







N-gram模型
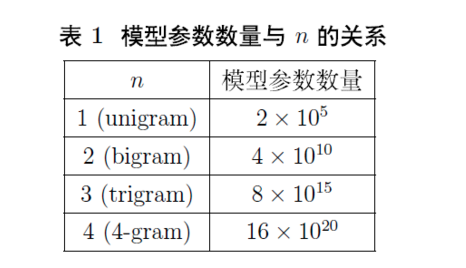
N-gram模型假设一个词出现的概率只与它前面固定数目的词相关。一般而言,n的选取需要同时考虑计算复杂度和模型效果两个因素。
神经网络语言模型
(1) 神经概率语言模型中假定了”相似的”词对应的词向量也是相似的。
(2) 概率函数关于词向量是光滑的,即词向量中的一个小变化对概率的影响也只是一个小变化。
模型
1.基于词向量的模型自带平滑化功能。
2.词向量是Distributed Representation(向量中有大量非零向量,词的信息分布到各个分量中),通过训练将某种语言中的每一个词映射为一个固定长度的向量,所有的向量构成一个词向量空间,每个向量可视为该空间中的一个点,根据词之间”距离”判断它们的相似性。
LSA和LDA都可以用来估计词向量。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









