









一.系统吞度量要素:
一个系统的吞度量(承压能力)与request对CPU的消耗、外部接口、IO等等紧密关联。
单个reqeust 对CPU消耗越高,外部系统接口、IO影响速度越慢,系统吞吐能力越低,反之越高。
系统吞吐量几个重要参数:QPS(TPS)、并发数、响应时间
QPS(TPS):每秒钟request/事务 数量
并发数: 系统同时处理的request/事务数
响应时间: 一般取平均响应时间
(很多人经常会把并发数和TPS理解混淆)
理解了上面三个要素的意义之后,就能推算出它们之间的关系:
QPS(TPS)= 并发数/平均响应时间
一个系统吞吐量通常由QPS(TPS)、并发数两个因素决定,每套系统这两个值都有一个相对极限值,在应用场景访问压力下,只要某一项达到系统最高值,系统的吞吐量就上不去了,如果压力继续增大,系统的吞吐量反而会下降,原因是系统超负荷工作,上下文切换、内存等等其它消耗导致系统性能下降。
决定系统响应时间要素
我们做项目要排计划,可以多人同时并发做多项任务,也可以一个人或者多个人串行工作,始终会有一条关键路径,这条路径就是项目的工期。
系统一次调用的响应时间跟项目计划一样,也有一条关键路径,这个关键路径是就是系统影响时间;
关键路径是有CPU运算、IO、外部系统响应等等组成。
二.系统吞吐量评估:
我们在做系统设计的时候就需要考虑CPU运算、IO、外部系统响应因素造成的影响以及对系统性能的初步预估。
而通常境况下,我们面对需求,我们评估出来的出来QPS、并发数之外,还有另外一个维度:日PV。
通过观察系统的访问日志发现,在用户量很大的情况下,各个时间周期内的同一时间段的访问流量几乎一样。比如工作日的每天早上。只要能拿到日流量图和QPS我们就可以推算日流量。
通常的技术方法:
1. 找出系统的最高TPS和日PV,这两个要素有相对比较稳定的关系(除了放假、季节性因素影响之外)
2. 通过压力测试或者经验预估,得出最高TPS,然后跟进1的关系,计算出系统最高的日吞吐量。B2B中文和淘宝面对的客户群不一样,这两个客户群的网络行为不应用,他们之间的TPS和PV关系比例也不一样。
A)淘宝
淘宝流量图:

淘宝的TPS和PV之间的关系通常为 最高TPS:PV大约为 1 : 11*3600 (相当于按最高TPS访问11个小时,这个是商品详情的场景,不同的应用场景会有一些不同)
B) B2B中文站
B2B的TPS和PV之间的关系不同的系统不同的应用场景比例变化比较大,粗略估计在1 : 8个小时左右的关系(09年对offerdetail的流量分析数据)。旺铺和offerdetail这两个比例相差很大,可能是因为爬虫暂的比例较高的原因导致。
在淘宝环境下,假设我们压力测试出的TPS为100,那么这个系统的日吞吐量=100*11*3600=396万
这个是在简单(单一url)的情况下,有些页面,一个页面有多个request,系统的实际吞吐量还要小。
无论有无思考时间(T_think),测试所得的TPS值和并发虚拟用户数(U_concurrent)、Loadrunner读取的交易响应时间(T_response)之间有以下关系(稳定运行情况下):
TPS=U_concurrent / (T_response+T_think)。
并发数、QPS、平均响应时间三者之间关系

来源:http://www.cnblogs.com/jackei/
软件性能测试的基本概念和计算公式
一、软件性能的关注点
对一个软件做性能测试时需要关注那些性能呢?
我们想想在软件设计、部署、使用、维护中一共有哪些角色的参与,然后再考虑这些角色各自关注的性能点是什么,作为一个软件性能测试工程师,我们又该关注什么?
首先,开发软件的目的是为了让用户使用,我们先站在用户的角度分析一下,用户需要关注哪些性能。
对于用户来说,当点击一个按钮、链接或发出一条指令开始,到系统把结果已用户感知的形式展现出来为止,这个过程所消耗的时间是用户对这个软件性能的直观印象。也就是我们所说的响应时间,当相应时间较小时,用户体验是很好的,当然用户体验的响应时间包括个人主观因素和客观响应时间,在设计软件时,我们就需要考虑到如何更好地结合这两部分达到用户最佳的体验。如:用户在大数据量查询时,我们可以将先提取出来的数据展示给用户,在用户看的过程中继续进行数据检索,这时用户并不知道我们后台在做什么。
用户关注的是用户操作的相应时间。
其次,我们站在管理员的角度考虑需要关注的性能点。
1、 相应时间
2、 服务器资源使用情况是否合理
3、 应用服务器和数据库资源使用是否合理
4、 系统能否实现扩展
5、 系统最多支持多少用户访问、系统最大业务处理量是多少
6、 系统性能可能存在的瓶颈在哪里
7、 更换那些设备可以提高性能
8、 系统能否支持7×24小时的业务访问
再次,站在开发(设计)人员角度去考虑。
1、 架构设计是否合理
2、 数据库设计是否合理
3、 代码是否存在性能方面的问题
4、 系统中是否有不合理的内存使用方式
5、 系统中是否存在不合理的线程同步方式
6、 系统中是否存在不合理的资源竞争
那么站在性能测试工程师的角度,我们要关注什么呢?
一句话,我们要关注以上所有的性能点。
二、软件性能的几个主要术语
1、响应时间:对请求作出响应所需要的时间
网络传输时间:N1+N2+N3+N4
应用服务器处理时间:A1+A3
数据库服务器处理时间:A2
响应时间=N1+N2+N3+N4+A1+A3+A2
2、并发用户数的计算公式
系统用户数:系统额定的用户数量,如一个OA系统,可能使用该系统的用户总数是5000个,那么这个数量,就是系统用户数。
同时在线用户数:在一定的时间范围内,最大的同时在线用户数量。
同时在线用户数=每秒请求数RPS(吞吐量)+并发连接数+平均用户思考时间
平均并发用户数的计算:C=nL / T
其中C是平均的并发用户数,n是平均每天访问用户数(login session),L是一天内用户从登录到退出的平均时间(login session的平均时间),T是考察时间长度(一天内多长时间有用户使用系统)
并发用户数峰值计算:C^约等于C + 3*根号C
其中C^是并发用户峰值,C是平均并发用户数,该公式遵循泊松分布理论。
3、吞吐量的计算公式
指单位时间内系统处理用户的请求数
从业务角度看,吞吐量可以用:请求数/秒、页面数/秒、人数/天或处理业务数/小时等单位来衡量
从网络角度看,吞吐量可以用:字节/秒来衡量
对于交互式应用来说,吞吐量指标反映的是服务器承受的压力,他能够说明系统的负载能力
以不同方式表达的吞吐量可以说明不同层次的问题,例如,以字节数/秒方式可以表示数要受网络基础设施、服务器架构、应用服务器制约等方面的瓶颈;已请求数/秒的方式表示主要是受应用服务器和应用代码的制约体现出的瓶颈。
当没有遇到性能瓶颈的时候,吞吐量与虚拟用户数之间存在一定的联系,可以采用以下公式计算:F=VU * R /
其中F为吞吐量,VU表示虚拟用户个数,R表示每个虚拟用户发出的请求数,T表示性能测试所用的时间
4、性能计数器
是描述服务器或操作系统性能的一些数据指标,如使用内存数、进程时间,在性能测试中发挥着“监控和分析”的作用,尤其是在分析统统可扩展性、进行新能瓶颈定位时有着非常关键的作用。
资源利用率:指系统各种资源的使用情况,如cpu占用率为68%,内存占用率为55%,一般使用“资源实际使用/总的资源可用量”形成资源利用率。
5、思考时间的计算公式
Think Time,从业务角度来看,这个时间指用户进行操作时每个请求之间的时间间隔,而在做新能测试时,为了模拟这样的时间间隔,引入了思考时间这个概念,来更加真实的模拟用户的操作。
在吞吐量这个公式中F=VU * R / T说明吞吐量F是VU数量、每个用户发出的请求数R和时间T的函数,而其中的R又可以用时间T和用户思考时间TS来计算:R = T / TS
下面给出一个计算思考时间的一般步骤:
A、首先计算出系统的并发用户数
C=nL / T F=R×C
B、统计出系统平均的吞吐量
F=VU * R / T R×C = VU * R / T
C、统计出平均每个用户发出的请求数量
R=u*C*T/VU
D、根据公式计算出思考时间
TS=T/R
永久链接 : http://www.ha97.com/5095.html
############################
Web性能测试的部分概况一般来说,一个Web请求的处理包括以下步骤:
(1)客户发送请求
(2)web server 接受到请求,进行处理;
(3)web server 向DB获取数据;
(4)web server生成用户的object(页面),返回给用户。给客户发送请求开始到最后一个字节的时间称为响应时间(第三步不包括在每次请求处理中)。
1.事务(Transaction)
在web性能测试中,一个事务表示一个“从用户发送请求->web server接受到请求,进行处理-> web server向DB获取数据->生成用户的object(页面),返回给用户”的过程,一般的响应时间都是针对事务而言的。
2.请求响应时间
请求响应时间指的是从客户端发起的一个请求开始,到客户端接收到从服务器端返回的响应结束,这个过程所耗费的时间,在某些工具中,响应通常会称为“TTLB”,即"time to last byte",意思是从发起一个请求开始,到客户端接收到最后一个字节的响应所耗费的时间,响应时间的单位一般为“秒”或者“毫秒”。一个公式可以表示:响应时间=网络响应时间+应用程序响应时间。标准可参考国外的3/5/10原则:
(1)在3秒钟之内,页面给予用户响应并有所显示,可认为是“很不错的”;
(2)在3~5秒钟内,页面给予用户响应并有所显示,可认为是“好的”;
(3)在5~10秒钟内,页面给予用户响应并有所显示,可认为是“勉强接受的”;
(4)超过10秒就让人有点不耐烦了,用户很可能不会继续等待下去;
3、事务响应时间
事务可能由一系列请求组成,事务的响应时间主要是针对用户而言,属于宏观上的概念,是为了向用户说明业务响应时间而提出的.例如:跨行取款事务的响应时间就是由一系列的请求组成的.事务响应时间是直接衡量系统性能的参数.
4.并发用户数
并发一般分为2种情况。一种是严格意义上的并发,即所有的用户在同一时刻做同一件事情或者操作,这种操作一般指做同一类型的业务。比如在信用卡审批业务中,一定数目的拥护在同一时刻对已经完成的审批业务进行提交;还有一种特例,即所有用户进行完全一样的 操作,例如在信用卡审批业务中,所有的用户可以一起申请业务,或者修改同一条记录。
另外一种并发是广义范围的并发。这种并发与前一种并发的区别是,尽管多个用户对系统发出了请求或者进行了操作,但是这些请求或者操作可以是相同的,也可以是不同的。对整个系统而言,仍然是有很多用户同时对系统进行操作,因此也属于并发的范畴。
可以看出,后一种并发是包含前一种并发的。而且后一种并发更接近用户的实际使用情况,因此对于大多数的系统,只有数量很少的用户进行“严格意义上的并发”。对于WEB性能测试而言,这2种并发情况一般都需要进行测试,通常做法是先进行严格意义上的并发测试。严格意义上的用户并发一般发生在使用比较频繁的模块中,尽管发生的概率不是很大,但是一旦发生性能问题,后果很可能是致命的。严格意义上的并发测试往往和功能测试关联起来,因为并发功能遇到异常通常都是程序问题,这种测试也是健壮性和稳定性测试的一部分。
用户并发数量:关于用户并发的数量,有2种常见的错误观点。 一种错误观点是把并发用户数量理解为使用系统的全部用户的数量,理由是这些用户可能同时使用系统;还有一种比较接近正确的观点是把在线用户数量理解为并发用户数量。实际上在线用户也不一定会和其他用户发生并发,例如正在浏览网页的用户,对服务器没有任何影响,但是,在线用户数量是计算并发用户数量的主要依据之一。
5.吞吐量
指的是在一次性能测试过程中网络上传输的数据量的总和.吞吐量/传输时间,就是吞吐率.
6、 TPS(transaction per second)
每秒钟系统能够处理的交易或者事务的数量.它是衡量系统处理能力的重要指标.
7、点击率
每秒钟用户向WEB服务器提 交的HTTP请求数.这个指标是WEB应用特有的一个指标:WEB应用是"请求-响应"模式,用户发出一次申请,服务器就要处理一次,所以点击是WEB应用能够处理的交易的最小单位.如果把每次点击定义为一个交易,点击率和TPS就是一个概念.容易看出,点击率越大,对服务器的压力越大.点击率只是一个性能参考指标,重要的是分析点击时产生的影响。需要注意的是,这里的点击并非指鼠标的一次单击操作,因为在一次单击操作中,客户端可能向服务器发出多个HTTP请求.
8.资源利用率
指的是对不同的系统资源的使用程度,例如服务器的CPU利用率,磁盘利用率等.资源利用率是分析系统性能指标进而改善性能的主要依据,因此是WEB性能测试工作的重点.
资源利用率主要针对WEB服务器,操作系统,数据库服务器,网络等,是测试和分析瓶颈的主要参考.在WEB性能测试中,更根据需要采集相应的参数进行分析。
| 指标 | 说明 |
| ProcessorTime | 服务器CPU占用率,一般平均达到70%时,服务就接近饱和 |
| Memory Available Mbyte | 可用内存数,如果测试时发现内存有变化情况也要注意,如果是内存泄露则比较严重 |
| Physicsdisk Time | 物理磁盘读写时间情况 |
Web服务器指标
| 指标 | 说明 |
| Requests Per Second(Avg Rps) | 平均每秒钟响应次数=总请求时间 / 秒数 |
| Avg time to last byte per terstion (mstes) | 平均每秒业务脚本的迭代次数 ,有人会把上面那个混淆 |
| Successful Rounds | 成功的请求 |
| Failed Requests | 失败的请求 |
| Successful Hits | 成功的点击次数 |
| Failed Hits | 失败的点击次数 |
| Hits Per Second | 每秒点击次数 |
| Successful Hits Per Second | 每秒成功的点击次数 |
| Failed Hits Per Second | 每秒失败的点击次数 |
| Attempted Connections | 尝试链接数 |
数据库服务器性能指标
| 指标 | 说明 |
| User 0 Connections | 用户连接数,也就是数据库的连接数量 |
| Number of deadlocks | 数据库死锁 |
| Butter Cache hit | 数据库Cache的命中情况 |
系统的瓶颈定义
| 性能项 | 命令 | 指标 |
| CPU限制 | vmstat | 当%user+%sys超过80%时 |
| 磁盘I/O限制 | Vmstat | 当%iowait超过40%(AIX4.3.3或更高版本)时 |
| 应用磁盘限制 | Iostat | 当%tm_act超过70%时 |
| 虚存空间少 | Lsps,-a | 当分页空间的活动率超过70%时 |
| 换页限制 | Iostat, stat | 虚存逻辑卷%tm_act超过I/O(iostat)的30%,激活的虚存率超过CPU数量(vmstat)的10倍时 |
| 系统失效 | Vmstat, sar | 页交换增大、CPU等待并运行队列 |
稳定系统的资源状态
| 性能项 | 资源 | 评价 |
| CPU占用率 | 70% | 好 |
| 85% | 坏 | |
| 90%+ | 很差 | |
| 磁盘I/0 | <30% | 好 |
| <40% | 坏 | |
| <50%+ | 很差 | |
| 网络 | <30%带宽 | 好 |
| 运行队列 | <2*CPU数量 | 好 |
| 内存 | 没有页交换 | 好 |
| 每个CPU每秒10个页交换 | 坏 | |
| 更多的页交换 | 很差 |
通俗理解:
日访问量
常用页面最大并发数
同时在线人数
访问相应时间
案例:
最近公司一个项目,是个门户网站,需要做性能测试,根据项目特点定出了主要测试项和测试方案:
一种是测试几个常用页面能接受的最大并发数(用户名参数化,设置集合点策略)
一种是测试服务器长时间压力下,用户能否正常操作(用户名参数化,迭代运行脚本)
一种则需要测试服务器能否接受10万用户同时在线操作,如果是用IIS做应用服务器的话,单台可承受的最大并发数不可能达到10万级,那就必须要使用集 群,通过多台机器做负载均衡来实现;如果是用websphere之类的应用服务器的话,单台可承受的最大并发数可以达到10万级,但为性能考虑还是必须要 使用集群,通过多台机器做负载均衡来实现;通常有1个简单的计算方式,1个连接产生1个session,每个session在服务器上有个内存空间大小的 设置,在NT上是3M,那么10万并发就需要300G内存,当然实际使用中考虑其他程序也占用内存,所以准备的内存数量要求比这个还要多一些。还有10万个用户同时在线,跟10万个并发数是完全不同的2个概念。这个楼上已经说了。但如何做这个转换将10万个同时在线用户转换成多少个并发数呢?这就必须要有大量的历史日志信息来支撑了。系统日志需要有同时在线用户数量的日志信息,还需要有用户操作次数的日志信息,这2个数据的比例就是你同时在线用户转换到并发数的比例。另外根据经验统计,对于1个JAVA开发的WEB系 统(别的我没统计过,给不出数据),一般1台双CPU、2G内存的服务器上可支持的最大并发数不超过500个(这个状态下大部分操作都是超时报错而且服务 器很容易宕机,其实没什么实际意义),可正常使用(单步非大数据量操作等待时间不超过20秒)的最大并发数不超过300个。假设你的10万同时在线用户转 换的并发数是9000个,那么你最少需要这样的机器18台,建议不少于30台。当然,你要是买个大型服务器,里面装有200个CPU、256G的内存,千 兆光纤带宽,就算是10万个并发用户,那速度,也绝对是嗖嗖的。
另外暴寒1下,光设置全部进入运行状态就需要接近6个小时。具体的可以拿1个系统来压一下看看,可能会出现以下情况:
1、服务器宕机;
2、客户端宕机;
3、从某个时间开始服务器拒绝请求,客户端上显示的全是错误;
4、勉强测试完成,但网络堵塞或测试结果显示时间非常长。假设客户端和服务器之间百兆带宽,百兆/10000=10K,那每个用户只能得到10K,这个速度接近1个64K的MODEM上网的速度;另外以上分析全都没考虑系统的后台,比如数据库、中间件等。
1、服务器方面:上面说的那样的PC SERVER需要50台;
2、网络方面:按每个用户50K,那至少5根百兆带宽独享,估计仅仅网络延迟就大概是秒一级的;
3、如果有数据库,至少是ORACLE,最好是SYSBASE,SQLSERVER是肯定顶不住的。数据库服务器至少需要10台4CPU、16G内存的机器;
4、如果有CORBA,那至少再准备10台4CPU、16G内存的机器;再加上负载均衡、防火墙、路由器和各种软件等,总之没个1000万的资金投入,肯定搞不定。
这样的门户系统,由于有用户权限,所以并不象jackie所说大多是静态页面。但只要是多服务器的集群,那么我们就可以通过1台机器的测试结果来计算多 台机器集群后的负载能力的,最多额外考虑一下负载均衡和路由上的压力,比如带宽、速度、延迟等。但如果都是在1台机器上变化,那我们只能做一些指标上的计 算,可以从这些指标上简单判断一下是否不可行,比如10万并发用户却只有1根百兆带宽,那我们可以计算出每个用户只有1K带宽,这显然是不可行的。但实际 的结果还是需要测试了才知道,毕竟系统压力和用户数量不是线性变化的。
这一类系统的普遍的成熟的使用,以及很多软件在方案设计后就能够大致估算出系统的性能特点,都导致了系统在软件性能方面调优的比例并不大(当然不完全排 除后期针对某些代码和配置进行优化后性能的进一步提高),更多的都是从硬件方面来考虑,比如增加内存、硬盘做RAID、增加带宽、甚至增加机器等。
网络技术中的10M 带宽指的是以位计算, 就是 10M bit /秒 ,而下载时的速度看到的是以字节(Byte)计算的,所以10M带宽换算成字节理论上最快下载速度为: 1.25 M Byte/秒!
#################################################3
性能测试的难点不在于测,在于测出的数据和实际的对照关系,以及测试出来的数据对性能的评估(到底是好,还是不好)。
淘宝性能测试白皮书,解决了我的4个问题:1、PV到TPS的转换关系。2、TPS的波动标准。3、压力变化以及测试类型。4、网页测试的标准(可惜很多数据都抹掉了)
1、PV到TPS的转换
日PV对于一个网站,很容易就统计出来,但是LoadRunner性能测试时,只有TPS可供参考。日PV和TPS之间如何对应?公式就是80%的日PV,发生在T小时内。则公式为:
TPS = 日PV * 80% / 24 * 60 * 60 * (T/24)
定义 R = 1万 * 80% / 24 * 60 * 60 * (T/24) = 10000 * 24 * 0.8 / 24 * 3600 * T = 2.2222/T
TPS = 日PV(万) * R 这里的TPS就是平均的TPS。
可以T的值代入,则求出R的值即可
T 6 8 10 12
R 0.3704 0.2778 0.2222 0.1852
10w 3.704 2.778 2.222 1.852
100w 37.04 27.78 22.22 18.52
1000w 370.4 277.8 222.2 185.2
1亿 3704 2778 2222 1852
关于TPS 我再多说两句,单就静态页面,TPS大概能到1W+,简单数据库操作大概2K+的样子,用Cache大概能到5K+。
峰值的TPS,可以从图中看出来。
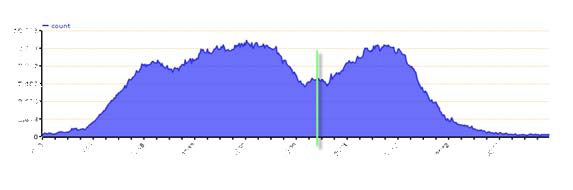
2、TPS的波动标准
TPS应该是一个比较平稳的曲线,而不是上下波动
TPS波动范围 = TPS标准差/TPS平均值 * 100%
在5%内算是正常的
3、测试压力变化
pdf中的图1-8
a点:性能期望值
b点:高于期望,系统资源处于临界点
c点:高于期望,拐点
d点:超过负载,系统崩溃
性能测试
a点到b点之间的系统性能
定义:狭义的性能测试,是指以性能预期目标为前提,对系统不断施加压力,验证系统在资源可接受范围内,是否能达到性能预期。
负载测试
b点的系统性能
定义:狭义的负载测试,是指对系统不断地增加压力或增加一定压力下的持续时间,直到系统的某项或多项性能指标达到极限,例如某种资源已经达到饱和状态等。
压力测试
b点到d点之间
定义:狭义的压力测试,是指超过安全负载的情况下,对系统不断施加压力,是通过确定一个系统的瓶颈或不能接收用户请求的性能点,来获得系统能提供的最大服务级别的测试。
稳定性测试
a点到b点之间
定义:狭义的稳定性测试,是指被测试系统在特定硬件、软件、网络环境条件下,给系统加载一定业务压力,使系统运行一段较长时间,以此检测系统是否稳定,一般稳定性测试时间为n*12小时。
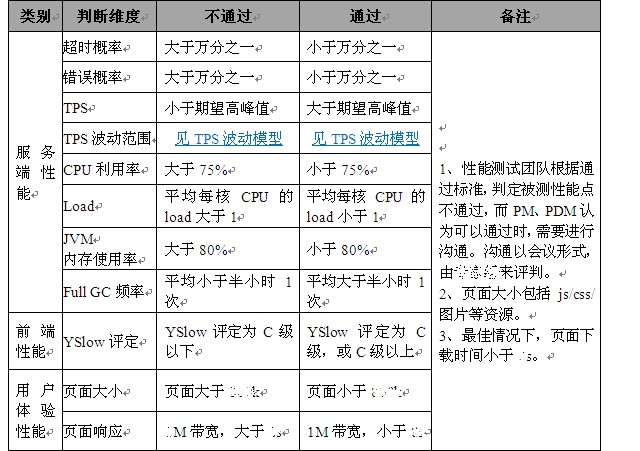
4、网站测试标准
==========================================================================
性能相关的系列文章:
LoadRunner利用ODBC编写MySql脚本
LoadRunner压力测试时监控服务器Linux的资源情况
压力测试衡量CPU的三个指标:CPU Utilization、Load Average和Context Switch Rate
高性能服务器架构(High-Performance Server Architecture)
网站性能测试PV到TPS的转换以及TPS的波动
用GTmetrix来优化你的网页(集成了YSlow、FireBug的功能)
Q&A
因为CSDN评论不知道为什么没法用了,所以贴在这里吧
Q:yxt168118 能否请作者将TPS的T,在测试脚本中,怎么定义说明一下?我是将某个关键操作定义为一个事务(T),这样测试出来的TPS很难达到10。
A:回复 yxt168118:定义T transaction 事务,是根据测试目的来决定的,如果是性能测试,T定义为一次请求,如果是可用性测试,T定义为整个页面的加载,主要看响应时间用户是否能接受。TPS高低和操作的复杂程度、以及后台扩展、以及T的定义是相关的。一般,单次的请求,单台机器,百数量级上是正常的。另外,在一次请求中,不要每次都去初始化一些比如用户等数据,如果有很多的数据库操作,TPS也会低一些,如果达不到10,还需要优化,比如看看数据库方面是否有优化的空间,比如索引。

















 2304
2304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









