









一、图的定义和基本术语
图的定义:G=(V,E),图是包含顶点和边的集合
-
V:顶点(数据元素)的有穷非空集合
-
E:边的有穷集合
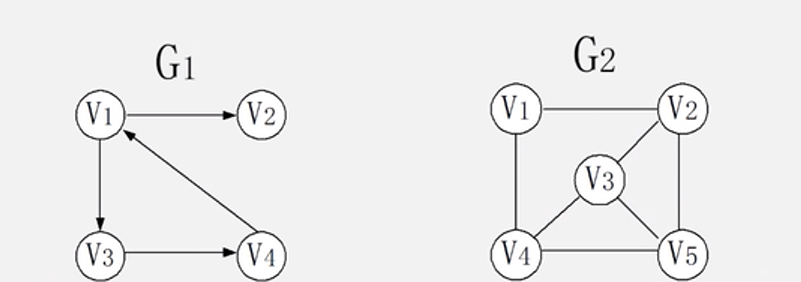
类似于下图,G1由 V1、V2、V3、V4 四个顶点,四条边组成,G2 由五个顶点,七条边组成。
其中G1中的边带有方向称为有向图, 不带方向的称为无向图
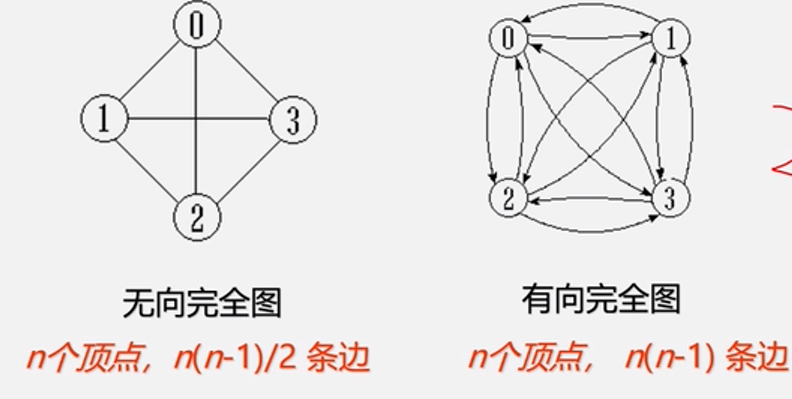
完全图:任意俩个点都有一条边相连
稀疏图: 有很少的边或者弧(有向图的边)比较少的图(n< nlogn)
稠密图: 有较多的边或者弧
网: 边/弧 带权的图
邻接: 边/弧相连的俩个顶点之间的关系,<> 表示有向,vi -> vj

顶点的度: 与该顶点相关联的边的数目,记为 TD(v),在有向图中,顶点的度等于该顶点的入度和出度之和。
-
顶点 v 的入度是以 v 为终点的有向边的条数记作 ID(v)
-
顶点 v 的出度是以 v 为始点的有向边的条数 记作 OD(v)

::: tip
当有向图中仅1个顶点的入度为0,其余顶点的入度均为1,此时是何形状?
答:是一颗树,是一颗有向树
:::
路径: 接续的边构成的顶点序列
路径长度: 路径上边或弧的数目/权值之和。
假设从0到2,路径有: 0 - 3 - 2, 0 - 1 - 2,0 - 2… ,路径长度分别为:2、2、1…
回路(环): 第一个顶点和最后一个顶点相同的路径
简单路径: 除路径起点和终点可以相同外,其余顶点均不相同的路径
简单回路(简单环): 除路径起点和终点相同外,其余顶点均不相同的路径。
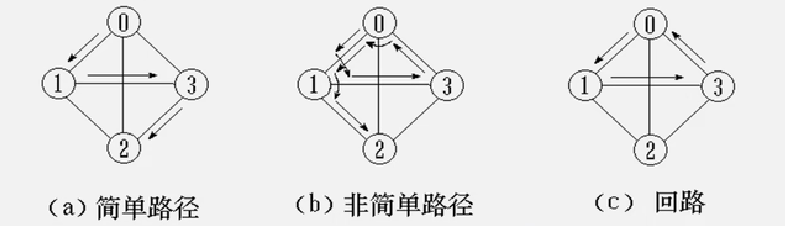
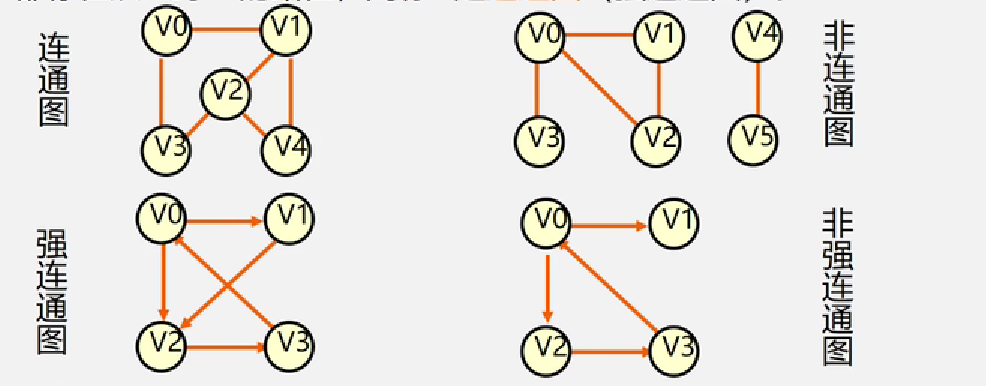
连通图 (强连通图)
在无 (有) 向图G=(V,{E})中,若对任何两个顶点 v、u都存在从v 到 u 的路径,则称G是连通图 (强连通图)
权与网
图中边或弧所具有的相关数称为权。表明从一个顶点到另一个顶点的距离或耗费。带权的图称为网
子图:设有两个图G= (V,{E})、G1= (V1,{E1}),若V1 ∈ V,E1 ∈ E,则称 G1是G的子图
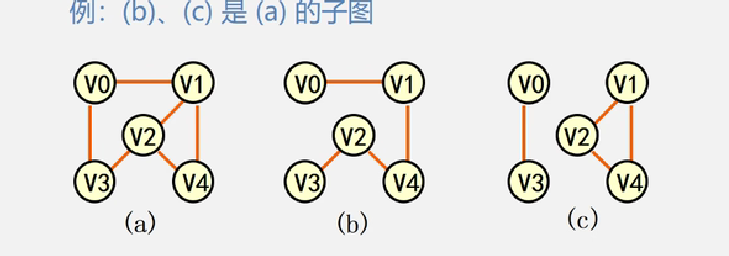
极小连通子图:该子图是G的连通子图,在该子图中删除任何一条边,子图不在连通
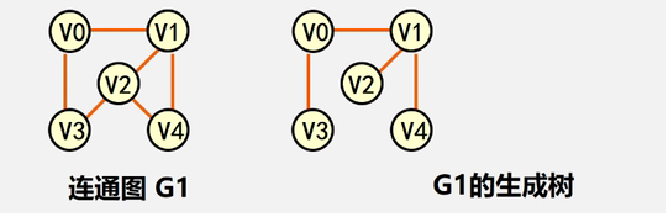
生成树:包含无向图G所有顶点的极小连通子图
生成 森林:对于非连通图,由各个连通分量的生成树的集合
二、图的存储结构
图的逻辑结构:多对多
图没有顺序存储结构但可以借助**二维数组(邻接矩阵)**来表示元素间的关系。
链式存储结构:
普通的链式存储无法实现图,因为不知道图中某个顶点到底有多少个前驱和后继。
因此可以使用多重表的方式实现。
(1)数组(邻接矩阵表示法)
建立一个顶点表 (记录各个顶点信息) 和一个邻接矩阵 (表示各个顶点之间关系)
- 邻接矩阵的数据结构为
二维数组 - 对于无向图来说,如果俩个顶点之间
有弧记为1,否则记为0 - 对于有向图来说,如果某个顶点有
以自身为起点到其他顶点的弧(出度)那么记为1,否则为0。 - 如果某个顶点有
以自身为起点到其他顶点的弧那么记为对应的权值,否则为∞(无穷大)
【举例说明-无向图的邻接矩阵】
v1 与 v2、v4 顶点有边,在二维数组中对应为 arcs[v1][v2]=1, arcs[v1][v4]=1, 其余为 0。
v2与v1、v3、v5顶点有边,在二维数组中对应为 arcs[v2][v1]=1, arcs[v2][v3]=1,arcs[v2][v5]=1其余为 0
以此类推…

- 分析1: 通过图中我们可以发现,对角线上的值全为0,这是因为顶点与自身之间没有边
- 分析2: 求第 i 个顶点的度,就是第 i 行值的和
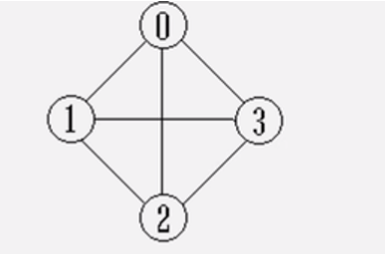
- 分析3:如果是完全图,也就是说每俩个顶点都有一条边相连,那么除了对角线的值为0,其余都为 1
【举例说明-有向图的邻接矩阵】
例如: 以 v1为起点的有 v2,v3,在二维数组中 arcs[v1][v2]=1、arcs[v1][v3]=1,其余为0,以此类推…
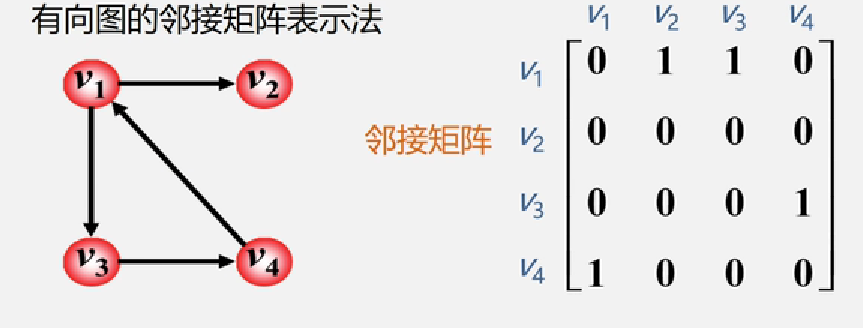
注: 在有向图的邻接矩阵中
第i行含义:以结点vi为尾的弧(即出度边)
第i列含义: 以结点vi为头的弧(即入度边)
分析1: 有向图的邻接矩阵可能是不对称的。
分析2 :
顶点的出度(以该顶点为起点) = 第i行元素值之和
顶点的入度(以该顶点为终点)=第 i 列元素值之和
顶点的度 = 第i行元素值之和 + 第 i 列元素值之和
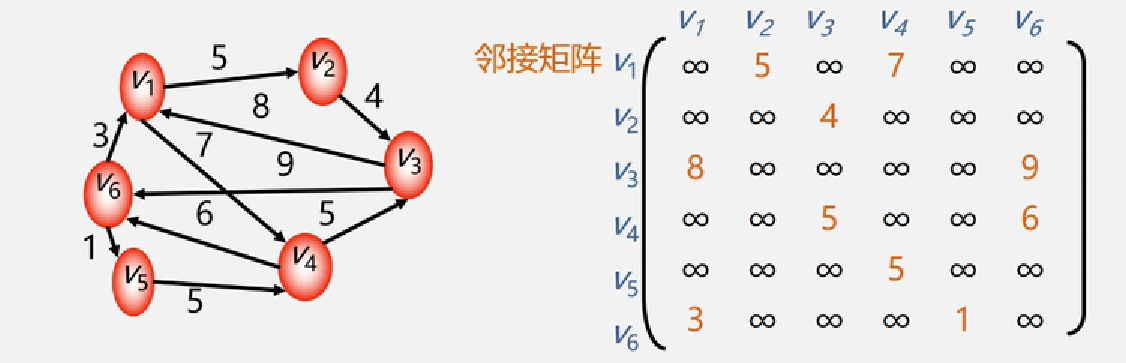
【举例说明-网的邻接矩阵】
例如: 以 v1为起点的有 v4,v2,在二维数组中 arcs[v1][v2]=5、arcs[v1][v3]=7,其余为 ∞,以此类推…
(2)数组(邻接矩阵)的实现
以无向网为例。无向网指:没有方向并且带有权值的图
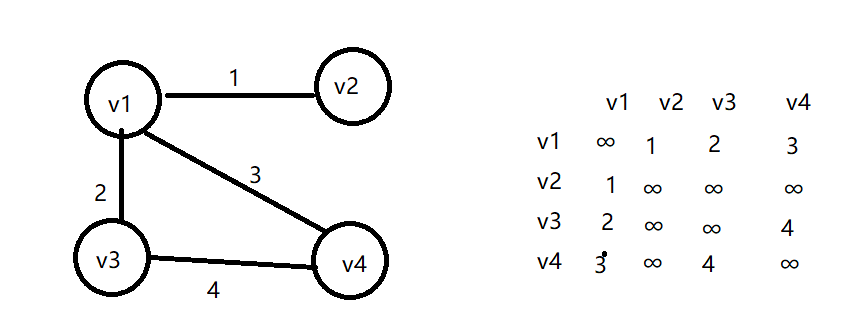
1、定义存储结构并且进行初始化。初始化时传入一个顶点数组,计算该数组的长度length,邻接矩阵为 length*length的矩阵。并将矩阵全都初始化为最大值
package ChapterSix.graph;
import java.util.Arrays;
/**
*
* Author: YZG
* Date: 2023/8/27 14:24
* Description: 实现 无向图的邻接矩阵表示法
*/
public class AMGraph {
Object[] vexs; // 顶点数组
Object[][] arcs; // 邻接矩阵
int vexNum, arcNum; // 记录顶点、边的个数
/**
* @description 初始化
* @date 2023/8/27 14:45
* @param vexs 表示顶点数组
* @return
*/
public AMGraph(Object[] vexs) {
this.vexs = vexs;
// 顶点个数
int length = vexs.length;
this.vexNum = length;
this.arcs = new Object[length][length];
// 初始化邻接矩阵的值皆为∞ ,在Java就用integer的最大值表示
for (int i = 0; i < length; i++) {
for (int j = 0; j < length; j++) {
arcs[i][j] = Integer.MAX_VALUE;
}
}
}
}
2、根据传入的顶点、权值构建无向网。
/**
* @description 创建无向网
* @date 2023/8/27 14:50
* @param v1 顶点1
* @param v2 顶点2
* @param weight 顶点1和顶点2之间的权值
* @return void
*/
public void createUDN(Object v1, Object v2, int weight) {
// 找到v1、v2的下标
int i = findIndex(vexs, v1);
int j = findIndex(vexs, v2);
// 防止输入错误
if (i == -1 || j == -1) throw new RuntimeException("您输入顶点有误");
// 赋值权值,因为是无向图,所以反向的权值也要赋
arcs[i][j] = weight;
arcs[j][i] = weight;
// 边的个数+1
this.arcNum++;
}
3、由于传入的是顶点的名称,还需要一个方法用来找到顶点的下标。
/**
* @description 根据顶点名称找到对应的下标
* @date 2023/8/27 14:51
* @param vexs 顶点数组
* @param v 顶点名称
* @return int
*/
public int findIndex(Object[] vexs, Object v) {
for (int i = 0; i < vexs.length; i++) {
if (vexs[i]==v) return i;
}
return -1;
}
测试
public static void main(String[] args) {
AMGraph amGraph = new AMGraph(new Object[]{"v1", "v2", "v3","v4"});
// 增加边
amGraph.createUDN("v1","v2",1);
amGraph.createUDN("v1","v3",2);
amGraph.createUDN("v1","v4",3);
amGraph.createUDN("v3","v4",4);
System.out.println(Arrays.deepToString(amGraph.arcs));
System.out.println("边的个数:" + amGraph.arcNum);
}
总结
无向图、有向网 都一样。只不过邻接矩阵存储的数据不一样
无向图:没有权值了,因此在arcs初始化时皆为0,在赋值的时候赋为1
// 无向图-初始化
arcs[i][j] = 0;
// 无向图-赋值
arcs[i][j] = arcs[j][i] = 1;
有向网:只需要赋一次权值即可,无需设置反向
arcs[i][j] = weight;
邻接矩阵的优点:
- 直观、简单、好理解
- 方便检查任意一对顶点间是否存在边
- 方便找任一顶点的所有“接点”(有边直接相连的顶点)
- 方便计算任一顶点的“度”(从该点发出的边数为“出度”,指向该点的边数为“入度”)
- 无向图: 对应行(或列)非0元素的个数
- 有向图: 对应行非0元素的个数是"出度", 对应列非0元素的个数是"入度"
缺点
- 不方便增加和删除顶点
- 浪费空间,例如存储稀疏图(点很多但是边很少)有大量无效元素
- 浪费时间,统计稀疏图中一共有多少条边
邻接矩阵的方式和边的个数没有关系,只和顶点的个数有关,存储空间:O(n2)
(3)邻接表(链式表示法)
邻接表的表示方法仍然需要一个顶点表,但与邻接矩阵的顶点表不同的是,这个顶点表中元素的类型是一个结点。
data用来存放顶点的信息,firstarc 用来存储第一个边结点的地址,也就是说与data相连的顶点。

邻接表中仍然使用一个结点来表示俩个顶点的关系
adjvex 用来表示当前顶点的地址,nextarc表示下一个边顶点的地址,因此对于某一个顶点来说有几个相连的顶点就有几个结点。

如果存储网结果,就在多加一个链域用于存储权值

【案例】
对于v1顶点来说,与它相邻的顶点有 v4,v2,在顶点表中对应的下标为 3、1
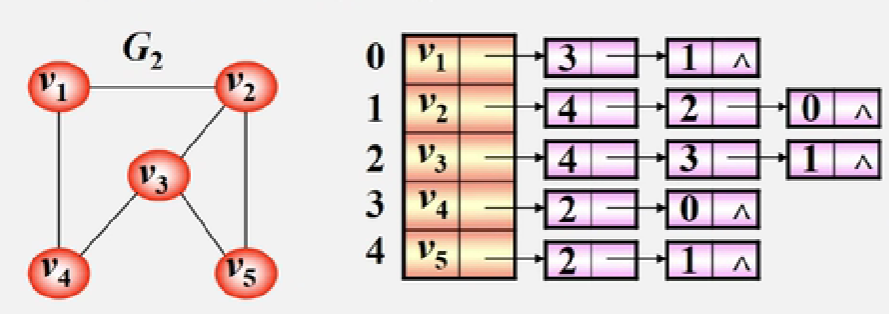
特点:
- 邻接表不唯一,对于相连的顶点可以更改顺序
- 若无向图中有 n 个顶点、e条边,则其邻接表需 n 个头结点和2e表结点。适宜存储稀疏图
- 无向图中顶点 vi 的度为第i个单链表中的结点数
存储空间为:O(n+2e)
【有向图-邻接表演示】
在有向图中只保存以该顶点为起点的弧(出边)的顶点
例如:以v1为起点的弧的顶点为 v2、v3,对应下标 1,2
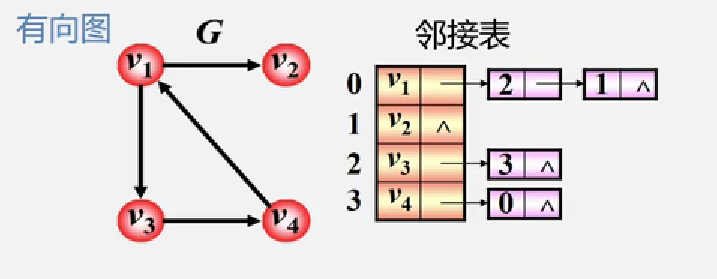
特点
- 顶点为Vi 的出度为第 i 个单链表中的结点个数
- 顶点 Vi 的入度为整个单链表中邻接点域值是 i -1 的结点个数
找出度易,入度难
(4)邻接表(链式表示法)实现
【以无向网为例】
1、定义 顶点、边顶点和图的存储结构
public class ALGraph {
// 存储所有顶点的数组
VNode[] vertices;
// 顶点数、边数
int vexNum,arcNum;
}
// 定义顶点结构
class VNode{
// 顶点信息
Object data;
// 指向第一条边顶点的指针
ArcNode firstarc;
@Override
public String toString() {
return "VNode{" +
"data=" + data +
", firstarc=" + firstarc +
'}';
}
}
// 边顶点类型
class ArcNode{
// 边顶点的索引位置
int adjvex;
// 下一个边顶点的地址
ArcNode nextarc;
// 顶点信息
Object info;
@Override
public String toString() {
return "ArcNode{" +
"adjvex=" + adjvex +
", nextarc=" + nextarc +
", info=" + info +
'}';
}
}
2、初始化,将顶点信息存储在顶点表,并初始化头指针为NULL
public class ALGraph {
public static void main(String[] args) {
ALGraph alGraph = new ALGraph(new Object[]{"A","B","C","D"});
System.out.println(Arrays.toString(alGraph.vertices));
}
// 存储所有顶点的数组
VNode[] vertices;
// 顶点数、边数
int vexNum,arcNum;
// 初始化 vnodes==顶点集合
public ALGraph(Object[] vnodes) {
this.vexNum = vnodes.length;
this.vertices = new VNode[this.vexNum];
this.arcNum = 0;
// 将头顶点赋值,指向第一个边为null
for (int i = 0; i < this.vexNum; i++) {
VNode vNode = new VNode();
vNode.data = vnodes[i];
vNode.firstarc = new ArcNode();
this.vertices[i] = vNode;
}
}
}
// 定义顶点结构
class VNode{
// 顶点信息
Object data;
// 指向第一条边顶点的指针
ArcNode firstarc;
@Override
public String toString() {
return "VNode{" +
"data=" + data +
", firstarc=" + firstarc +
'}';
}
}
// 边顶点类型
class ArcNode{
// 边顶点的索引位置
int adjvex;
// 下一个边顶点的地址
ArcNode nextarc;
// 顶点信息
Object info;
@Override
public String toString() {
return "ArcNode{" +
"adjvex=" + adjvex +
", nextarc=" + nextarc +
", info=" + info +
'}';
}
}
3、给定顶点和边的权值生成邻接表
// 生成邻接表 v1 —— v2
public void createALGraph(Object v1,Object v2,int weight) {
// 找到俩个顶点的位置
int i = findIndex(v1);
int j = findIndex(v2);
// 生成新的边顶点
ArcNode arcNode = new ArcNode();
arcNode.adjvex = j;
arcNode.nextarc = vertices[i].firstarc;
arcNode.info = weight;
vertices[i].firstarc = arcNode;
// 由于是无向网,反向也得连接
ArcNode arcNode1 = new ArcNode();
arcNode1.adjvex = i;
arcNode1.nextarc = vertices[j].firstarc;
arcNode1.info = weight;
vertices[j].firstarc = arcNode1;
}
/**
* @description 根据顶点名称找到对应的下标
* @date 2023/8/27 14:51
* @param v 顶点名称
* @return int
*/
public int findIndex(Object v) {
for (int i = 0; i < vertices.length; i++) {
if (vertices[i].data == v) return i;
}
return -1;
}
总结:
邻接矩阵与邻接表的关系
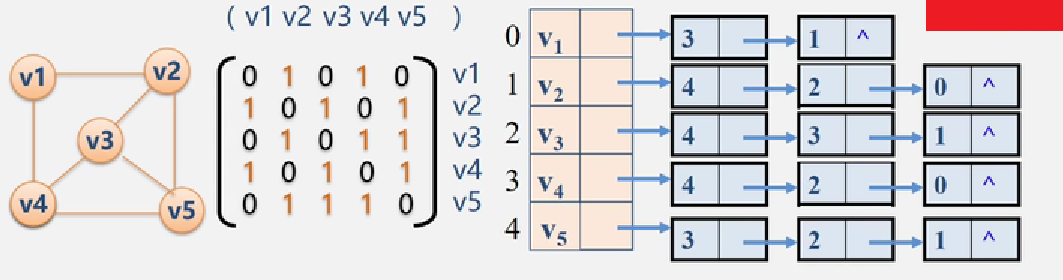
联系:
无论是邻接矩阵还是邻接表,第 i 行都代表 第 i 个顶点与其他顶点的关系。
区别:
对于任一确定的无向图,邻接矩阵是唯一的 (行列号与顶点编号一致),但邻接表不唯一(链接次序与顶点编号无关)
邻接矩阵的空间复杂度为O(n2) , 邻接表的空间复杂度为O(n+e)
用途
邻接矩阵多用于稠密图,而邻接表多用于稀疏图
三、图的遍历
从已给的连通图中某一顶点出发,沿着一些边访遍图中所有的顶点,且使每个顶点仅被访问一次,就叫做图的遍历,它是图的基本运算。
图的特点
图中可能存在回路,且图的任一顶点都可能与其它顶点相通,在访问完某个顶点之后可能会沿着某些边又回到了曾经访问过的顶点。
怎么避免重复访问呢?
可以设置一个辅助数组 visited[n] ,用来表示被访问过的顶点,初始都为false,如果第 i 个顶点被访问,设置 visited[i] = true
图的遍历方法
- 深度优先搜索 (Depth First Search-DFS )
- 广度优先搜索 ( Breadth Frist Search-BFS)
(1)深度优先遍历算法
深度优先遍历(DFS)是一种优先走到底、无路可走再回头的遍历方式。如下图 所示,从左上角顶点出发,访问当前顶点的某个邻接顶点,直到走到尽头时返回,再继续走到尽头并返回,以此类推,直至所有顶点遍历完成。
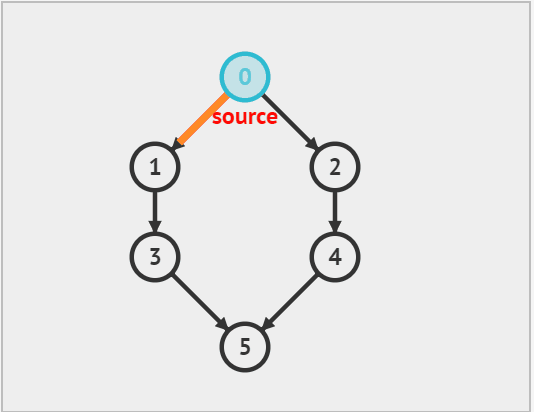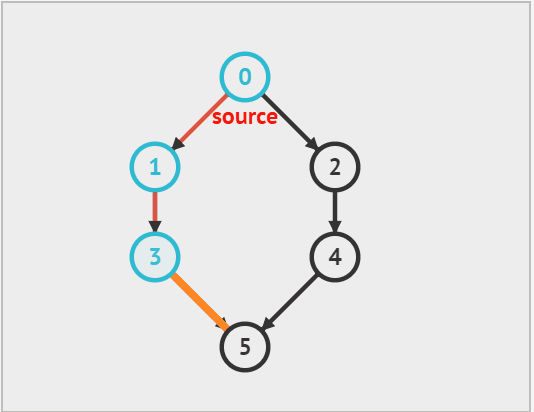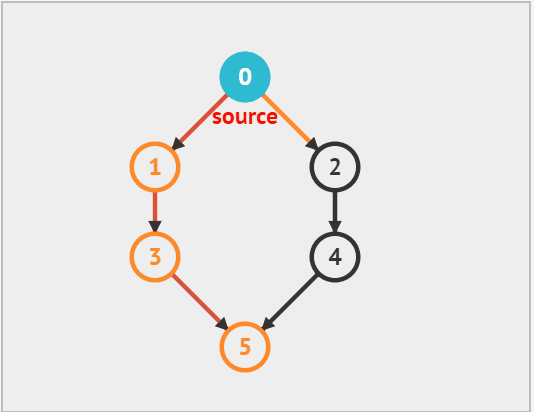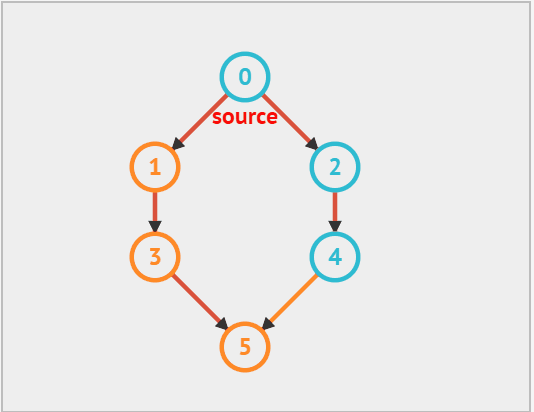
深度优先遍历算法实现
以无向网为例,如下图所示,按照深度优先遍历
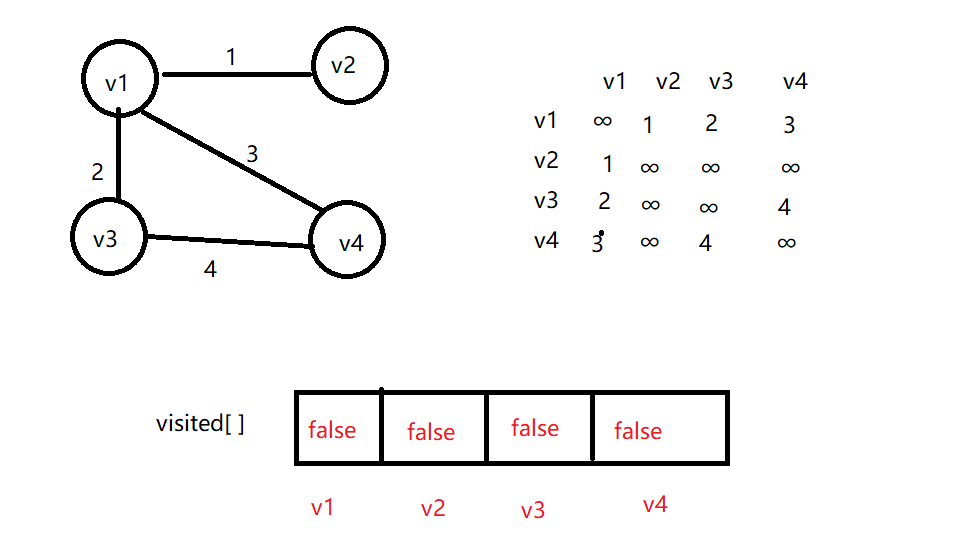
假设从 v1 出发,与之邻接的第一个顶点为 v2,在 visited 数组中发现 v2 并没有被访问过,因此访问 v2,并修改 v2 的访问状态
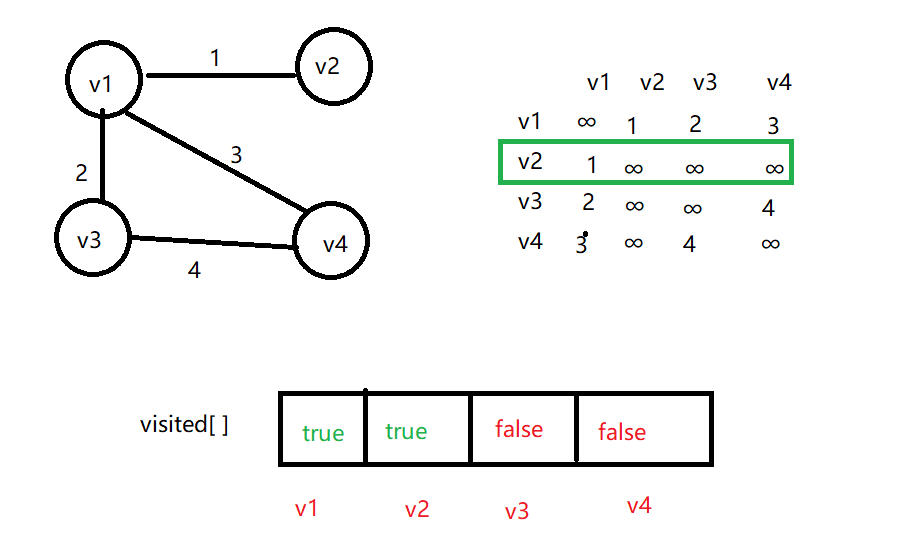
访问完 v2,从邻接矩阵中看出,与之邻接的顶点为v1,但是 v1 已经被访问过。回退到 v1,访问下一个邻接顶点 v3,并修改访问状态。
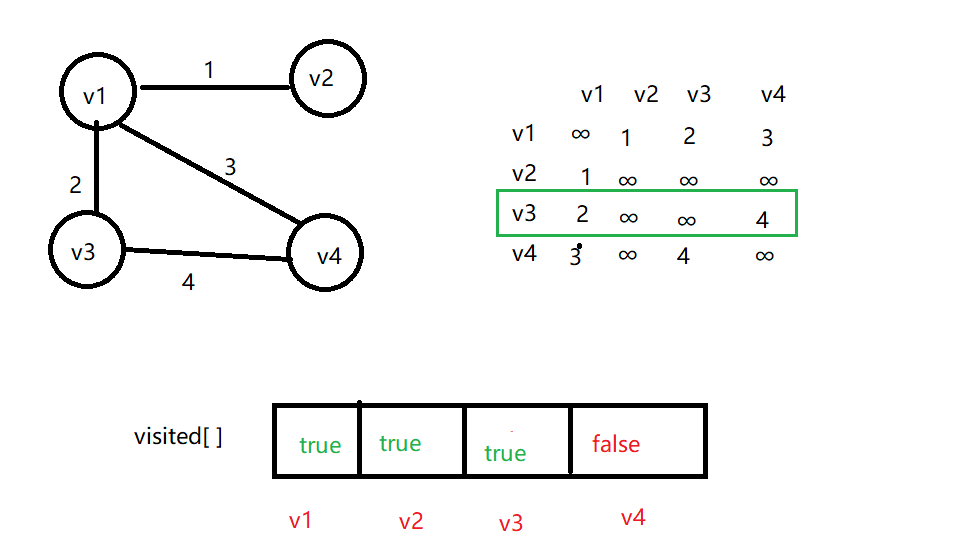
最后访问v4,结束遍历!
代码实现: 完整代码,包括无向网的创建
public class AMGraph {
public static void main(String[] args) {
AMGraph amGraph = new AMGraph(new Object[]{"v1", "v2", "v3", "v4"});
// 增加边
amGraph.createUDN("v1", "v2", 1);
amGraph.createUDN("v1", "v3", 2);
amGraph.createUDN("v1", "v4", 3);
amGraph.createUDN("v3", "v4", 4);
System.out.println(Arrays.deepToString(amGraph.arcs));
// System.out.println("边的个数:" + amGraph.arcNum);
// 从v1开始深度遍历
amGraph.DFS(0);
}
Object[] vexs; // 顶点数组
Object[][] arcs; // 邻接矩阵
int vexNum, arcNum; // 记录顶点、边的个数
// 辅助数组,记录顶点是否被访问
boolean[] visited;
/**
* @description 初始化
* @date 2023/8/27 14:45
* @param vexs 表示顶点数组
* @return
*/
public AMGraph(Object[] vexs) {
this.vexs = vexs;
// 顶点个数
int length = vexs.length;
this.vexNum = length;
this.arcs = new Object[length][length];
this.visited = new boolean[length];
// 初始化访问数组
Arrays.fill(visited, false);
// 初始化邻接矩阵的值皆为∞ ,在Java就用integer的最大值表示
for (int i = 0; i < length; i++) {
for (int j = 0; j < length; j++) {
arcs[i][j] = Integer.MAX_VALUE;
// 无向图
// arcs[i][j] = 0;
}
}
}
/**
* @description 创建无向网
* @date 2023/8/27 14:50
* @param v1 顶点1
* @param v2 顶点2
* @param weight 顶点1和顶点2之间的权值
* @return void
*/
public void createUDN(Object v1, Object v2, int weight) {
// 找到v1、v2的下标
int i = findIndex(vexs, v1);
int j = findIndex(vexs, v2);
// 防止输入错误
if (i == -1 || j == -1) throw new RuntimeException("您输入顶点有误");
// 赋值权重,因为是无向图,所以反向的权值也要赋
arcs[i][j] = weight;
arcs[j][i] = weight;
// 无向图
// arcs[i][j] = arcs[j][i] = 1;
// 有向网
// arcs[i][j] = weight;
// 边的个数+1
this.arcNum++;
}
/**
* @description 根据顶点名称找到对应的下标
* @date 2023/8/27 14:51
* @param vexs 顶点数组
* @param v 顶点名称
* @return int
*/
public int findIndex(Object[] vexs, Object v) {
for (int i = 0; i < vexs.length; i++) {
if (vexs[i] == v) return i;
}
return -1;
}
/**
* @description 深度优先遍历算法
* @date 2023/8/29 22:22
* @param v 访问的顶点下标
* @return void
*/
public void DFS(int v) {
// 访问当前顶点
System.out.println(vexs[v]);
// 更改访问记录值
visited[v] = true;
// 访问邻接顶点
for (int i = 0; i < vexs.length; i++) {
// 该邻接顶点没有 被访问过
if (((int) arcs[v][i]) != Integer.MAX_VALUE && !visited[i]) {
// 递归访问
DFS(i);
}
}
}
}
(2)广度优先遍历算法
广度优先遍历(BFS)是一种由近及远的遍历方式,从某个顶点出发,始终优先访问距离最近的顶点,并一层层向外扩张。如下图所示,从左上角顶点出发,首先遍历该顶点的所有邻接顶点,然后遍历下一个顶点的所有邻接顶点,以此类推,直至所有顶点访问完毕。
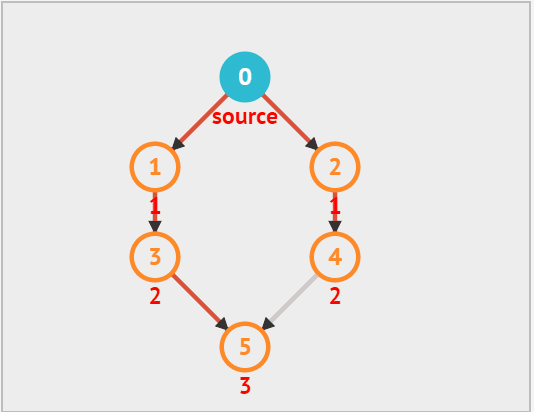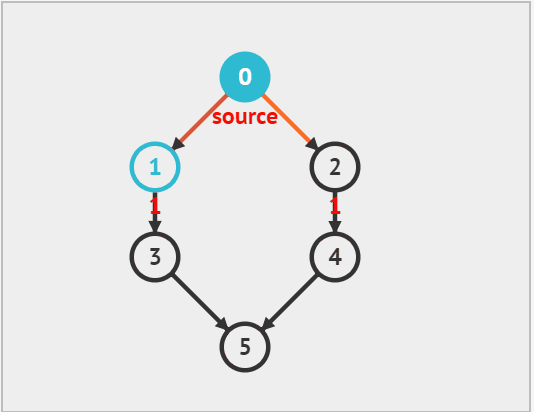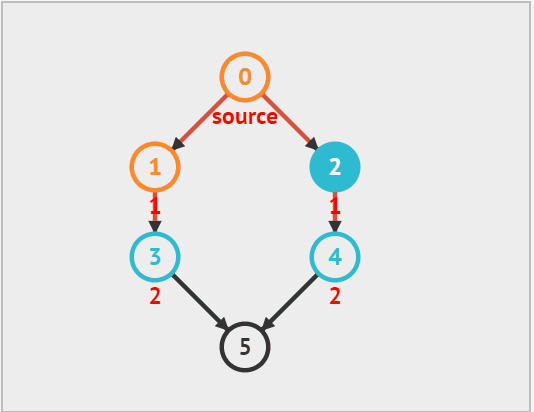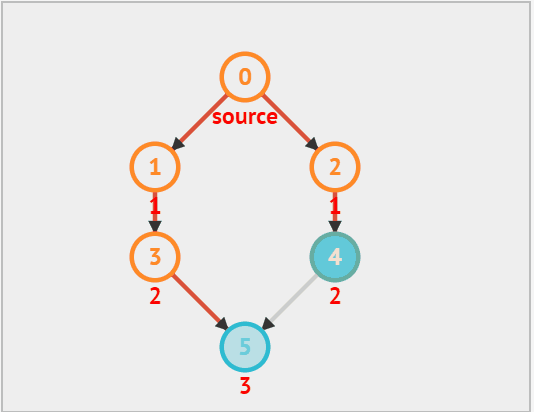
广度优先算法其实和树的层次遍历有些类似,都是一层一层的遍历,因此我们仍然利用 队列 来实现。
public class AMGraph {
public static void main(String[] args) {
AMGraph amGraph = new AMGraph(new Object[]{"v1", "v2", "v3", "v4"});
// 增加边
amGraph.createUDN("v1", "v2", 1);
amGraph.createUDN("v1", "v3", 2);
amGraph.createUDN("v1", "v4", 3);
amGraph.createUDN("v3", "v4", 4);
System.out.println(Arrays.deepToString(amGraph.arcs));
// System.out.println("边的个数:" + amGraph.arcNum);
// 从v1开始深度遍历
amGraph.DFS(0);
}
Object[] vexs; // 顶点数组
Object[][] arcs; // 邻接矩阵
int vexNum, arcNum; // 记录顶点、边的个数
// 辅助数组,记录顶点是否被访问
boolean[] visited;
/**
* @description 初始化
* @date 2023/8/27 14:45
* @param vexs 表示顶点数组
* @return
*/
public AMGraph(Object[] vexs) {
this.vexs = vexs;
// 顶点个数
int length = vexs.length;
this.vexNum = length;
this.arcs = new Object[length][length];
this.visited = new boolean[length];
// 初始化访问数组
Arrays.fill(visited, false);
// 初始化邻接矩阵的值皆为∞ ,在Java就用integer的最大值表示
for (int i = 0; i < length; i++) {
for (int j = 0; j < length; j++) {
arcs[i][j] = Integer.MAX_VALUE;
// 无向图
// arcs[i][j] = 0;
}
}
}
/**
* @description 创建无向网
* @date 2023/8/27 14:50
* @param v1 顶点1
* @param v2 顶点2
* @param weight 顶点1和顶点2之间的权值
* @return void
*/
public void createUDN(Object v1, Object v2, int weight) {
// 找到v1、v2的下标
int i = findIndex(vexs, v1);
int j = findIndex(vexs, v2);
// 防止输入错误
if (i == -1 || j == -1) throw new RuntimeException("您输入顶点有误");
// 赋值权重,因为是无向图,所以反向的权值也要赋
arcs[i][j] = weight;
arcs[j][i] = weight;
// 无向图
// arcs[i][j] = arcs[j][i] = 1;
// 有向网
// arcs[i][j] = weight;
// 边的个数+1
this.arcNum++;
}
/**
* @description 根据顶点名称找到对应的下标
* @date 2023/8/27 14:51
* @param vexs 顶点数组
* @param v 顶点名称
* @return int
*/
public int findIndex(Object[] vexs, Object v) {
for (int i = 0; i < vexs.length; i++) {
if (vexs[i] == v) return i;
}
return -1;
}
// BFS算法
public void BFS(int vIndex) {
// 使用队列保存顶点信息
LinkedList<Integer> queue = new LinkedList<>();
// 将当前结点入队并标记访问
queue.add(vIndex);
isVisited[vIndex] = true;
while(!queue.isEmpty()) {
// 弹出当前结点下标
int index = queue.poll();
System.out.println(vexs[index]);
// 找到与当前结点相邻的、没有访问过的顶点,入队!
for (int i = 0; i < vexs.length; i++) {
if ((int)arcs[index][i] != Integer.MAX_VALUE && !isVisited[i]) {
queue.add(i);
isVisited[i] = true;
}
}
}
}
}
四、图的应用
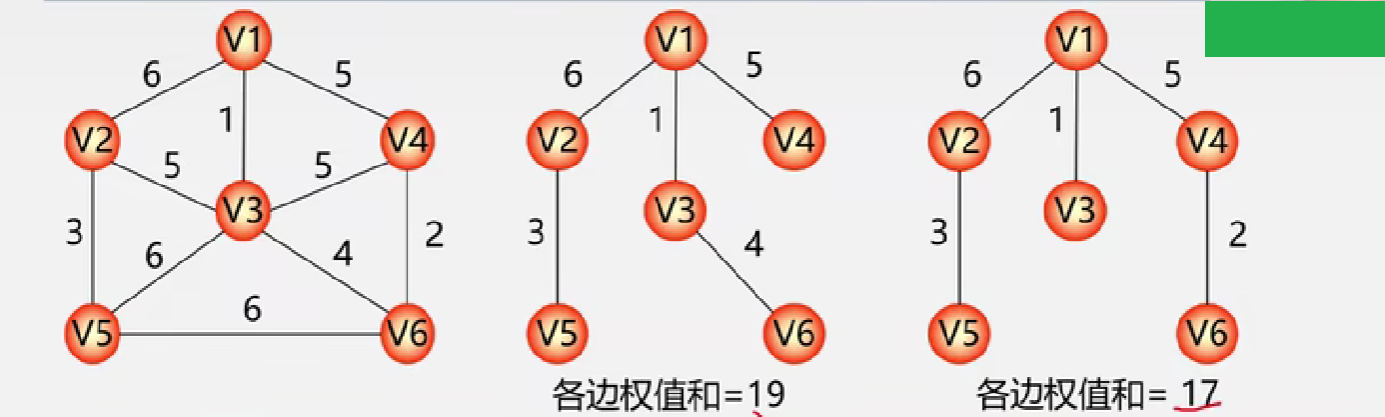
1、构造最小生成树
最小生成树: 最小生成树是解决用最小的代价将图上的所有点连接起来的问题,也叫最小代价生成树
最小生成树的典型用途
欲在n个城市间建立通信网,则n个城市应铺n-1条线路
但因为每条线路都会有对应的经济成本,而n个城市最多有n(n-1)/2条线路,那么,如何选择n-1条线路,使总费用最少?
此问题我们就可以转化为求最小生成树,n个城市看做n个顶点,线路看做边,经济成本看做权值。
普里姆算法(Prim)
Prim算法是从任意一个顶点开始,每次选择与当前顶点邻仅的顶点权值最小的边,加入到最小生成树中
算法思想
设 G =(V,E) 是连通图,V表示所有的顶点,E表示所有的边
U表示已选择顶点的集合,V-U表示未选择顶点的集合,普里姆算法就是选择连接这俩个集合的最小权值的边,同时更新集合的过程!不断执行 选择-更新 步骤,直到最小生成树完毕!
【算法演示】
普里姆算法的实现主要是根据三个集合来实现的
- 已选择顶点的集合
selected, 已选择的顶点为 true,反之为false - 当前选择的顶点到最小生成树集合所有边中最小边的权值
minDist, 初始化为最大值 - 当前选择顶点的前驱顶点
parent,初始化为-1
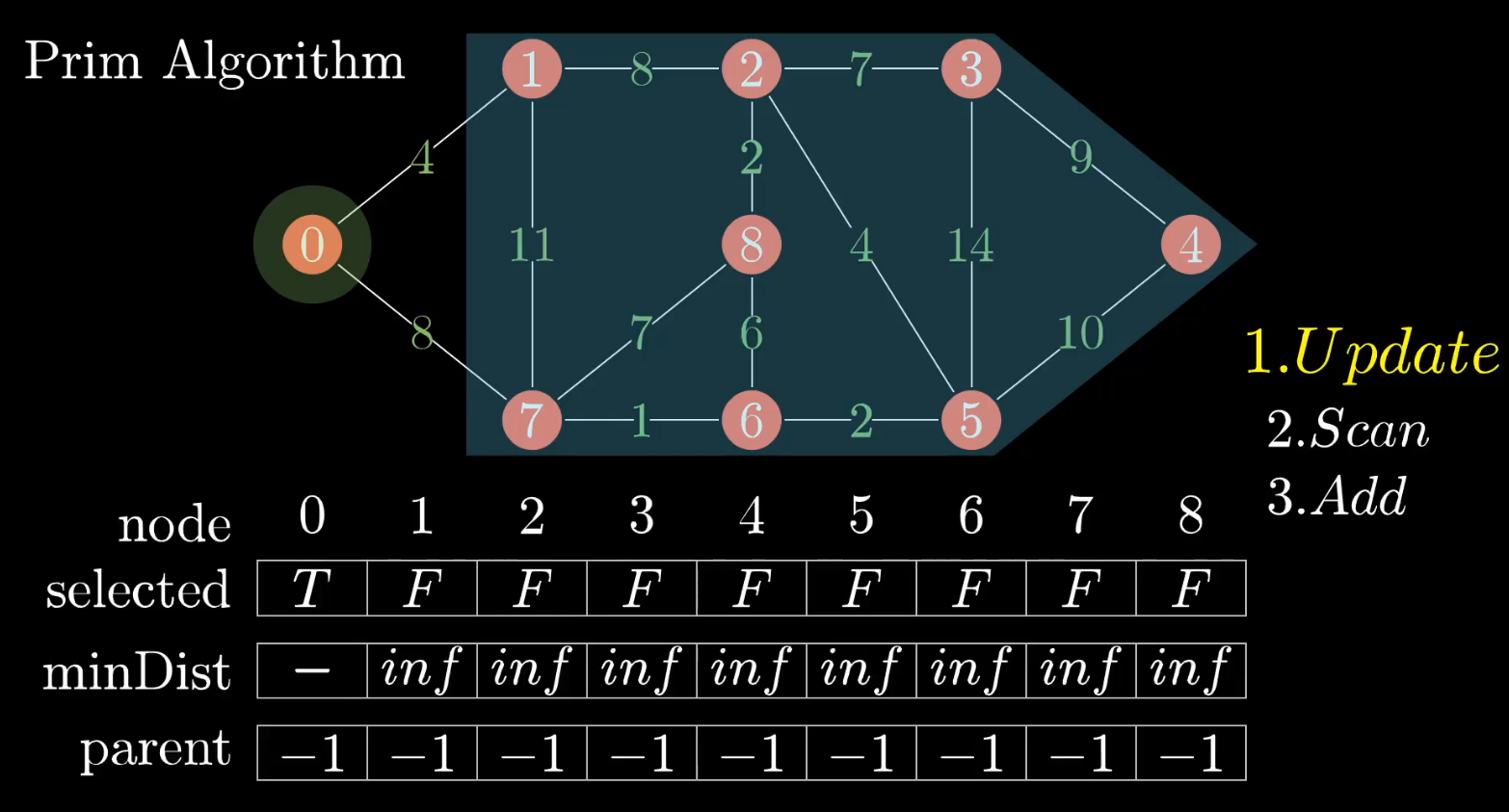
- 每次向顶点集合中增加一个顶点,就在
minDist中修改与这个顶点相邻的所有顶点边的值,前提是这个边的值 小于minDist中的值,并修改parent
1、如上图所示,如果从顶点0开始出发,与之相邻的顶点为1、7,并且这俩个边的值都小于 inf , 因此 更新 minDist、parent
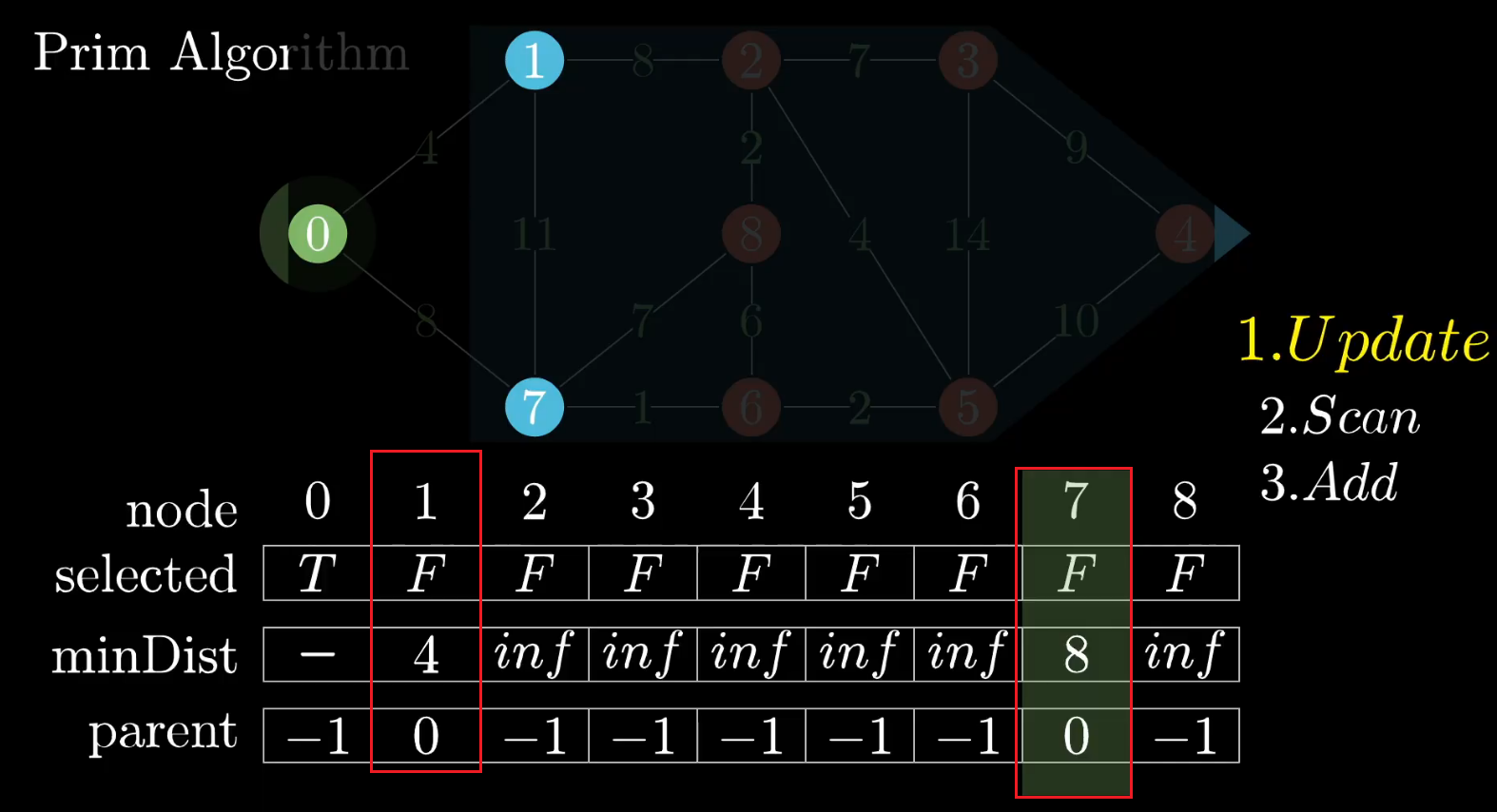
2、扫描 最小距离列表 minDist ,选择边最小的顶点,如图所示:选择顶点1
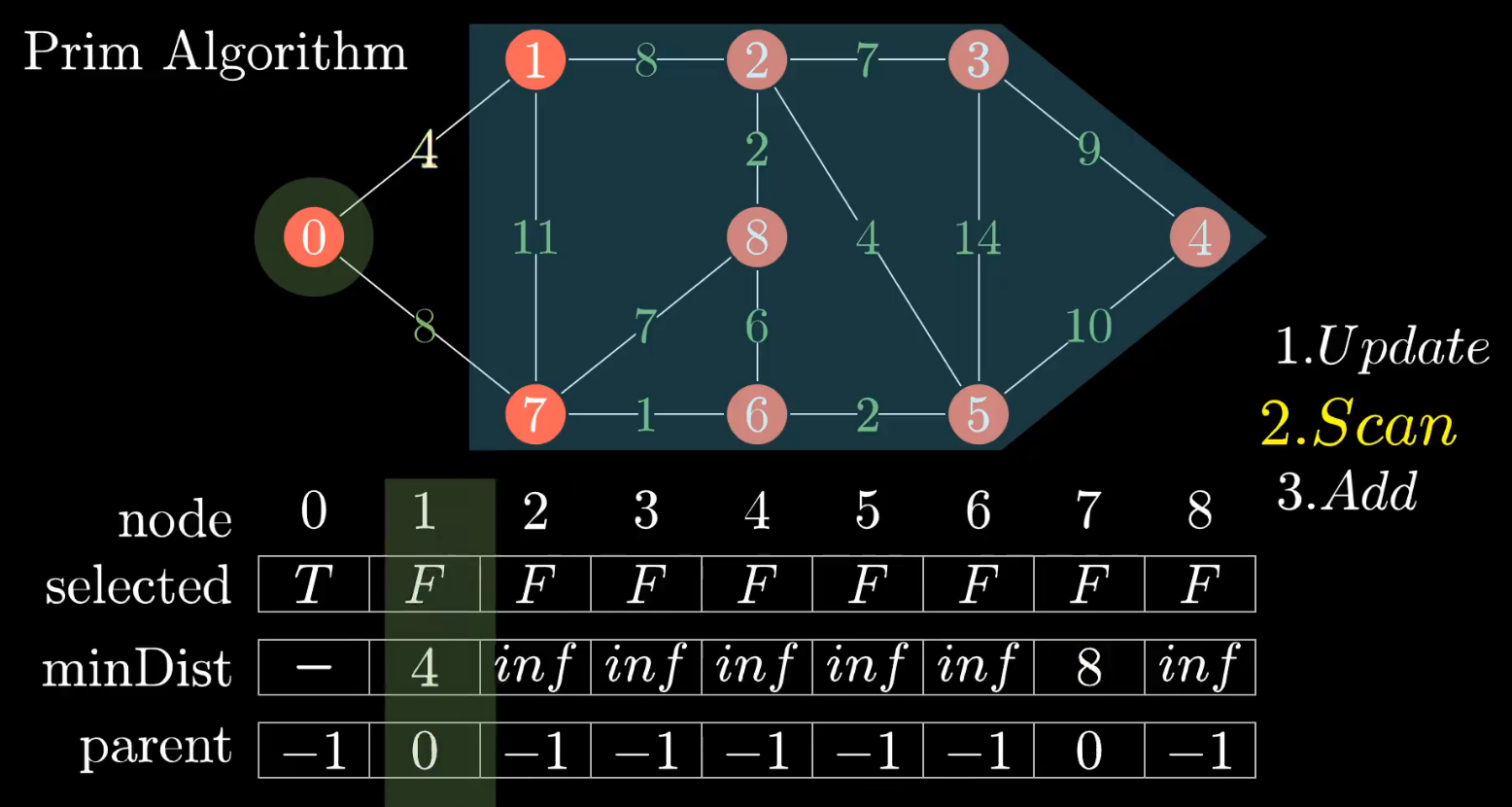
3、增加上面刚选择的顶点1,修改 selected 集合标记顶点1 已被访问
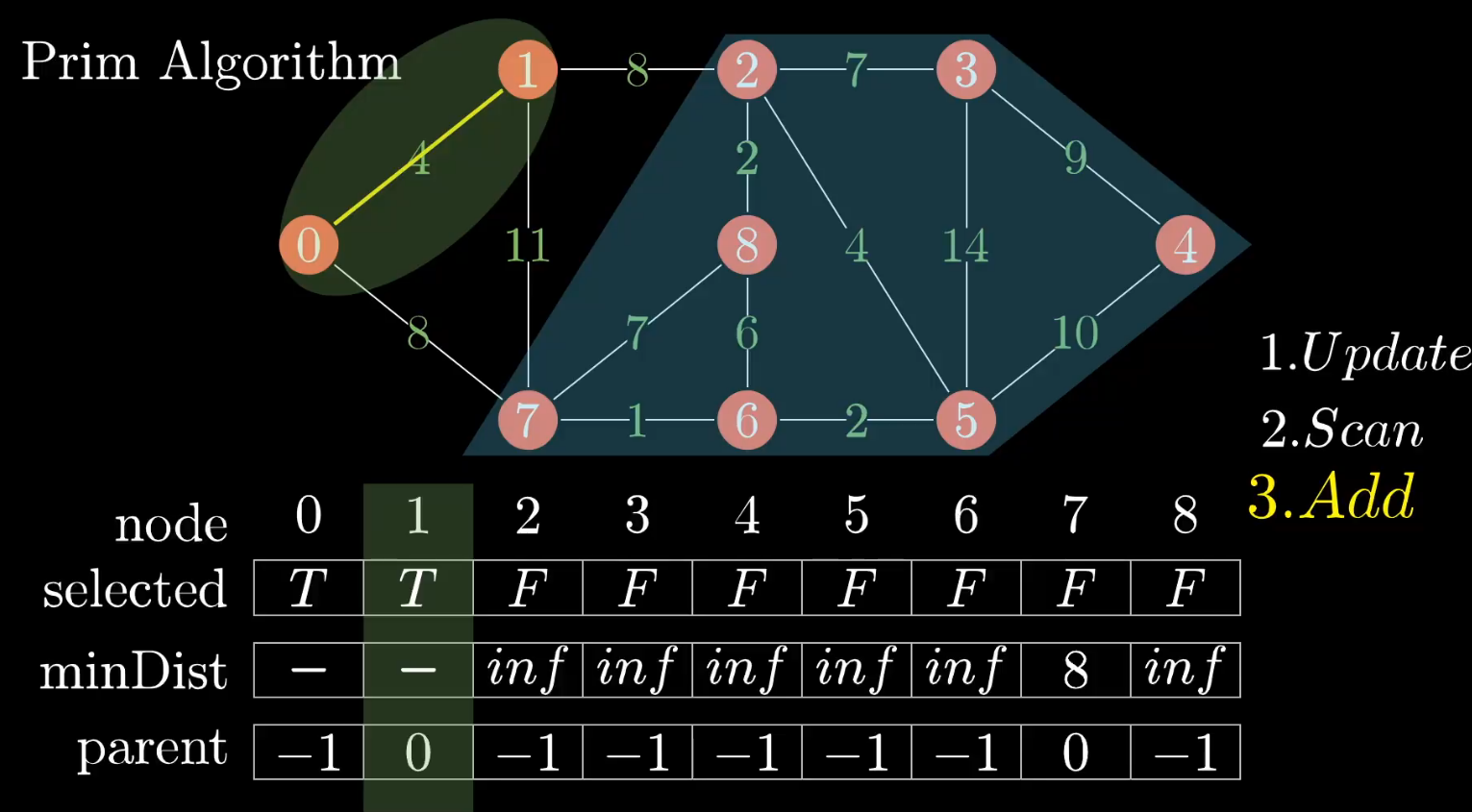
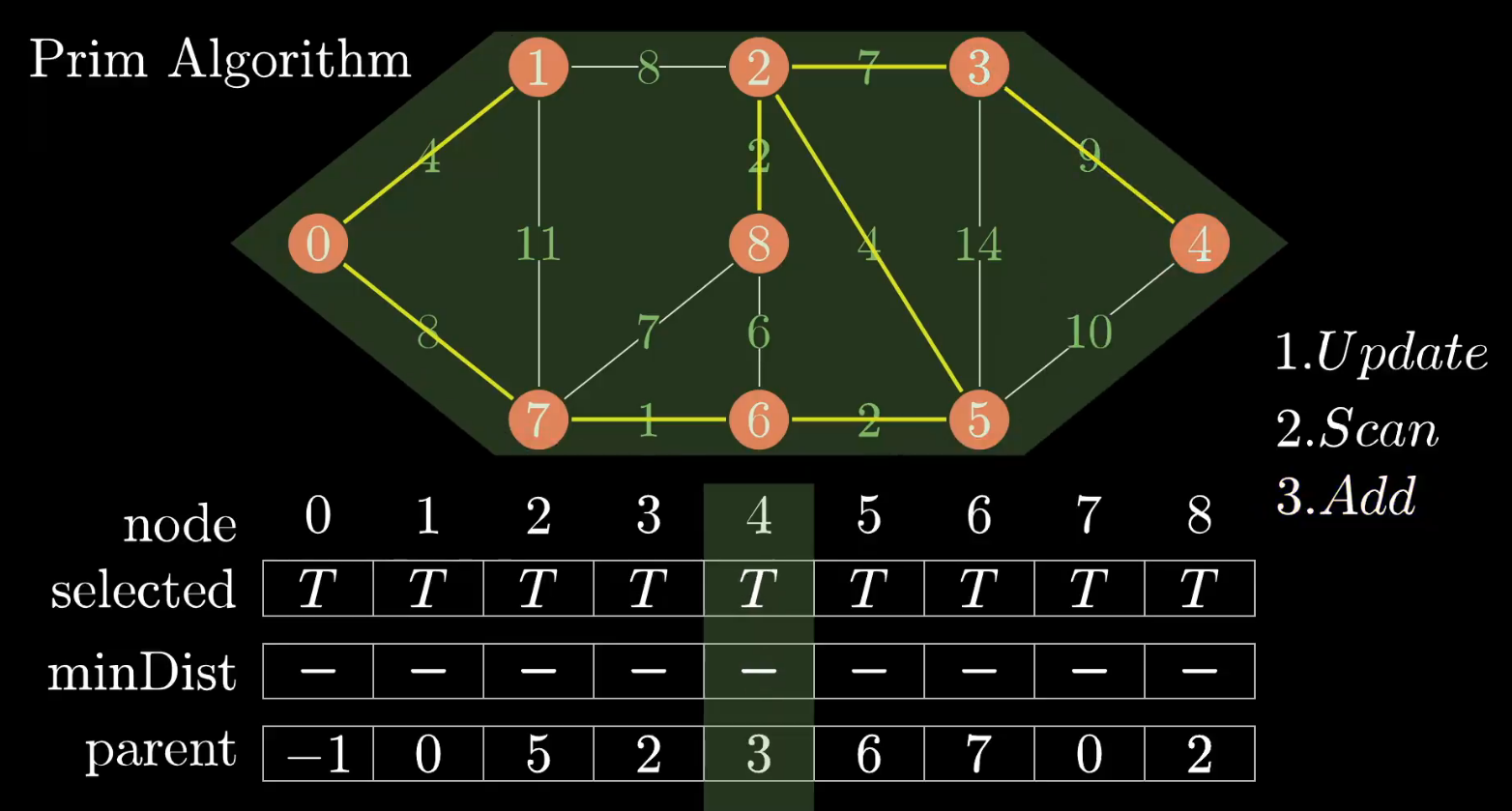
再以上面新增的顶点1为起始点,重复上面三步,当已选择集合包括所有顶点时,最小生成树完毕!
代码实现
public class Graph {
public static void main(String[] args) {
AmGraph amGraph = new AmGraph(new Object[]{"v1", "v2", "v3", "v4","v5","v6"});
// 增加边
amGraph.addArc("v1", "v2", 6);
amGraph.addArc("v1", "v3", 1);
amGraph.addArc("v1", "v4", 5);
amGraph.addArc("v2", "v3", 5);
amGraph.addArc("v2", "v5", 3);
amGraph.addArc("v3", "v5", 6);
amGraph.addArc("v3", "v6", 4);
amGraph.addArc("v3", "v4", 5);
amGraph.addArc("v4", "v6", 2);
amGraph.addArc("v5", "v6", 6);
System.out.println(Arrays.deepToString(amGraph.arcs));
System.out.println("边的个数:" + amGraph.arcNum);
amGraph.primMST();
}
}
class AmGraph {
// 顶点集合
Object[] vexs;
// 保存邻接矩阵
Object[][] arcs;
// 记录边、顶点的个数
int vexNum;
int arcNum;
// 通过传入一个顶点数组进行初始化
public AmGraph(Object[] vexs) {
this.vexs = vexs;
this.vexNum = vexs.length;
this.arcs = new Object[vexs.length][vexs.length];
// 初始化邻接矩阵为∞
for (int i = 0; i < this.arcs.length; i++) {
Arrays.fill(arcs[i], Integer.MAX_VALUE);
}
}
/**
* @description 增加边
* @date 2024/4/22 11:00
* @param v1 顶点1
* @param v2 顶点2
* @param weight 权值
* @return void
*/
public void addArc(Object v1, Object v2, int weight) {
// 找到俩个顶点对应的下标
int v1Index = findArcIndex(v1, this.vexs);
int v2Index = findArcIndex(v2, this.vexs);
// 设置权值,由于是无向网,需要双向设置权值
this.arcs[v1Index][v2Index] = weight;
this.arcs[v2Index][v1Index] = weight;
this.arcNum++;
}
/**
* @description 找到顶点的下标
* @date 2024/4/22 11:01
* @param v1 顶点
* @param vexs 顶点集合
* @return int
*/
public int findArcIndex(Object v1, Object[] vexs) {
for (int i = 0; i < vexs.length; i++) {
if (vexs[i].equals(v1)) return i;
}
throw new RuntimeException("顶点不存在");
}
/*
* 普里姆算法构建最小生成树
* */
public void primMST() {
// 判断某个顶点是否在最小生成树中
boolean[] selected = new boolean[vexNum];
// 记录选择的顶点的前驱顶点
int[] parent = new int[vexNum];
// 保存选择顶点的边的最小权值
int[] minDist = new int[vexNum];
// 初始化权值为最大值,逐渐更新
Arrays.fill(minDist, Integer.MAX_VALUE);
Arrays.fill(parent, -1);
// 第一个顶点的权值为0
minDist[0] = 0;
for (int i = 0; i < vexNum; i++) {
// 遍历所有的顶点,并选取没有加入到最小生成树中的最小权值的顶点下标
int minIndex = findMinIndex(minDist, selected);
// 标记该顶点
selected[minIndex] = true;
// 找到与该顶点相连的其他顶点
for (int j = 0; j < vexNum; j++) {
// 判断与minIndex相连的顶点是否被标记过、是否是最小权值
if ((int) arcs[minIndex][j] != Integer.MAX_VALUE && !selected[j] && (int) arcs[minIndex][j] < minDist[j]) {
minDist[j] = (int) arcs[minIndex][j]; // 更新最小权值
parent[j] = minIndex; // 更新前驱顶点
}
}
}
printPrim(parent, arcs);
}
// 找到没有在最小生成树且权值最小的顶点
private int findMinIndex(int[] key, boolean[] inMST) {
int min = Integer.MAX_VALUE;
int minIndex = -1;
for (int i = 0; i < vexNum; i++) {
if (!inMST[i] && key[i] < min) {
min = key[i];
minIndex = i;
}
}
return minIndex;
}
public void print(int[] parent, Object[][] arcs){
for (int i = 1; i < vexNum; i++){
System.out.println(vexs[parent[i]] + "-" + vexs[i] + "\t" + arcs[i][parent[i]]);
}
}
}
输出结果

克鲁斯卡尔算法(Kruskal)
Kruskal算法是一种用于找到无向图的最小生成树的贪心算法。它通过不断地选择图中权值最小的边,并确保所选边不会形成环,直到生成树中包含了图中所有的顶点为止。
下面是Kruskal算法的基本步骤:
- 将图中的所有边按权值从小到大进行排序。
- 从权值最小的边开始,依次考虑每一条边:
- 如果当前边连接的两个顶点不在同一连通分量中,则将该边加入最小生成树,并合并这两个连通分量。
- 如果当前边连接的两个顶点已经在同一连通分量中,则忽略这条边。
- 重复步骤2,直到最小生成树中包含了图中所有的顶点。
如果在 “同一连通分量” ,说明这俩个顶点已经是相连了,此时没有必要将这条边在增加到最小生成树了,否则会生成回路!
因此判断是否在 同一连通分量 转换为 俩个顶点是否存在回路?
- 判断是否回路的方法就是:
判断俩个顶点的终点是否相同
比如下面这张图,在第三步已经选择了 <C,D> ,<E,D> ,<F,E> ,三条边,此时按照权值大小,第四步应该选择 <C,F> , 但是若是选择的话,此时 C的终点是 C,F的终点是F,造成回路,应该跳过!
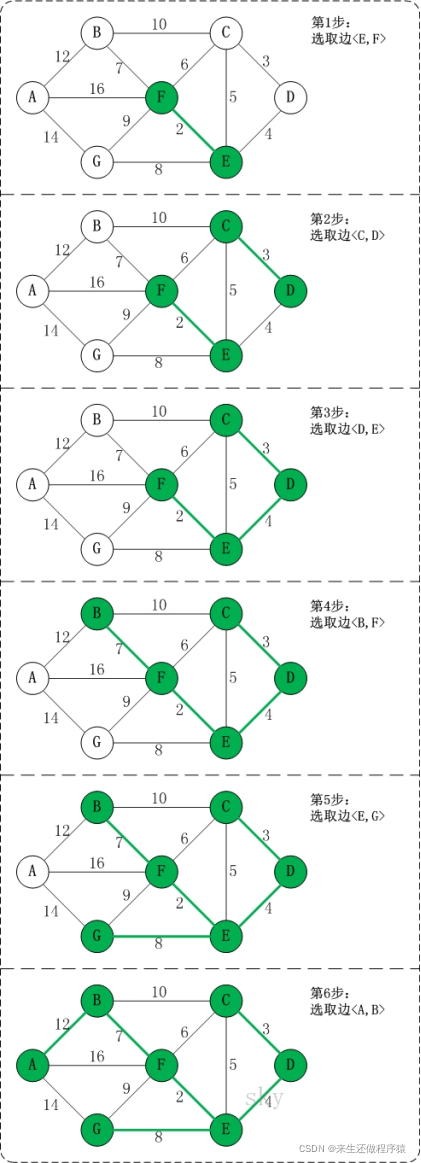
代码实现
public class Graph {
public static void main(String[] args) {
AmGraph amGraph = new AmGraph(new Object[]{"v1", "v2", "v3", "v4", "v5", "v6"});
// 增加边
amGraph.addArc("v1", "v2", 6);
amGraph.addArc("v1", "v3", 1);
amGraph.addArc("v1", "v4", 5);
amGraph.addArc("v2", "v3", 5);
amGraph.addArc("v2", "v5", 3);
amGraph.addArc("v3", "v5", 6);
amGraph.addArc("v3", "v6", 4);
amGraph.addArc("v3", "v4", 5);
amGraph.addArc("v4", "v6", 2);
amGraph.addArc("v5", "v6", 6);
System.out.println(Arrays.deepToString(amGraph.arcs));
System.out.println("边的个数:" + amGraph.arcNum);
amGraph.kruskalMST();
}
}
/*
* 实现图的创建
* */
class AmGraph {
// 顶点集合
Object[] vexs;
// 保存邻接矩阵
Object[][] arcs;
// 记录边、顶点的个数
int vexNum;
int arcNum;
// 通过传入一个顶点数组进行初始化
public AmGraph(Object[] vexs) {
this.vexs = vexs;
this.vexNum = vexs.length;
this.arcs = new Object[vexs.length][vexs.length];
// 初始化邻接矩阵为∞
for (int i = 0; i < this.arcs.length; i++) {
Arrays.fill(arcs[i], Integer.MAX_VALUE);
}
}
/**
* @description 增加边
* @date 2024/4/22 11:00
* @param v1 顶点1
* @param v2 顶点2
* @param weight 权值
* @return void
*/
public void addArc(Object v1, Object v2, int weight) {
// 找到俩个顶点对应的下标
int v1Index = findArcIndex(v1, this.vexs);
int v2Index = findArcIndex(v2, this.vexs);
// 设置权值,由于是无向网,需要双向设置权值
this.arcs[v1Index][v2Index] = weight;
this.arcs[v2Index][v1Index] = weight;
this.arcNum++;
}
/**
* @description 找到顶点的下标
* @date 2024/4/22 11:01
* @param v1 顶点
* @param vexs 顶点集合
* @return int
*/
public int findArcIndex(Object v1, Object[] vexs) {
for (int i = 0; i < vexs.length; i++) {
if (vexs[i].equals(v1)) return i;
}
throw new RuntimeException("顶点不存在");
}
// 获取所有的边
public Edge[] getAllEdge() {
Edge[] edges = new Edge[arcNum];
int index = 0;
for (int i = 0; i < arcs.length; i++) {
for (int j = i + 1; j < arcs[i].length; j++) {
if ((int) arcs[i][j] != Integer.MAX_VALUE) {
edges[index++] = new Edge(i, j, (int) arcs[i][j]);
}
}
}
return edges;
}
/**
*
* 克鲁斯卡尔算法构建最小生成树
*/
public void kruskalMST() {
// 保存最小生成树的顶点
int[] parent = new int[vexNum];
Arrays.fill(parent, -1);
// 保存最终结果
List<Edge> res = new ArrayList<>();
// 获取所有的边并根据权值进行排序
Edge[] edges = getAllEdge();
Arrays.sort(edges, Comparator.comparingInt(e -> e.weight));
for (int i = 0; i < edges.length; i++) {
Edge edge = edges[i];
// 获取每条边俩个顶点的终点
int v1Root = findRoot(edge.start, parent);
int v2Root = findRoot(edge.end, parent);
if (v1Root != v2Root) {
// 俩个顶点的终点不相同,也就是不在同一连通分量里
res.add(edge);
// 并设置俩个结点的终点
parent[v1Root] = v2Root;
}
}
printKruskal(res);
}
/*
* 递归找到顶点的终点
* */
private int findRoot(int start, int[] parent) {
if (parent[start] == -1) return start;
return findRoot(parent[start], parent);
}
private void printKruskal(List<Edge> res) {
for (Edge v : res) {
System.out.println(vexs[v.start] + "-" + vexs[v.end] + "\t" + v.weight);
}
}
}
// 边
class Edge {
// start、end: 边的俩个顶点下标
int start;
int end;
// 权值
int weight;
public Edge(int start, int end, int weight) {
this.start = start;
this.end = end;
this.weight = weight;
}
@Override
public String toString() {
return "Edge{" +
"start=" + start +
", end=" + end +
", weight=" + weight +
'}';
}
}
总结: 俩种算法对比
普里姆(Prim)算法和克鲁斯卡尔(Kruskal)算法都是用于找到无向图的最小生成树的贪心算法
贪心策略:
- 普里姆:普利姆算法从一个
初始顶点开始,逐步扩展生成树,每次选择与生成树相邻的权值最小的边,并确保所选边不会形成环,直到生成树包含了图中所有的顶点为止。 - 克鲁斯卡尔: 按照
边的权重排序,逐渐考虑每一条边,如果边的俩个顶点不在同一连通分量上,则加入最小生成树,知道包含图中所有顶点
适用情况
- 普里姆算法是用于
稠密图, 边与顶点的平方接近 - 克鲁斯卡尔适用于
稀疏图, 边远远小于顶点的平方
时间复杂度
- 普里姆算法:O(N2)
- 克鲁斯卡尔:O(Elog(E))
- N为顶点个数,E为边的个数

2、最短路径
典型用途:交通网络的问题一从甲地到地之间是否有公路连通?在有多条通路的情况下,哪一条路最短?
那么交通网络用有向图来表示,顶点表示地点,俩个地点的连通用弧表示,权值表示俩地之间的距离。
问题抽象: 在有向网中A点(源点)达 B 点(终点)的多条路径中,寻找一条各边权值之和最小的路径,即最短路径
最短路径与最小生成树不同,路径上不一定包含 n个顶点,也不-定包含 n-1条边
第一类问题: 从一个顶点到其他顶点的最短距离——迪杰斯特拉(Dijkstra)算法
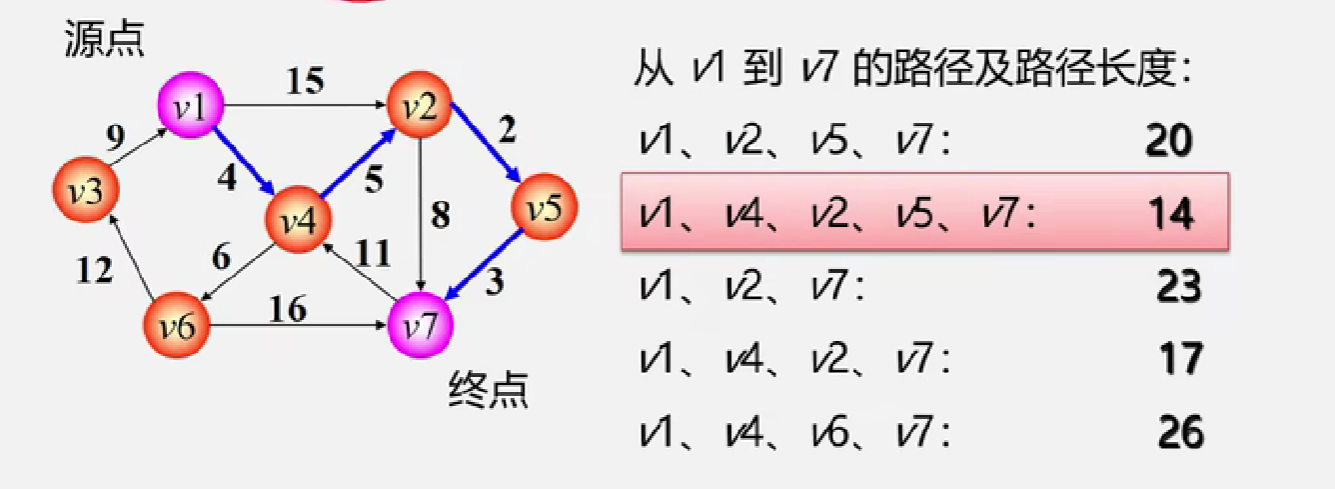
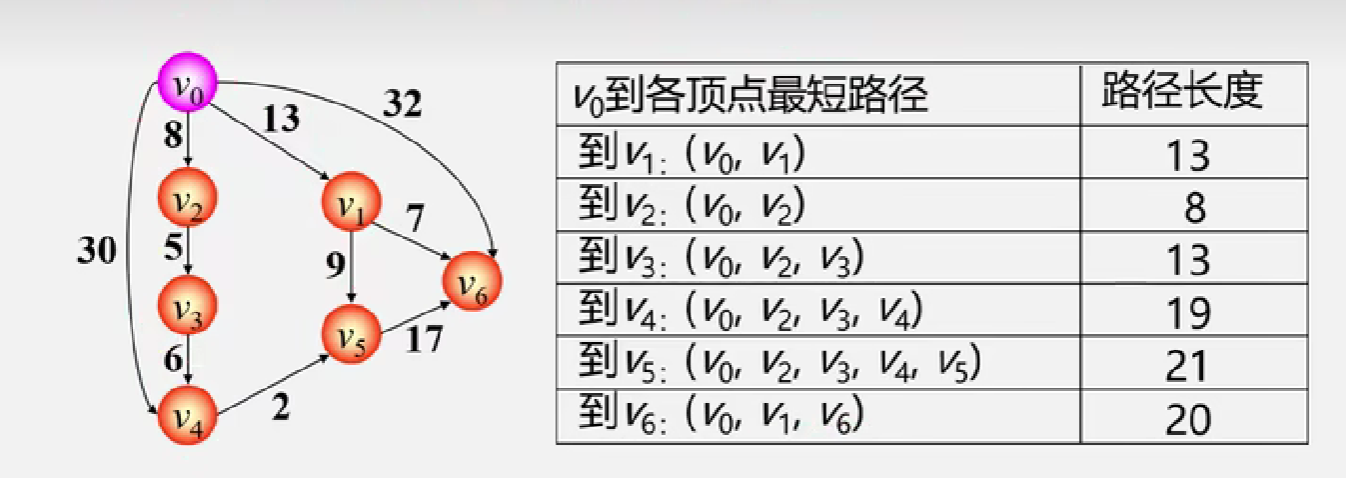
第二类问题:任意俩点的最短路径——通常使用弗洛伊德—Floyd算法求解
迪杰斯特拉(Dijkstra)
迪杰斯特拉(Dijkstra)算法是典型最短路径算法,用于计算一个结点到其他结点的最短路径。 它的主要特点是以起始点为中心向外层层扩展(广度优先搜索思想),直到扩展到终点为止。
【案例说明】
如下图所示,从顶点0到顶点4的最短路径是多少,如何走?
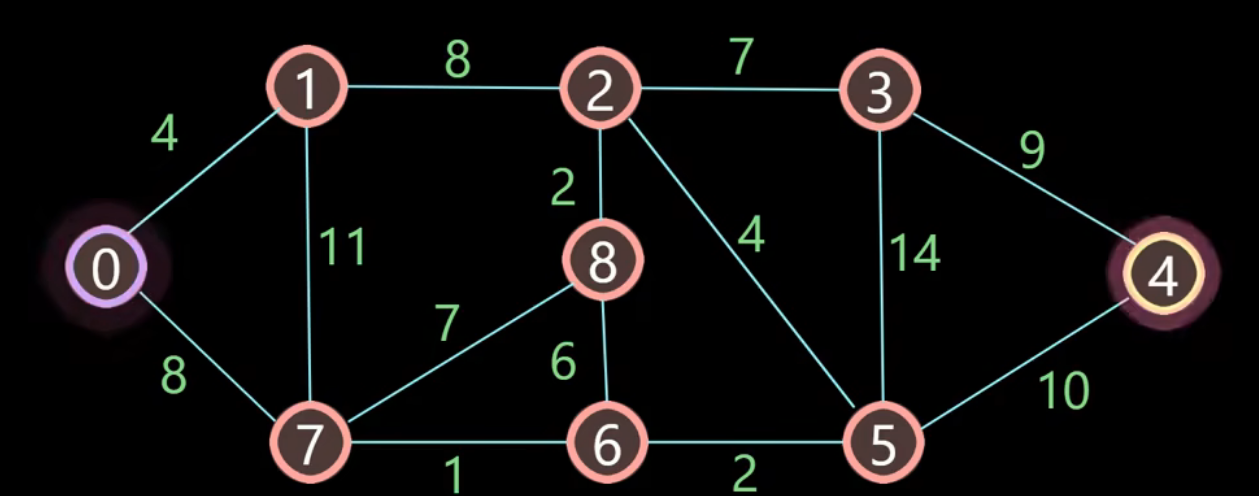
首先需要一张表格记录顶点0到各个顶点的距离,初始时都为 ∞, 当然自己到自己的距离为0 ,并且需要记录当前顶点的前驱顶点
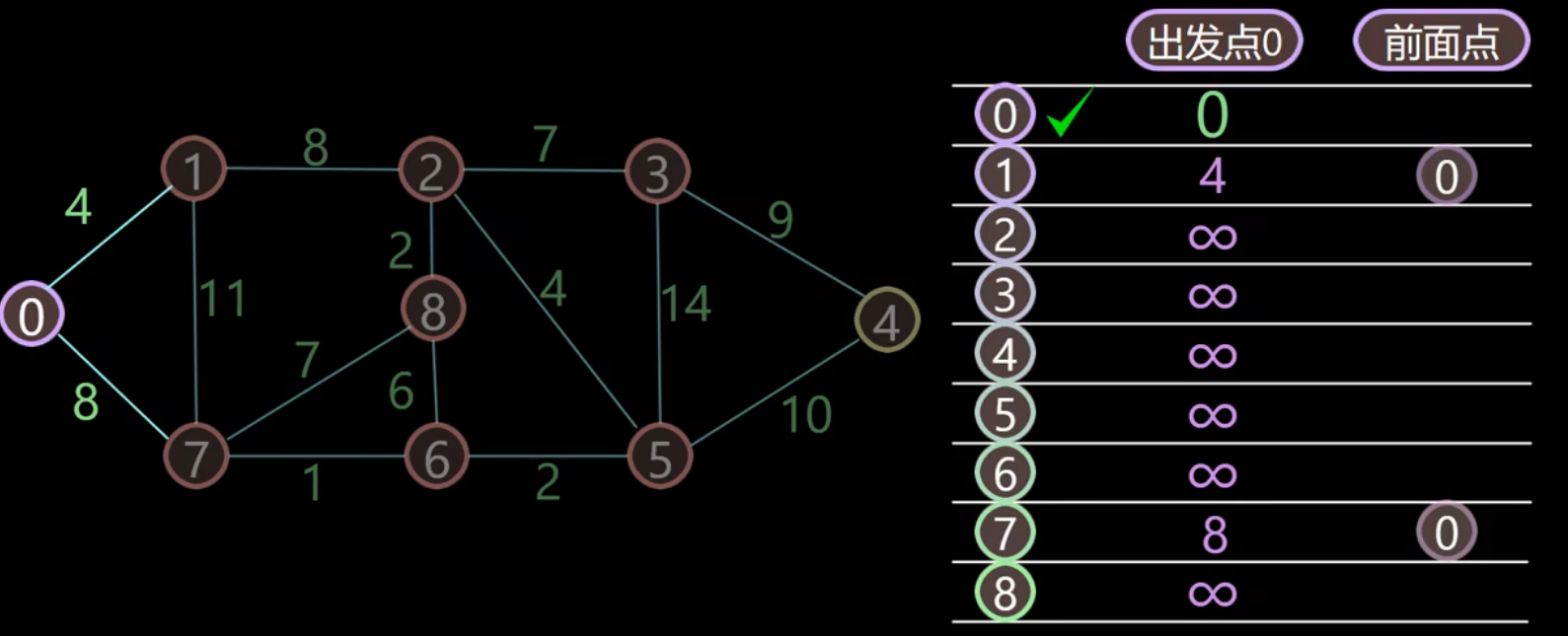
1、开始标记与顶点0距离最短的顶点,自己与自己最短,所以标记顶点0!
- 更新与顶点0邻近的顶点1、7距离
- 更新顶点1、7的前驱顶点为0
2、从未被标记的顶点中选取 与出发点0距离最短的顶点,因此标记顶点4
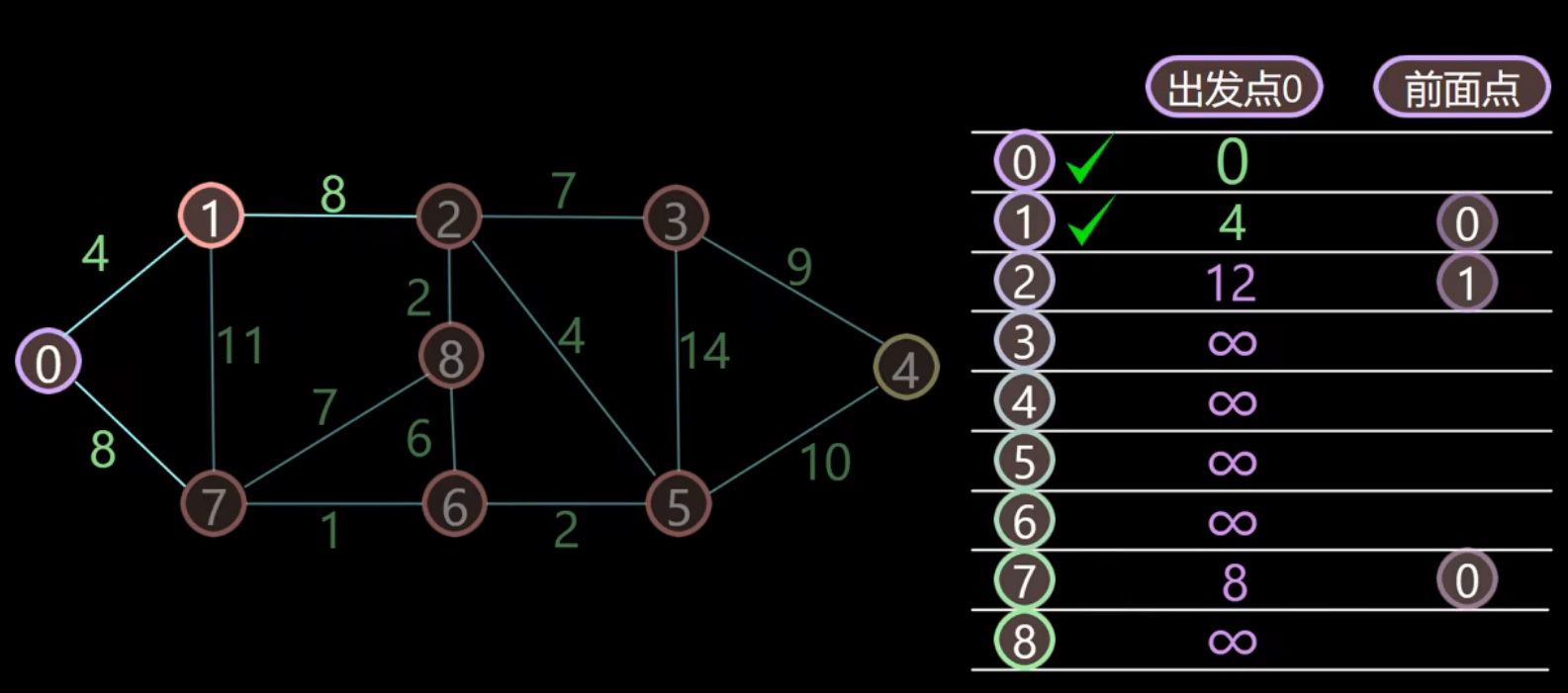
- 计算与顶点4邻近的顶点2、7的距离
- 对于顶点2来说,从顶点0经过顶点1到顶点2的距离为:4+8=12,小于表格中顶点2本身的距离,所以更新距离以及前驱顶点
- 对于顶点7来说,如果从顶点0经过顶点1到顶点7,距离为 4+11=15,大于表格中顶点7原本的距离8,因此不更新
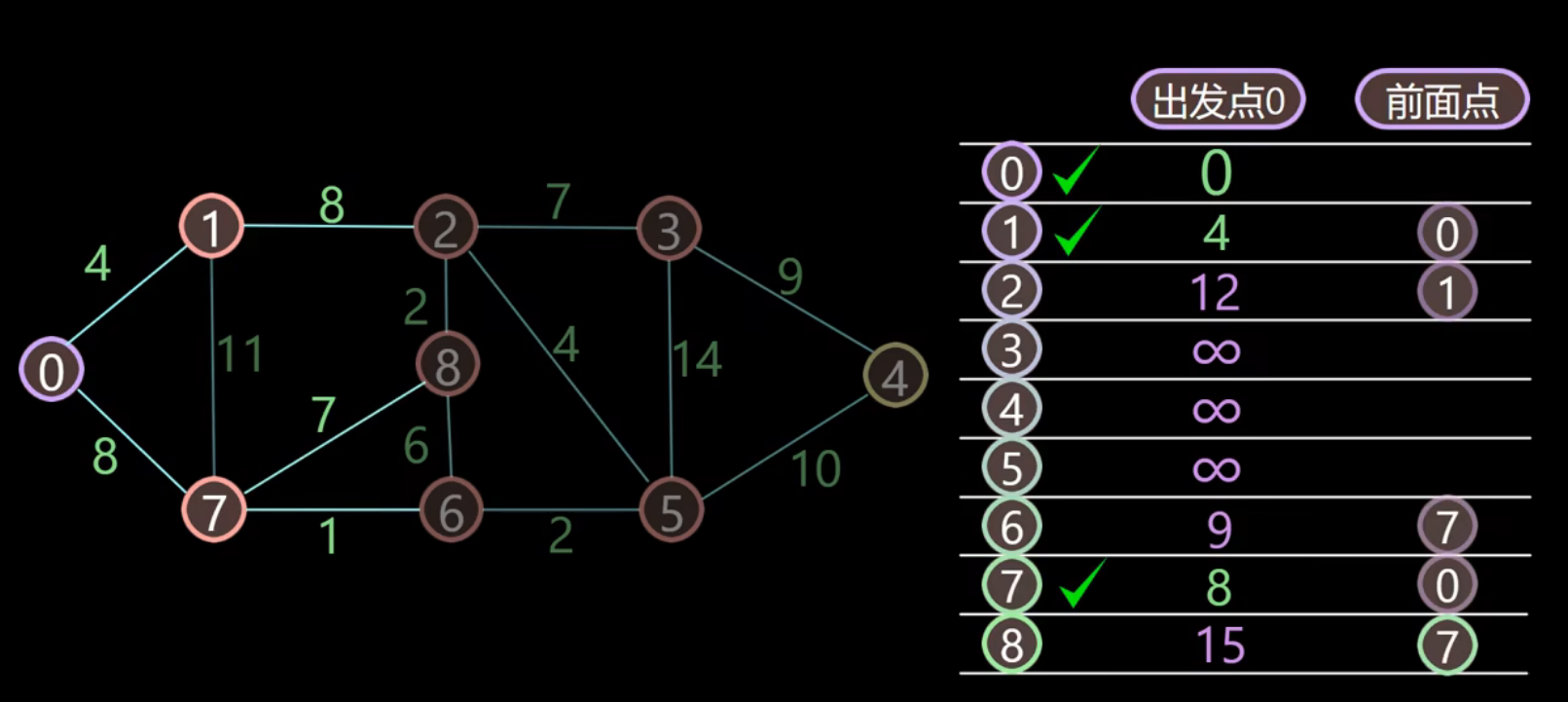
3、继续从未被标记的顶点中寻找距离更小的顶点,标记顶点7
- 计算与顶点7邻近的顶点8、6
- 对于顶点8来说,从顶点0 —》顶点7 —》顶点8,距离为 8+7=15 < ∞ ,因此更新
- 顶点6也是 同样的道理,8+1 = 9 < ∞,也要进行更新
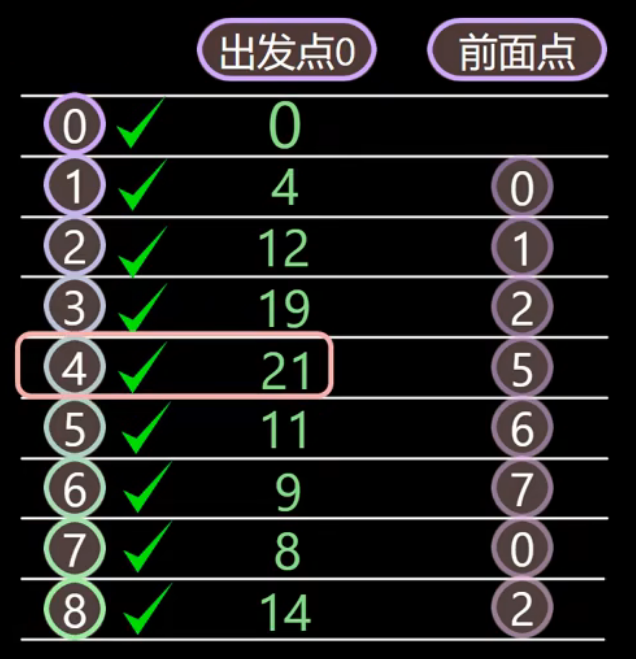
不断重复以上步骤,直到目的地被标记,得出最短距离为21:
走过的路径怎么找呢?
只需要找到每个结点的前驱顶点,然后倒序就可以了,比如:目的地顶点4的前驱为5, 顶点5的前驱为6,顶点6的前驱为7,顶点7的前驱为0,倒序为: 0 -- 7 -- 6 --5 -- 4
【算法步骤】
- 每次从未标记的顶点中
选择距离出发点最近的顶点,标记,收录到最优路径集合中 - 以上面选择的顶点为 “中间点”,若与之相邻的顶点经过 该"中间点"的距离变小了,就更新表格
- 重复上面步骤,知道目的地被标记!
代码实现
public class Graph {
public static void main(String[] args) {
AmGraph amGraph = new AmGraph(new Object[]{"v1", "v2", "v3", "v4", "v5", "v6"});
// 增加边
amGraph.addArc("v1", "v2", 6);
amGraph.addArc("v1", "v3", 1);
amGraph.addArc("v1", "v4", 5);
amGraph.addArc("v2", "v3", 5);
amGraph.addArc("v2", "v5", 3);
amGraph.addArc("v3", "v5", 6);
amGraph.addArc("v3", "v6", 4);
amGraph.addArc("v3", "v4", 5);
amGraph.addArc("v4", "v6", 2);
amGraph.addArc("v5", "v6", 6);
System.out.println(Arrays.deepToString(amGraph.arcs));
System.out.println("边的个数:" + amGraph.arcNum);
System.out.println("==============迪杰斯特拉=============");
amGraph.dijkstra(0);
}
}
/*
* 实现图的创建
* */
class AmGraph {
// 顶点集合
Object[] vexs;
// 保存邻接矩阵
Object[][] arcs;
// 记录边、顶点的个数
int vexNum;
int arcNum;
// 通过传入一个顶点数组进行初始化
public AmGraph(Object[] vexs) {
this.vexs = vexs;
this.vexNum = vexs.length;
this.arcs = new Object[vexs.length][vexs.length];
// 初始化邻接矩阵为∞
for (int i = 0; i < this.arcs.length; i++) {
Arrays.fill(arcs[i], Integer.MAX_VALUE);
}
}
/**
* @description 增加边
* @date 2024/4/22 11:00
* @param v1 顶点1
* @param v2 顶点2
* @param weight 权值
* @return void
*/
public void addArc(Object v1, Object v2, int weight) {
// 找到俩个顶点对应的下标
int v1Index = findArcIndex(v1, this.vexs);
int v2Index = findArcIndex(v2, this.vexs);
// 设置权值,由于是无向网,需要双向设置权值
this.arcs[v1Index][v2Index] = weight;
this.arcs[v2Index][v1Index] = weight;
this.arcNum++;
}
/**
* @description 找到顶点的下标
* @date 2024/4/22 11:01
* @param v1 顶点
* @param vexs 顶点集合
* @return int
*/
public int findArcIndex(Object v1, Object[] vexs) {
for (int i = 0; i < vexs.length; i++) {
if (vexs[i].equals(v1)) return i;
}
throw new RuntimeException("顶点不存在");
}
/**
* @description 迪杰斯特拉算法:某个点到目的地的距离
* @date 2024/4/22 22:22
* @param src
* @return void
*/
public void dijkstra(int src) {
// 保存源顶点到各个顶点的最短距离
int[] dist = new int[vexNum];
Arrays.fill(dist, Integer.MAX_VALUE);
// 保存每个顶点的前驱顶点
int[] pre = new int[vexNum];
Arrays.fill(pre, -1);
// 更新源点距离为0
dist[src] = 0;
// 标记顶点是否已经是最短路径
boolean[] isVisited = new boolean[vexNum];
for (int i = 0; i < vexs.length; i++) {
// 1、找到未被标记且距离源顶点最小的顶点,然后进行标记
// 假设minIndex对应的是顶点A的下标
int minIndex = findMinDist(dist, isVisited);
isVisited[minIndex] = true;
// 2、找出与当前顶点相邻的顶点,并更新 **相邻顶点** 距离以及前驱顶点
for (int j = 0; j < vexs.length; j++) {
if (
!isVisited[j] // 未被标记
&& (int) arcs[minIndex][j] != Integer.MAX_VALUE // 与顶点A相邻的顶点
&& dist[minIndex] + (int) arcs[minIndex][j] < dist[j] // 顶点A的距离 + 顶点A到顶点B的边 < 顶点B原本的距离
) {
pre[j] = minIndex;
dist[j] = dist[minIndex] + (int) arcs[minIndex][j];
}
}
}
for (int i = 0; i < vexs.length; i++) {
if (i != src){
System.out.println("从源顶点: " + vexs[src] + " 到顶点: " + vexs[i] + " 最短距离为: " + dist[i] + ", 路径为: ");
// 打印路径
printPath(pre,src,i);
System.out.println();
}
}
}
// 打印路径
private void printPath(int[] pre, int src, int dest) {
LinkedList<Integer> path = new LinkedList<>();
for (int at = dest; at != -1; at = pre[at]) {
path.addFirst(at);
}
StringJoiner sj = new StringJoiner("-->");
for (int v : path) {
sj.add(vexs[v]+"");
}
System.out.println(sj.toString());
}
/**
* @description 找到所有顶点中,未被标记并且距离最短的顶点
* @date 2024/4/22 22:34
* @param dist 保存了所有顶点距离源顶点的距离
* @param isVisited 标记顶点是否被访问
* @return int
*/
private int findMinDist(int[] dist, boolean[] isVisited) {
int minVal = Integer.MAX_VALUE;
int minIndex = -1;
for (int i = 0; i < vexs.length; i++) {
if (!isVisited[i] && dist[i] < minVal) {
minVal = dist[i];
minIndex = i;
}
}
return minIndex;
}
}
弗洛伊德(Floyd)
- 和Dijkstra算法一样,弗洛伊德(Floyd)算法也是一种用于寻找给定的加权图中顶点间最短路径的算法。
- 弗洛伊德算法(Floyd)计算图中
各个顶点之间的最短路径 - 迪杰斯特拉算法用于计算图中
某一个顶点到其他顶点的最短路径
算法思想
Floyd的算法思想很简单,就是以每个点都作为 “中心点”,然后去更新。
至于怎么更新、更新什么下面通过案例来说明!
【案例演示】
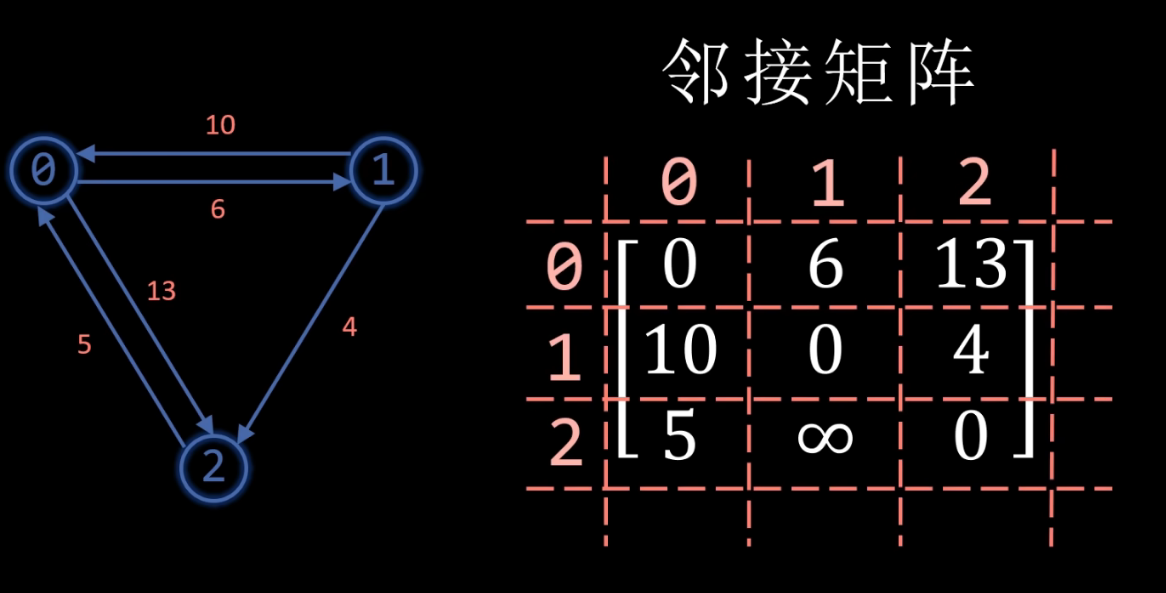
首先需要俩个二维数组 dist、path , dist 用来保存各顶点之间的距离,path 保存路径上终点的前驱顶点,初始化如下所示:

接下来就要以 每个顶点 作为中间点去更新,首先我们以顶点0为中间点:
- 更新过程中,凡是涉及到 自身顶点的都不需要去更新
- 例如:顶点0 — 经过顶点0 — 顶点2, 其实就是顶点0到顶点2,所以说经不经过顶点0没有意义
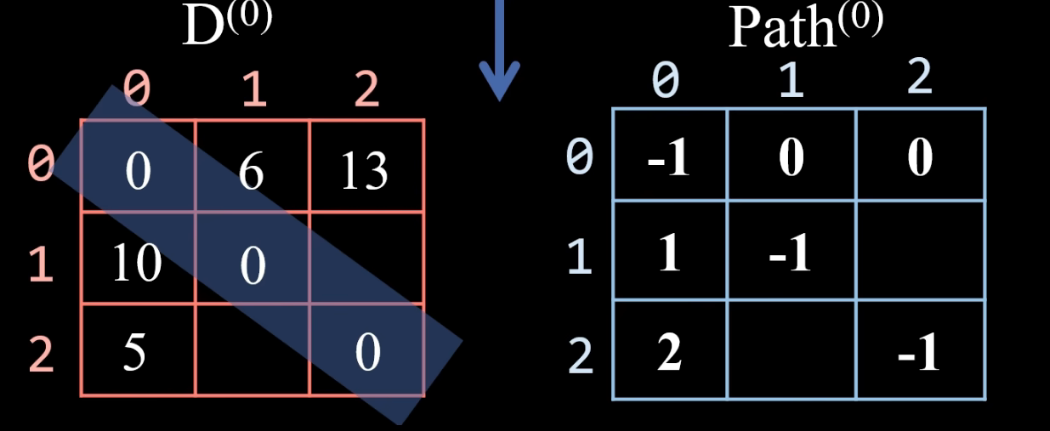
顶点1 经过 顶点0 到顶点2, 10 + 13 > 4 , 经过顶点0 比 不经过的距离还要长,因此不会更新
顶点2 经过 顶点0 到顶点1,5+6 < ∞,更新 dist表 距离为 dist[2][1] = 11,更新 path表 顶点1 的前驱为 pre[2][1] = pre[0][1] = 0
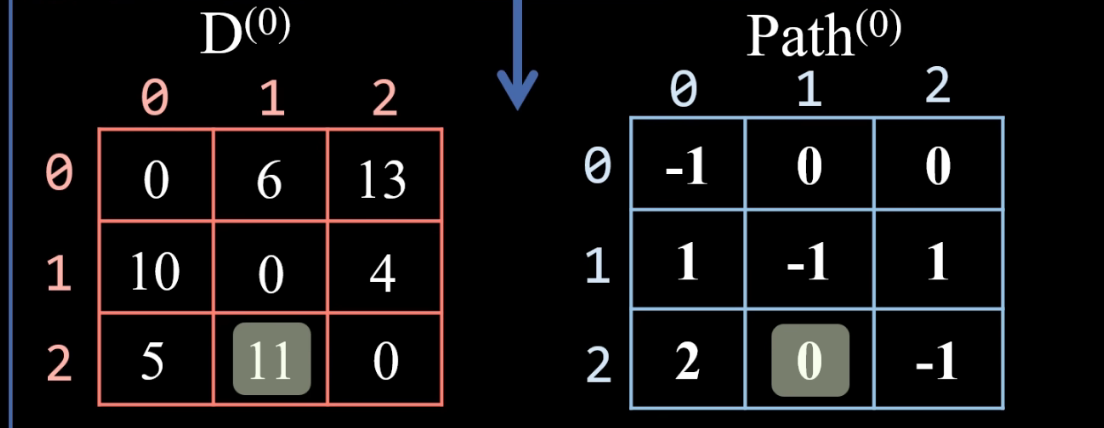
然后继续以这种方式,推算以顶点1、顶点2为中间点的情况!
代码实现
class AmGraph {
// 顶点集合
Object[] vexs;
// 保存邻接矩阵
Object[][] arcs;
// 记录边、顶点的个数
int vexNum;
int arcNum;
// 通过传入一个顶点数组进行初始化
public AmGraph(Object[] vexs) {
this.vexs = vexs;
this.vexNum = vexs.length;
this.arcs = new Object[vexs.length][vexs.length];
// 初始化邻接矩阵为∞
for (int i = 0; i < this.arcs.length; i++) {
Arrays.fill(arcs[i], Integer.MAX_VALUE);
}
}
/**
* @description 增加边
* @date 2024/4/22 11:00
* @param v1 顶点1
* @param v2 顶点2
* @param weight 权值
* @return void
*/
public void addArc(Object v1, Object v2, int weight) {
// 找到俩个顶点对应的下标
int v1Index = findArcIndex(v1, this.vexs);
int v2Index = findArcIndex(v2, this.vexs);
// 设置权值,由于是无向网,需要双向设置权值
this.arcs[v1Index][v2Index] = weight;
this.arcs[v2Index][v1Index] = weight;
this.arcNum++;
}
/**
* @description 找到顶点的下标
* @date 2024/4/22 11:01
* @param v1 顶点
* @param vexs 顶点集合
* @return int
*/
public int findArcIndex(Object v1, Object[] vexs) {
for (int i = 0; i < vexs.length; i++) {
if (vexs[i].equals(v1)) return i;
}
throw new RuntimeException("顶点不存在");
}
/**
* Floyd算法求各个点之间的最短距离
* */
// 执行佛洛依德算法
public void floyd() {
int V = arcs.length;
int[][] dist = new int[V][V]; // 存储任意两点间的最短距离
int[][] pred = new int[V][V]; // 存储路径的前驱顶点
// 初始化距离矩阵和前驱矩阵
for (int i = 0; i < V; i++) {
for (int j = 0; j < V; j++) {
dist[i][j] = (int) arcs[i][j];
if ((int) arcs[i][j] != Integer.MAX_VALUE && i != j) {
pred[i][j] = i;
} else {
pred[i][j] = -1; // 无前驱顶点
}
}
}
// 更新距离矩阵和前驱矩阵
for (int k = 0; k < V; k++) { // 中间点
for (int i = 0; i < V; i++) { // 出发点
for (int j = 0; j < V; j++) { // 终点
if (
dist[i][k] != Integer.MAX_VALUE
&& dist[k][j] != Integer.MAX_VALUE
&& dist[i][k] + dist[k][j] < dist[i][j]
) {
dist[i][j] = dist[i][k] + dist[k][j];
pred[i][j] = pred[k][j];
}
}
}
}
printFloyd(dist,pred);
}
// 打印最短路径
void printFloyd(int[][] dist, int[][] pred) {
int V = dist.length;
System.out.println("任意两点之间的最短路径距离矩阵:");
for (int i = 0; i < V; ++i) {
for (int j = 0; j < V; ++j) {
if (dist[i][j] == Integer.MAX_VALUE)
System.out.print("INF\t");
else
System.out.print(dist[i][j] + "\t");
}
System.out.println();
}
System.out.println("\n最短路径的前驱矩阵:");
for (int i = 0; i < V; ++i) {
for (int j = 0; j < V; ++j) {
if (pred[i][j] == -1)
System.out.print("NIL\t");
else
System.out.print(pred[i][j] + "\t");
}
System.out.println();
}
}
}
















 1023
1023











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











