




LLM的知识仅限于它所接受到的训练数据。如果我们希望让它了解特定领域的专有知识,则可以使用下面的方式操作:
- 使用RAG
- 使用专有数据对LLM进行微调
- RAG与数据微调方式结合使用
什么是RAG
简单地说,RAG就是把数据发送给LLM之前从数据中查找相关信息片段并把它注入到提示符的方法。这样的话LLM获得相关信息,并可以使用这些信息进行回复。
那么最为重要的是我们要可以检索到信息,可以使用下面的一些方法:
- 全文(关键字)检索,这咱方法使用IF-IDF和BM25之类的技术,通过在文档数据库中匹配查询关键字(用户询问的内容)来检索文档。它会根据这些关键字在每个文档中的频率和相关性对结果进行排序。
- 向量搜索,有称为“语义搜索”。使用嵌入模型把长文本文档转换为数字向量。然后,根据查询向量和文档向量之间的余弦相似度或其他相似度,来查找和排序文档,从而获得更深层次的语义。
- 混合检索,结合多种搜索方法(如:全文 + 向量),通常这样子可以提高检索的效率。
RAG的两阶段处理
RAG的过程是分为两个阶段的:索引和检索
索引
索引阶段就是为了后一阶段检索而进行的对文档的预处理
在这个阶段会根据所使用的信息检索方法而有变化。对于向量检索,通常包含清理文档、用额外的数据和元数据丰富它们、把它们分割为更小的段/块,最后把它们存储到存储区(向量数据库)中。
索引阶段通常是脱机进行的,这意味着它不需要最终用户等待它的操作完成。这样的话我们就可以使用定时任务在固定时间进行重新索引知识库文档,负责进行索引的代码也可以是一个单独的代码也可以是一个单独的应用程序,专门只用来处理索引任务。
在有些情况下,最终用户可能希望上传他们自己的文档,便于LLM访问到它们。在这种情况下索引阶段应该是在线执行的,并且是主应用程序的一部分。
关于索引阶段官方示意图如下:
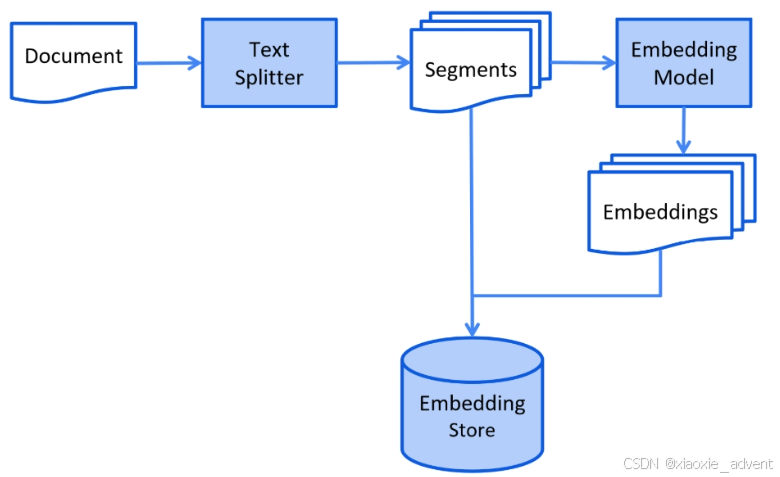
检索
检索阶段通常是在线进行的,它处于用户提交应该使用索引文档回答问题时。
在这个过程中会根据所使用的信息检索方法而变化。对于向量搜索,通常来说涉及到用户的查询并在嵌入存储中地相似性搜索。然后把这个片段(原始文档的片段)注入提示并发送给LLM。
关于检索的官方示意图如下:
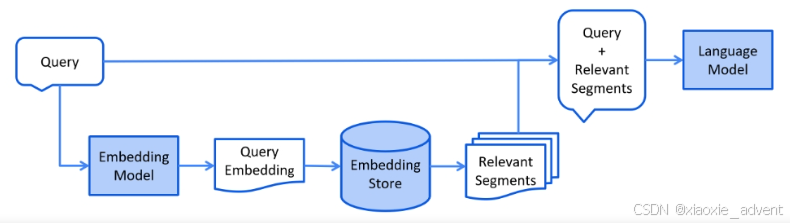
三种不同的RGA
- Easy RAG:使用RAG最简单的方法
- Native RAG:一个使用矢量搜索的RAG基本实现
- Advanced RAG:一个模块化的RAG框架,它允许额的步骤,如查询转换、多个源检索和重新排序
Easy RAG
LangChain4j有一个简单的RAG实现,使用这个不需要额外去了解嵌入、矢量存储、嵌入模型以及了解如何解析和分割文档等等,我们只需要指向指定的文档,LangChain4j就会去处理。
注意:这种简单的RAG在质量上肯定是会低于定制RAG的
使用步骤
第一步:我们要使用Easy RAG功能,必须要添加相对应的依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
</dependency>第二步:加载指定文档
List<Document> documents = FileSystemDocumentLoader.loadDocuments("E://myDocument");第二步会加载指定目录下的所有文档,它的实现依赖于Apache Tika库支持,Tika库支持多种类型文档的解析,由于这里没有指定具体的DocumentParser,那么FileSystemDocumentLoader会加载一个ApacheTikaDocumentParser,这是由langchain4j-easy-rag依赖项通过SPI提供的。
我们了可以自定义需要解析哪些个文档,可以给定一个匹配规则,然后解析目录下满足规则的文档
PathMatcher pathMatcher = FileSystems.getDefault().getPathMatcher("glob:**" + ".txt");
FileSystemDocumentLoader.loadDocuments("E://myDocument", pathMatcher);上面的话给定了一个规则,则只会解.txt的文档
第三步:我们需要一个专门的嵌入存储(矢量数据库)对文档进行预处理和存储
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor.ingest(documents, embeddingStore);EmbeddingStoreIngestor通过SPI从langchain4j-easy-rag依赖项加载一个DocumentSplitter。每个文档被分割为更小的部分,每个部分由不超过300个令牌组成,并有30个令牌的重叠。
EmbeddingStoreIngestor通过SPI从langchain4j-easy-rag依赖项加载一个EmbeddingModel,使用这个EmbeddingModel把每个TextSegment转为嵌入
最终所有的TextSegment-Embedding对都会存储到EmbeddingStore
第四步:定义和创建AiService
具体示例
1、pom依赖项添加
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
</dependency>2、创建一个Document的工具类用来封装加载文档的方法
public class DocumentUtils {
/**
* 根据指定的目录加载目录下所有文档
* @param dir 目录
* @return 文档列表
*/
public static List<Document> loadDocuments(String dir) {
return FileSystemDocumentLoader.loadDocuments(dir);
}
/**
* 根据指定的目录加载目录下指定类型的文件
* @param dir 指定要加载的目录
* @param filter 文件类型
* @return 文档列表
*/
public static List<Document> loadDocuments(String dir, String filter) {
PathMatcher pathMatcher = FileSystems.getDefault().getPathMatcher("glob:**" + filter);
return FileSystemDocumentLoader.loadDocuments(dir, pathMatcher);
}
/**
* 根据指定的目录加载目录下所有文档
* @param dir 目录
* @param containsSubDir 是否包含子目录
* @return 文档列表
*/
public static List<Document> loadDocuments(String dir,Boolean containsSubDir) {
if (containsSubDir) {
return FileSystemDocumentLoader.loadDocumentsRecursively(dir);
}
return FileSystemDocumentLoader.loadDocuments(dir);
}
/**
* 根据指定的目录加载目录下指定类型的文件
* @param dir 指定要加载的目录
* @param filter 文件类型
* @param containsSubDir 是否包含子目录
* @return 文档列表
*/
public static List<Document> loadDocuments(String dir,String filter,Boolean containsSubDir) {
// 多级目录时写**
PathMatcher pathMatcher = FileSystems.getDefault().getPathMatcher("glob:**" + filter);
if (containsSubDir) {
return FileSystemDocumentLoader.loadDocumentsRecursively(dir, pathMatcher);
}
return FileSystemDocumentLoader.loadDocuments(dir, pathMatcher);
}
}3、创建AiService接口
public interface Assistant {
Flux<String> chat(@MemoryId String memoryId, @UserMessage String message);
}4、创建AiService实例Bean
@Configuration
public class AssistantConfig {
@Resource
private StreamingChatLanguageModel streamingChatLanguageModel;
@Bean
public Assistant assistant() {
InMemoryEmbeddingStore<TextSegment> embeddingStore = getInMemoryEmbeddingStore("E:\\project\\IdeaProjects\\AI\\LangChain4j\\rag\\src\\main\\resources\\documents", ".txt");
return AiServices.builder(Assistant.class)
.chatMemoryProvider(memoryId -> MessageWindowChatMemory.withMaxMessages(10))
.contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore))
.streamingChatLanguageModel(streamingChatLanguageModel).build();
}
private InMemoryEmbeddingStore<TextSegment> getInMemoryEmbeddingStore(String path, String filter) {
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
List<Document> documents = DocumentUtils 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2780
2780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









