[offset] = cur->next;
}
else
{
pre->next = cur->next;
}
DestroyHashElem(cur);
--ht->size;
return;
}
size_t HashSize(HashTable* ht) //长度
{
if (ht == NULL)
{
return 0; //非法输入
}
return ht->size;
}
int HashEmpty(HashTable* ht) //判空
{
if (ht == NULL)
{
return 0; //非法输入
}
return ht->size == NULL ? 1 : 0;
}
void HashDestroy(HashTable* ht) //销毁
{
//1.size设置为0
ht->size = 0;
//2.hash_func设置为空
ht->hash_func = NULL;
//3.销毁哈希桶上每个链表
size_t i = 0;
for (; i < HashMaxSize; ++i)
{
HashElem* cur = ht->data[i];
if (cur != NULL)
{
HashElem* to_delete = cur;
cur = cur->next;
DestroyHashElem(to_delete);
}
}
return;
}③test.c
#include "hash_table.h"
#include <stdio.h>
#include <windows.h>
#define TEST_HEADER printf("\n=========================%s=====================\n",__FUNCTION__)
size_t HashFuncDefault(KeyType key)
{
return key % HashMaxSize;
}
void HashPrintChar(HashTable* ht, const char* msg)
{
printf("[%s]:\n", msg);
size_t i = 0;
for (; i < HashMaxSize; ++i)
{
if (ht->data[i] == NULL)
{
continue;
}
printf("[%lu] ", i);
HashElem* cur = ht->data[i];
for (; cur != NULL; cur = cur->next)
{
printf("%d:%d ", cur->key, cur->value);
}
printf("\n");
}
}
void TestInit()
{
TEST_HEADER;
HashTable ht;
HashInit(&ht, HashFuncDefault);
printf("ht->size expect 0,actual %lu\n", ht.size);
printf("ht->hash_func expect %p,actual %p\n", HashFuncDefault, ht.hash_func);
size_t i = 0;
for (; i < HashMaxSize; ++i)
{
if (ht.data[i] != NULL)
{
printf("ht->data[%iu] error!", i);
}
}
}
void TestInsert()
{
TEST_HEADER;
HashTable ht;
HashInit(&ht, HashFuncDefault);
HashInsert(&ht, 1, 100);
HashInsert(&ht, 2, 200);
HashInsert(&ht, 1001, 300);
HashInsert(&ht, 1002, 400);
HashInsert(&ht, 1003, 500);
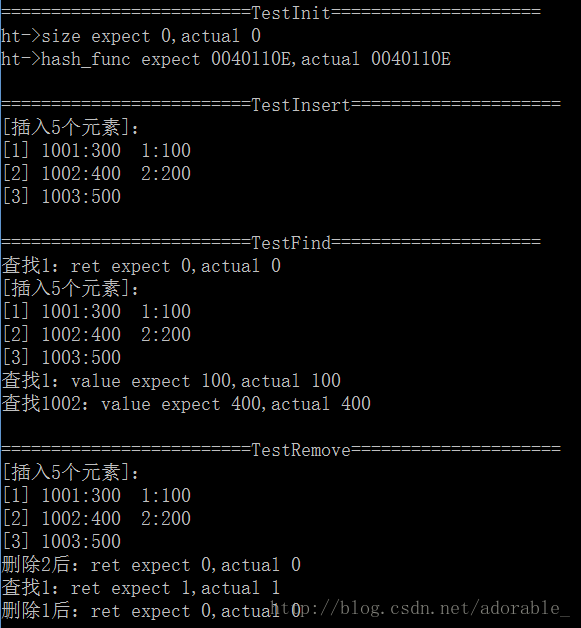
HashPrintChar(&ht, "插入5个元素");
}
void TestFind()
{
TEST_HEADER;
HashTable ht;
HashInit(&ht, HashFuncDefault);
int ret = 0;
int value = 0;
ret = HashFind(&ht, 1, &value);
printf("查找1:ret expect 0,actual %d\n", ret);
HashInsert(&ht, 1, 100);
HashInsert(&ht, 2, 200);
HashInsert(&ht, 1001, 300);
HashInsert(&ht, 1002, 400);
HashInsert(&ht, 1003, 500);
HashPrintChar(&ht, "插入5个元素");
ret = HashFind(&ht, 1, &value);
printf("查找1:value expect 100,actual %d\n", value);
ret = HashFind(&ht, 1002, &value);
printf("查找1002:value expect 400,actual %d\n", value);
}
void TestRemove()
{
TEST_HEADER;
HashTable ht;
HashInit(&ht, HashFuncDefault);
HashInsert(&ht, 1, 100);
HashInsert(&ht, 2, 200);
HashInsert(&ht, 1001, 300);
HashInsert(&ht, 1002, 400);
HashInsert(&ht, 1003, 500);
HashPrintChar(&ht, "插入5个元素");
HashRemove(&ht, 2);
int ret = 0;
int value = 0;
ret = HashFind(&ht, 2, &value);
printf("删除2后:ret expect 0,actual %d\n", ret);
ret = HashFind(&ht, 1, &value);
printf("查找1:ret expect 1,actual %d\n", ret);
HashRemove(&ht, 1);
ret = HashFind(&ht, 1, &value);
printf("删除1后:ret expect 0,actual %d\n", ret);
}
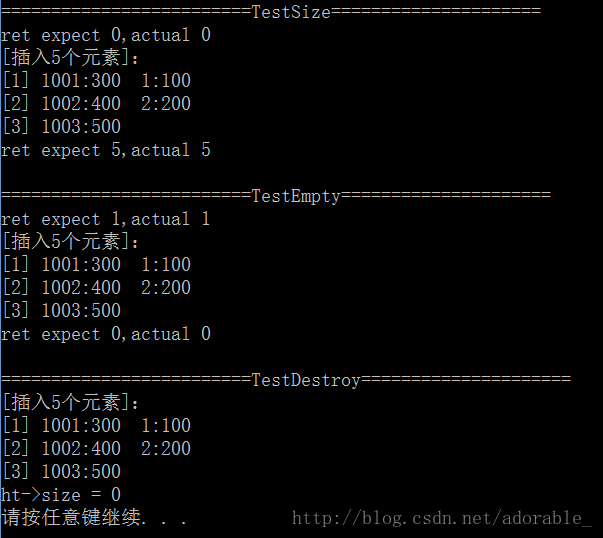
void TestSize()
{
TEST_HEADER;
HashTable ht;
HashInit(&ht, HashFuncDefault);
size_t ret = HashSize(&ht);
printf("ret expect 0,actual %lu\n", ret);
HashInsert(&ht, 1, 100);
HashInsert(&ht, 2, 200);
HashInsert(&ht, 1001, 300);
HashInsert(&ht, 1002, 400);
HashInsert(&ht, 1003, 500);
HashPrintChar(&ht, "插入5个元素");
ret = HashSize(&ht);
printf("ret expect 5,actual %lu\n", ret);
}
void TestEmpty()
{
TEST_HEADER;
HashTable ht;
HashInit(&ht, HashFuncDefault);
int ret = HashEmpty(&ht);
printf("ret expect 1,actual %lu\n", ret);
HashInsert(&ht, 1, 100);
HashInsert(&ht, 2, 200);
HashInsert(&ht, 1001, 300);
HashInsert(&ht, 1002, 400);
HashInsert(&ht, 1003, 500);
HashPrintChar(&ht, "插入5个元素");
ret = HashEmpty(&ht);
printf("ret expect 0,actual %lu\n", ret);
}
void TestDestroy()
{
TEST_HEADER;
HashTable ht;
HashInit(&ht, HashFuncDefault);
HashInsert(&ht, 1, 100);
HashInsert(&ht, 2, 200);
HashInsert(&ht, 1001, 300);
HashInsert(&ht, 1002, 400);
HashInsert(&ht, 1003, 500);
HashPrintChar(&ht, "插入5个元素");
HashDestroy(&ht);
printf("ht->size = %lu\n", ht.size);
}
int main()
{
TestInit();
TestInsert();
TestFind();
TestRemove();
TestSize();
TestEmpty();
TestDestroy();
system("pause");
return 0;
}结果如下:
字符串哈希算法
md5(非对称性哈希算法)特点:
•压缩性
•容易计算
•抗修改
•抗碰撞















 5653
5653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









