






声明
关于訪问控制,人民已经讨论了非常多的方案。可是千万不要认为某种方案是放之四海而皆准的,没有这种东西!RBAC根本不适宏内核协议栈的操作系统(UNIX,Linux,and so on...我可能在之前的文章把它们弄反了,...)。可是这并非每个人民中的一员都知道,包括我自己!
总之,数据包在内核协议栈的处理过程中一定要符合“快,爽”的风格,不能导致兴许的数据包排队。由于不同的数据包可能属于不同的“业务逻辑”。你不能假设后面数据包所代表的业务逻辑会容忍前面数据包耽搁太多的时间,每人签署不论什么协议。对于网络设备而言,每个数据包都是平等的,假设高级一点的设备,每个数据流都是平等的,记住,设备是为转发数据而生。数据的目的地并非此设备!
全部的中间设备都TMD是浮云,一个所谓的WEB加速server假设不是利用了cache,那它就是骗局!
有什么能和线速转发更快的呢?没有!
CAO TMD的没有!
仅仅要Client和Server中间有一台设备。那它就TMD增加了延迟。别指望它能降低延迟,除非上帝便秘!
因此,我们在设计中间设备的时候。目标绝对不是神话般的降低延迟。而是“在你能控制的范围内尽可能的快”,所以,应用程序的那种处理方式就不合适了。别指望用什么库能够提高效率。记住,终于的控制权永远在运营商手中。永远在那些不懂编程的网管手中,随便一个人剪断网线,再怎么TCP也不能保证你能优雅的发送FIN。谁能控制网络才干决定一切,网络的效率永远比端到端的程序的效率更重要。
本文的目的在于。你能通过一种方式。尽可能保证本地的处理。不考虑别的。
在周六的一天的大雨中。激动,悸动!我不屑于网管嘴里的种种术语,也不怕编程,对于网管和程序猿,或许奥托.冯.俾斯麦仅仅能说,哀其不幸,怒其不争!
我尽管不懂OpenSSL,可是我是程序猿!
之后
前面的一篇文章《 Linux路由表的抽象扩展应用于nf_conntrack》中指出了能够用Linux的IP路由机制来实现訪问控制列表,即Linux的ACL,在那篇文章中,仅仅是说明了实现的可行性,然而终于。我却使用Linux的IP路由机制为随意的nf_conntrack保存了一个info字符串而已。本文来详细描写叙述一下怎样真的实现訪问控制。不是有iptables了吗
为何还要实现一套新的机制?由于:1.iptables基于Netfilter实现,因此仅仅能实现串行过滤,即一条一条的匹配。
2.匹配速度依赖于iptables规则的配置顺序,无法在内核实现统一的优化处理。
3.我不喜欢iptables,它在多核时代已经过时了,尽管能够基于Netfilter开发一个并行版本号,可是太难。
因此,为了解决上面的问题,我决定实现一套另外的不依赖Netfilter的訪问控制机制。
非常显然,我的目标之中的一个就是在匹配的过程中,多个核心能够被调度起来。
实现原理
实现一套针对IP数据报的訪问控制机制并非简单的事情,然而最主要的框架却是非常easy。那就是基于一个数据包的源IP地址和目标IP地址来决定这个数据包能够做什么。当然。除了IP地址之外,IP数据报文中的随意一个字段都能够參与匹配。甚至TCP/UDP协议头的字段也能够參与匹配,是的,可是本文不涉及那种复杂的情况,那些都非常easy从本文的思想中扩展出来,因此本文仅仅将IP地址作为匹配要素。如《 Linux路由表的抽象扩展应用于nf_conntrack》所述。一个Action能够保存在一个路由项其中。可是假设引入另外一个匹配元素目标IP的时候,这个Action将不能再存在于路由项其中了。它将作为源IP地址关联的路由项和目标IP地址关联的路由项之间的媒介,指示“该源路由项包括的全部IP地址能够对该目标路由项包括的全部IP地址实施Action”。
Action能够是通过。拒绝。地址转换等全部可能的动作。假设不存在一个Action在两个路由项之间关联,则运行默认Action。
可想而知,一个Action必须身兼两职,一方面它增加源路由项的Action链表,另一方面它增加目标路由项的Action链表中以关联二者。借用RBAC权限模型的术语,我能够把一个数据包的源IP地址看成是角色。而其訪问的目标IP地址则能够被看作是资源。这里仅仅是借用一下术语,真正的RBAC要比我这个复杂得多。一会儿我会说。我这个模型着眼在内核实现ACL的方式以及算法,而不是ACL模型本身。
数据结构要比图示更直接。由于每个Action都会同一时候被链接到两个链表,因此一个Action命名为Xnode就可以:
struct nf_action_node {
//struct list_head list; // 和算法相关,见注解1
struct hlist_node nf_dst;
struct hlist_node nf_src;
struct nf_fib_node *dst_node; //反向指针,算法优化。见查找算法小节
struct nf_fib_node *src_node; //反向指针,算法优化,见查找算法小节
int extra;
//int extra_len;
//char extra[0];
};另外。src/dst_node两个字段则是为了方便从nf_action_node找到它链接的两个路由项,尽管增加了两个node之间的耦合。可是却提高了效率,我们不是在OOD,而是在内核编程。
我们已经知道,一个nf_action_node同一时候链接到两个hlist中。这两个hlist分为归两个路由项全部。接下来就要定义路由项了:
struct nf_fib_node {
struct hlist_node nf_fn_hash;
struct hlist_head *act_list;
__be32 fn_key;
int len;
unsigned int hash_value;
struct nf_action_node *def;
};在action的插入算法中。我将dst路由表的nf_fib_node以及和它通过action相应的src路由表的nf_fib_node互称为peer。nf_action_node插入src路由项的hlist的时候,它使用其peer的hash_value,反之,插入dst路由项的时候,它也使用其peer的hash_value。这样在从src路由项或者dst路由项的随意一个遍历其act_list的时候,就不用全部遍历完整个list了,仅仅用遍历和其peer同样hash_value的冲突链表就可以。这就是使用hlist而不是list的原因。
注解1:
对于action的查找,另一个优化,那就是将全部的action通过list链接在一起,然后遍历这个list。必须其dst_node等于相应dst路由项,而src_node等于相应的src路由项。一般而言action没有几个。这个动作会比較快,当action链表长度超过一个阀值的时候,转换为採用路由项的hlist查找。
我为何凝视掉它呢?由于这仅仅是一篇blog,没人让我在规定时间必须完毕。临时没有实现。不留unused变量。凝视之。事实上相似的思想在Linux内核中有非常多样例,比方vm_area_struct就同一时候在不同的list中。须要遍历的时候走list_head,须要查找的时候走tree。
图示和查找
行文至此。还没有一个图示能表示出我的意思,没有图示是由于太难画了,即便如此。我也要一试。毕竟图解力也是一种能力: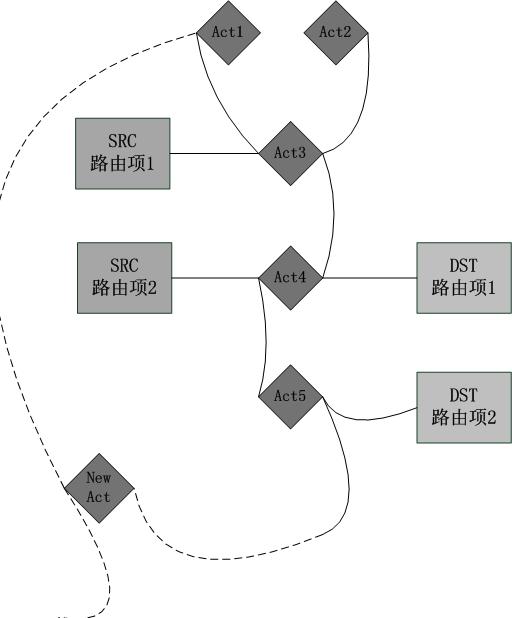 ############act
############act
注意,在以上图示中。从SRC路由项1范围的来源IP訪问DST路由项1范围的目标IP将会应用Act3,同理SRC2和DST2之间是Act5。SRC1和DST2之间使用默认Act。由于无法通过不论什么的Act节点连接二者。假设想设置它们之间的Act,那就新建一个。将其增加SRC1的链表和DST2的链表。
在理解了原理和基本数据结构后,我来解释一下算法,非常easy。分为3步:
1.使用数据包的源IP地址在源路由表中匹配到一个路由项,记为路由项1。
2.使用数据包的目标IP地址在目标路由表中匹配到一个路由项,记为路由项2。
3.在路由项1中的链表中获取一个Act。满足该Act也在路由项2的链表中,或者相反...
上述的前面两点我就不多解释了,能够去看Linux内核代码。RTFSC,关键在第3点。它能够有非常多的优化,最最直接的方式就是使用list_head这种通用双向链表,可是我使用了比它略微复杂那么一点点的数据结构,那就是hlist_head,由于没有太多的富余时间,我就没有使用更复杂的数据结构来炫技巧。使用hash链表能够提高效率,其关键点在它能够把一整条链表拆成若干条短得多的小链表,每条小链表上的节点都携带一个同样的hash值。是为hash冲突链表。效率的关键就在于这个hash值的取值。
我採用的办法是,将一个路由项在内存中的地址作为hash,按hash桶的大小取余,记为K,然后将关联它和其peer的Act增加到其peer的hash值为K的冲突链表中。反过来也一样,这样我就不须要遍历路由项的整条链表了。仅仅须要遍历hash值为K那条小链表就可以,极端情况下。该小链表中的节点仅仅有一个,就是你要找的,你须要做的仅仅是计算一个hash值而已,这个非常easy,两个路由项都在你手中,取地址会吧。
之所以我对这个算法有信心。是由于这里面有一个小技巧,那就是路由项在内存中的布局是能够安排的。特别是是使用Linux的kmem_cache机制。它能够将路由项按顺序排列在紧凑的内存空间。该空间也不是非常大,依照存储1000条路由项来讲,须要连续内存大小为1000*sizeof(struct nf_fib_node)。这种话,hash桶的大小就能够计算出来了。非常easy。就是1000!以空间换时间如今已经非经常见了,我们早就開始把地球变小,距离缩短,可是时间依旧像古罗马时期一样无情流逝。
我在nf_action_node结构体中保留了两个反向的指针指向了相关的路由项,引入这个耦合也是为了提高效率。我能够在遍历冲突链表的时候。直接从Act结构体取出peer路由项。假设不用这两个指针,也有办法,那就是採用“着色”的方式。两个线程同一时候从两个路由项来遍历hash冲突链表。每遍历一个节点,就为该节点着色,实际上就是标记一下peer的信息。比方把peer的地址标记进去。然后peer遍历到此的时候,先看看有没有标记,有的话看看是否就是自己,假设是,那就是它了!
伪代码例如以下:
list_for_each
if 有标记
if 找的就是自己
找到了
else
下一个
end
else
标记peer的信息
end
end_for代码
是时候展示一下代码了,为了调试方便,我并没有直接编写内核模块,而是把它们移植到了用户态。须要移植的部分不多,也非常easy,就是一个hlist相关的东西以及路由表结构体。首先是头文件route_extra.h:
#ifndef ROUTE_EXTRA_H
#define ROUTE_EXTRA_H
#include <stdio.h>
#include <stdlib.h>
#include <arpa/inet.h>
#define __be32 u_int32_t
typedef unsigned int u32;
struct hlist_node {
struct hlist_node *next, **pprev;
};
struct hlist_head {
struct hlist_node *first;
};
struct nf_fn_zone {
struct nf_fn_zone *fz_next;
struct hlist_head *fz_hash;
int fz_divisor;
u32 fz_hashmask;
#define FZ_HASHMASK(fz) ((fz)->fz_hashmask)
int fz_order;
__be32 fz_mask;
#define FZ_MASK(fz) ((fz)->fz_mask)
};
struct nf_fn_hash {
struct nf_fn_zone *nf_fn_zones[33];
struct nf_fn_zone *nf_fn_zone_list;
};
struct nf_fib_node;
struct nf_action_node {
struct list_head list;
struct hlist_node nf_dst;
struct hlist_node nf_src;
struct nf_fib_node *dst_node;
struct nf_fib_node *src_node;
int extra;
//int extra_len;
//char extra[0];
};
struct nf_fib_node {
struct hlist_node nf_fn_hash;
struct hlist_head *act_list;
__be32 fn_key;
int len;
unsigned int hash_value;
struct nf_action_node *def;
};
static __inline__ __be32 inet_make_mask(int logmask)
{
if (logmask)
return htonl(~((1<<(32-logmask))-1));
return 0;
}
static inline unsigned long ffz(unsigned long word)
{
asm("bsf %1,%0"
: "=r" (word)
: "r" (~word));
return word;
}
static __inline__ int inet_mask_len(__be32 mask)
{
uint32_t hmask = ntohl(mask);
if (!hmask)
return 0;
return 32 - ffz(~hmask);
}
extern struct nf_fn_hash *acl_route_table;
// 临时没有导出不论什么接口
#endif#include "route_extra.h"
#define offsetof(TYPE,MEMBER) ((unsigned long) &((TYPE *)0)->MEMBER)
#define hlist_for_each_entry_safe(tpos, pos, n, head, member) \
for (pos = (head)->first; \
pos && ({ n = pos->next; 1; }) && \
({ tpos = hlist_entry(pos, typeof(*tpos), member); 1;}); \
pos = n)
#define hlist_for_each_entry(tpos, pos, head, member) \
for (pos = (head)->first; \
pos && ({ tpos = hlist_entry(pos, typeof(*tpos), member); 1;}); \
pos = pos->next)
#define hlist_entry(ptr, type, member) container_of(ptr,type,member)
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member) * __mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); })
typedef unsigned int u_int32_t;
static inline void INIT_HLIST_NODE(struct hlist_node *h)
{
h->next = NULL;
h->pprev = NULL;
}
static inline void __hlist_del(struct hlist_node *n)
{
struct hlist_node *next = n->next;
struct hlist_node **pprev = n->pprev;
*pprev = next;
if (next) {
next->pprev = pprev;
}
}
static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h)
{
struct hlist_node *first = h->first;
n->next = first;
if (first)
first->pprev = &n->next;
h->first = n;
n->pprev = &h->first;
}
static inline u_int32_t nf_fz_key(u_int32_t dst, struct nf_fn_zone *fz)
{
return dst & FZ_MASK(fz);
}
static inline u32 nf_fn_hash(u_int32_t key, struct nf_fn_zone *fz)
{
u32 h = key>>(32 - fz->fz_order);
h ^= (h>>20);
h ^= (h>>10);
h ^= (h>>5);
h &= FZ_HASHMASK(fz);
return h;
}
static struct hlist_head *fz_hash_alloc(int divisor)
{
unsigned long size = divisor * sizeof(struct hlist_head);
return calloc(1, size);
}
static struct nf_fn_zone * fn_new_zone(struct nf_fn_hash *table, int z)
{
int i;
struct nf_fn_zone *fz = calloc(1, sizeof(struct nf_fn_zone));
if (!fz)
return NULL;
if (z) {
fz->fz_divisor = 16;
} else {
fz->fz_divisor = 1;
}
fz->fz_hashmask = (fz->fz_divisor - 1);
fz->fz_hash = fz_hash_alloc(fz->fz_divisor);
if (!fz->fz_hash) {
free(fz);
return NULL;
}
fz->fz_order = z;
fz->fz_mask = inet_make_mask(z);
for (i=z+1; i<=32; i++)
if (table->nf_fn_zones[i])
break;
if (i>32) {
fz->fz_next = table->nf_fn_zone_list;
table->nf_fn_zone_list = fz;
} else {
fz->fz_next = table->nf_fn_zones[i]->fz_next;
table->nf_fn_zones[i]->fz_next = fz;
}
table->nf_fn_zones[z] = fz;
return fz;
}
// 路由表操作接口:1.查找;2.删除。參数过于多,相似Win32 API。风格不好,但使用方便 int nf_route_table_opt(struct nf_fn_hash *table, const u_int32_t dst, const u_int32_t mask, int del_option, struct nf_fib_node **resf) { int rv = 1; struct nf_fn_zone *fz; struct nf_fib_node *del_node = NULL; if (NULL == table) { printf("INFO:route_table uninitialed!"); return 1; } for (fz = table->nf_fn_zone_list; fz; fz = fz->fz_next) { struct hlist_head *head; struct hlist_node *node; struct nf_fib_node *f; u_int32_t k = nf_fz_key(dst, fz); head = &fz->fz_hash[nf_fn_hash(k, fz)]; hlist_for_each_entry(f, node, head, nf_fn_hash) { if (f->fn_key == k){ if ( 1 == del_option && mask == FZ_MASK(fz)){ del_node = f; } else if (0 == del_option){ *resf = f; } rv=0; goto out; } } } rv = 1; out: if (del_node) { __hlist_del(&del_node->nf_fn_hash); free(del_node); } return rv; } static inline void fib_insert_node(struct nf_fn_zone *fz, struct nf_fib_node *f) { struct hlist_head *head = &fz->fz_hash[nf_fn_hash(f->fn_key, fz)]; hlist_add_head(&f->nf_fn_hash, head); } int nf_route_table_search(struct nf_fn_hash *table, u_int32_t dst, struct nf_fib_node **resf) { return nf_route_table_opt(table, dst, 32, 0, resf); } int nf_route_table_delete(struct nf_fn_hash *table, u_int32_t network, u_int32_t mask) { return nf_route_table_opt(table, network, mask, 1, NULL); } int nf_route_table_add(struct nf_fn_hash *table, u_int32_t network, u_int32_t netmask, struct nf_fib_node **node) { struct nf_fib_node *new_f; struct nf_fn_zone *fz; new_f = calloc(1, sizeof(struct nf_fib_node)); new_f->len = inet_mask_len(netmask); new_f->act_list = fz_hash_alloc(16); new_f->fn_key = network; if (new_f->len > 32) { return -1; } INIT_HLIST_NODE(&new_f->nf_fn_hash); if ( NULL == table){ return -13; } fz = table->nf_fn_zones[new_f->len]; if (!fz && !(fz = fn_new_zone(table,new_f->len))) { return -1; } fib_insert_node(fz, new_f); // danger *node = new_f; return 0; } void nf_route_table_clear(struct nf_fn_hash *table) { struct nf_fn_zone *fz,*old; if (NULL == table) { printf("INFO:route_table was NULL,no need to clear!"); return; } for (fz = table->nf_fn_zone_list; fz; ) { if (fz != NULL){ free(fz->fz_hash); fz->fz_hash=NULL; old = fz; fz = fz->fz_next; free(old); old=NULL; } } free(table); return; } int nf_route_policy_search(struct nf_fn_hash *src_table, struct nf_fn_hash *dst_table, uint32_t src_addr, uint32_t dst_addr) { int rv = 0; int flag = 0; struct nf_fib_node *src_node; struct nf_fib_node *dst_node; int src_hash = 0; int dst_hash = 0; struct nf_action_node *action; struct hlist_head *head; struct hlist_node *node; rv = nf_route_table_search(src_table, src_addr, &src_node); if (rv) { rv = -100; goto ret; } rv = nf_route_table_search(dst_table, dst_addr, &dst_node); if (rv) { rv = -200; goto ret; } // 注意,由于雨越下越小。我就没有实现着色 head = &src_node->act_list[dst_node->hash_value]; hlist_for_each_entry(action, node, head, nf_src) { if (action->dst_node == dst_node){ rv = action->extra; flag = 1; } } if (flag == 0) { rv = src_node->def->extra; } ret: return rv; } int nf_route_policy_add(struct nf_fn_hash *src_table, struct nf_fn_hash *dst_table, uint32_t src_network, uint32_t dst_network, uint32_t src_netmask, uint32_t dst_netmask, struct nf_action_node *action, struct nf_action_node *def) { int rv = 0; struct nf_fib_node *src_node; struct nf_fib_node *dst_node; struct hlist_head *src_head; struct hlist_head *dst_head; rv = nf_route_table_add(src_table, src_network, src_netmask, &src_node); if (rv) { rv = 1; goto ret; } src_node->def = def; // 注意hash值的计算 src_node->hash_value = ((unsigned int)src_node)%16; rv = nf_route_table_add(dst_table, dst_network, dst_netmask, &dst_node); if (rv) { rv = 1; goto ret; } dst_node->def = def; dst_node->hash_value = ((unsigned int)dst_node)%16; action->src_node = src_node; action->dst_node = dst_node; INIT_HLIST_NODE(&action->nf_src); INIT_HLIST_NODE(&action->nf_dst); src_head = &src_node->act_list[dst_node->hash_value]; hlist_add_head(&action->nf_src, src_head); dst_head = &src_node->act_list[src_node->hash_value]; hlist_add_head(&action->nf_dst, dst_head); ret: return rv; } int main(int argc, char **argv) { int rv = 0; struct nf_action_node *def, *act1, *act2; struct nf_fn_hash *src_table; struct nf_fn_hash *dst_table; struct nf_fib_node *src_node = NULL; struct nf_fib_node *dst_node = NULL; src_table = calloc(1, sizeof(struct nf_fn_hash)); dst_table = calloc(1, sizeof(struct nf_fn_hash)); /* 增加默认路由项 */ def = calloc(1, sizeof(struct nf_action_node)); def->extra = 10000; act1 = calloc(1, sizeof(struct nf_action_node)); act1->extra = 1; act2 = calloc(1, sizeof(struct nf_action_node)); act2->extra = 2; rv = nf_route_policy_add(src_table, dst_table, 0x00000000, 0x00000000, 0x00000000, 0x00000000, act1, def); rv = nf_route_policy_add(src_table, dst_table, 0x0000a8c0, 0x00001010, 0x0000ffff, 0x0000ffff, act1, def); rv = nf_route_policy_search(src_table, dst_table, 0x0102a9c0, 0x01021010); printf("%d\n", rv); return 0; }
以上的代码中对于extra的定义太随意,本来想进一步扩展呢?可是雨越来越小了,对于我来讲,不下暴雨的每一天都是煎熬。爱探险的朵拉,JI JI JI JI朵拉...捣蛋鬼别捣蛋。
并行运行的含义
而不是意义。并行运行是我这个设计的最大特色。在多核环境下,你要知道的是,尽管整个匹配过程分3步走,可是事实上仅仅有一步,两次路由查找是能够同一时候进行的,你会看到,以上的描写叙述或者代码差点儿都是反复性的,也就是同一个逻辑写两遍。全都是对称的,可是要知道,光这是不够的,很多其它的工作在于你怎样把这些对称的操作塞进两个运行绪而不引入得不偿失的开销,就像叔本华理解的那样。最大的开销就是同步开销。世界就是这样,生活也是这样,你怀着激动的心情引入了复杂。有时得到的却没有你付出的多。而正是这份激动让你继续前行。直到再也负担不了...鉴于此。我不得不说一下balance的艺术。
balance的思想和艺术
实际上,整个世界是balance构成的。中庸之道?好像也不是,否则世界就不会前行了。对于文明和文化,真正的balance在于崩塌和重建之间的balance,设计方面的balance设计与此不同,有用的技术和唯美赞赏艺术都是静态的。对于技术的美,在于跷跷板两边的重量在不断的变化,你必须改变支点保持balance,从早期的终端时代到如今的后终端时代,你会看到这种balance。对于像绘画,音乐这种艺术。balance恰恰在崩塌的恰到优点,反差在崩塌中体现,终于趋于一点。过程中释放的能量触动你的神经。
这让我想起摇滚中国乐势力演唱会时,何勇说,我就是最大的垃圾场。然后把鼻屎抹到了记者的摄像头上。














 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









