hash表作为一种常见数据结构可以提供快速的插入和查找操作,不管哈希表中有多少个数据,插入和删除数据只需要接近O(1)的时间。这是具有非常大的优势。通常使用hash表速度会比树快,因为树需要O(N)时间级。不过hash表是基于数组的,创建后比较难扩展,使用不灵活。这样就注定需要面对动态内存问题,通常的思路是对数组进行扩展,将之前的数据复制到新的数组中并释放原来的内存。
hash表就是key—value键值对模型。将关键字映射为相应号码。依然是以关键字作为索引,例如字典,hash表就是非常适合这种数据的存储。从a到z的单词都写入内存,实现快速读写。
哈希函数
哈希函数是实现将一个大范围内的数字转化为一个小范围的数字。这个小范围的数字对应数组的下标。使用哈希函数向数组中插入数据后,这个数组就称为哈希表。通常%(取余)是办法中的一种。
哈希过程中的冲突
将大范围的数字转化为小范围的数字会出现冲突。因为是采用数组进行存储,可能会出现将几个不同的数据哈希化到同一个数组单元。这就形成了冲突。这时候需要解决这种冲突。方法之一就是在新开辟的数组中依次有序寻找空位进行存储。这就是地址开放法的由来。
开放地址法
根据以上hash函数计算数组下标时,当遇到数据存放的冲突时就需要重新找到数组的其他位置。关于开放地址法通常需要有三种方法:线性探测、二次探测、再哈希法。
线性探测
线性探测方法就是线性探测空白单元。当数据通过哈希函数计算应该放在700这个位置,但是700这个位置已经有数据了,那么接下来就应该查看701位置是否空闲,再查看702位置,依次类推。需要注意的是:当哈希表中接近被填满时,向表中插入数据就会效率很低,当hash表真的被填满了,这时候算法应该停止,在这之前应该对数组进行扩展,对hash表中的数据进行转移。
聚集
当哈希表越来越满时聚集越来越严重,这导致产生非常长的探测长度,后续的数据插入将会非常费时。通常数据超过三分之二满时性能下降严重,因此设计哈希表关键确保不会超过这个数据容量的一半,最多不超过三分之二。
线性探测的操作流程
线性探测就是使用算术取余的方法计算余数,当产生冲突时就通过线性递增的方法进行探测,一直到数组的位置为空,插入数据项即可。
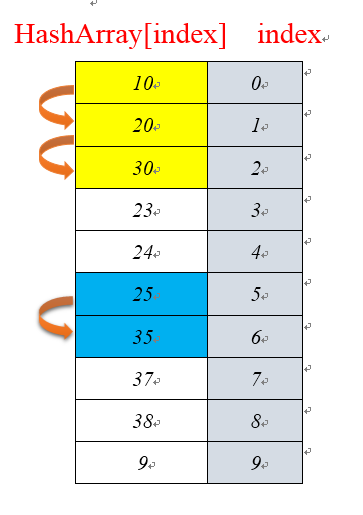
以上是通过一个长度是10的数组进行hash存储。对数据10 20 30 23 24 25 35 37 38 9进行储存,数组长度为10;那么当第一个10%10=0,即把10放入HashArray[0]位置上,当对下一个数字20进行存储时,计算20%10=0,此时HashArray[0]已经有数据了,其实通过线性探测对HashArray[1]进行探测。此时HashArray[1]null,将数据20插入该位置,其他数据插入同理。
该部分代码:
class ItemData
{
int data;
public ItemData(int data)
{
this








 本文详细介绍了哈希表的开放地址法,包括线性探测、二次探测和再哈希三种解决冲突的方法。线性探测在表满时效率降低,二次探测通过相隔较远的步长减少聚集,再哈希通过不同的哈希函数控制探测步长,避免聚集。此外,讨论了哈希表的装填因子、数组扩展和采用质数作为数组长度的原因。
本文详细介绍了哈希表的开放地址法,包括线性探测、二次探测和再哈希三种解决冲突的方法。线性探测在表满时效率降低,二次探测通过相隔较远的步长减少聚集,再哈希通过不同的哈希函数控制探测步长,避免聚集。此外,讨论了哈希表的装填因子、数组扩展和采用质数作为数组长度的原因。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1813
1813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









