







 本文档介绍了开散列和闭散列的实现原理,包括使用单链表存储的开散列避免堆积但增加空间开销,以及采用顺序表存储的闭散列提高效率但可能引发堆积和查找困难。此外,还探讨了结合两者优点的溢出表。程序实现了这些散列结构的添加、查找和性能分析功能。
本文档介绍了开散列和闭散列的实现原理,包括使用单链表存储的开散列避免堆积但增加空间开销,以及采用顺序表存储的闭散列提高效率但可能引发堆积和查找困难。此外,还探讨了结合两者优点的溢出表。程序实现了这些散列结构的添加、查找和性能分析功能。
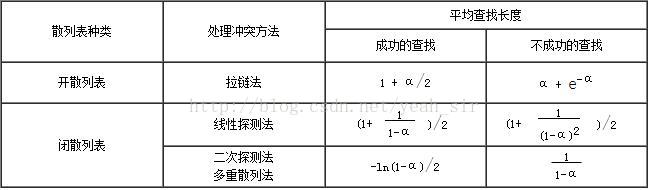
总程序实现了添加数据信息,建立开散列表,闭散列表,开散列和闭散列的查找,时间性能分析,还有溢出表的建立与查找这些功能。
下面分开说明原理:
开散列表:运用单链表存储方式,不产生堆积现象,但因为附加了指针域而增加了空间开销。
闭散列表:运用顺序表存储,存储效率较高,但容易产生堆积,查找不易实现,需要用到二次再查找。
溢出表:开、闭散列的结合运用,第一个顺序表存放类似指针域,第二个则存放溢出。
实现:
#include<iostream>
#include<cstdio>
#include<stdio.h>
#include<stdlib.h>
#define HashSize 53
#define MaxSize 20
using namespace std;
typedef struct
{
int key;
int si;
} HashTable1;
void CreateHashTable1(HashTable1 *H,int *a,int num)//哈希表线性探测在散列;
{
int i,d,cnt;
for(i=0; i<HashSize; i++)
{
H[i].key=0;
H[i].si=0;
}
for(i=0; i<num; i++)
{
cnt=1;
d=a[i]%HashSize;
if(H[d].key==0)
{
H[d].key=a[i];
H[d].si=cnt;
}
else
{
do
{
d=(d+1)%HashSize;
cnt++;
}
while(H[d].key!=0);
H[d].key=a[i];
H[d].si=cnt;
}
}
printf("\n线性再探索哈希表已建成!\n");
}
void SearchHash1(HashTable1 *h,int data)
{
int d;
d=data%HashSize;
if(h[d].key==data)
printf("数字%d的探查次数为 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1947
1947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









