







向导
1. ElasticSearch
1.下载
官方地址:https://www.elastic.co/cn/downloads/elasticsearch
历史版本:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
ES兼容性:https://www.elastic.co/cn/support/matrix
2.配置
- 上传服务器,解压
- 修改用户(不允许使用root用户)
- 增加系统配置:
- 禁用内存交换,内存交换会导致ES节点不稳定,会影响GC的工作效率,从而导致节点无法响应
# 系统层面,临时
sudo swapoff -a
# 系统层面,永久,修改/etc/fstab文件
#应用层面
bootstrap.memory_lock: true
# 修改 /etc/security/limits.conf
# allow user 'elasticsearch' mlockall
echo "elastic hard memlock unlimited" >> /etc/security/limits.conf
echo "elastic soft memlock unlimited" >> /etc/security/limits.conf
# 增加文件句柄和确保能创建足够的线程
# 修改文件 /etc/security/limits.conf
# elasticsearch用户最多可以使用65535个文件
echo "elastic soft nofile 65536" >> /etc/security/limits.conf
echo "elastic hard nofile 65536" >> /etc/security/limits.conf
# elasticsearch用户最多可以使用4096个线程
echo "elastic soft nproc 4096" >> /etc/security/limits.conf
echo "elastic hard nproc 4096" >> /etc/security/limits.conf
# 或者编辑 vi /etc/security/limits.conf
elastic hard memlock unlimited
elastic soft memlock unlimited
elastic soft nofile 65536
elastic hard nofile 65536
elastic soft nproc 4096
elastic hard nproc 4096
- 增加系统配置
echo "vm.max_map_count = 262144">> /etc/sysctl.conf
sysctl -p
- 创建数据和日志目录:
cd /data/services/elasticsearch-7.17.5
mkdir logs
mkdir data
- 修改配置文件:
vi config/elasticsearch.yml
# 增加如下配置:
#配置es的集群名称,同一个集群中的多个节点使用相同的标识
#如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
cluster.name: my-es-cluster
#节点名称(每个节点不一样)
node.name: node-a
#是不是有资格竞选主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#数据存储路径
path.data: /data/services/elasticsearch-7.17.5/data
#日志存储路径
path.logs: /data/services/elasticsearch-7.17.5/logs
#节点所绑定的IP地址,并且该节点会被通知到集群中的其他节点
#通过指定相同网段的其他节点会加入该集群中 0.0.0.0任意IP都可以访问elasticsearch(每个节点不一样)
network.host: 192.168.3.21
#对外提供服务的http端口,默认为9200
http.port: 9200
#内部节点之间沟通端口
transport.tcp.port: 9300
#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["192.168.3.21","192.168.3.22","192.168.3.23"]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-a", "node-b","node-c"]
#ES默认开启了内存地址锁定,为了避免内存交换提高性能。但是Centos6不支持SecComp功能,启动会报错,所以需要将其设置为false
bootstrap.memory_lock: false
# 是否支持跨域
http.cors.enabled: true
# *表示支持所有域名
http.cors.allow-origin: "*"
- 修改jvm.options,官网建议最大不超过32G
-Xms4g
-Xmx30g
- 拷贝上述配置,将需要修改的 node.name,network.host 修改
- 切换用户,启动:
#控制台启动命令
bin/elasticsearch
#后台启动命令
#bin/elasticsearch -d
3.查看启动状态
curl 'http://localhost:9201/_cat/nodes?v'
4.注册宕机、开机自启
- 创建配置文件:vim /usr/lib/systemd/system/elasticsearch.service
- 填写监控信息:
[Unit]
Description=elasticsearch
After=network.target
[Service]
Type=forking
User=hadoop
ExecStart=/data/services/elasticsearch-7.17.5/bin/elasticsearch -d
PrivateTmp=true
# 指定此进程可以打开的最大文件数
LimitNOFILE=65535
# 指定此进程可以打开的最大进程数
LimitNPROC=65535
# 最大虚拟内存
LimitAS=infinity
# 最大文件大小
LimitFSIZE=infinity
# 超时设置 0-永不超时
TimeoutStopSec=0
# SIGTERM是停止java进程的信号
KillSignal=SIGTERM
# 信号只发送给给JVM
KillMode=process
# java进程不会被杀掉
SendSIGKILL=no
# 正常退出状态
SuccessExitStatus=143
[Install]
WantedBy=multi-user.target
- 使用
systemctl daemon-reload命令可以刷新elasticsearch.service配置信息 - 设置开机启动:
systemctl enable elasticsearch.service - 其他相关命令:
# 查看服务
systemctl status elasticsearch.service
# 启动服务
systemctl start elasticsearch.service
# 重启服务
systemctl restart elasticsearch.service
# 停止服务
systemctl stop elasticsearch.service
# 禁止开机启动
systemctl disable elasticsearch.service
# 启用开机启动
systemctl enable elasticsearch.service
5.如果磁盘是SSD,建议修改IO调度算法
- 查看操作系统版本
cat /etc/debian_version

- 查看支持的io调度算法
sudo dmesg |grep -i scheduler

- 查看磁盘:
lsblk

- 查看默认的调度算法
cat /sys/block/vdb/queue/scheduler

- 修改为noop调度算法:
sudo echo noop > /sys/block/vdb/queue/scheduler
6.SSD磁盘,关闭numa绑核、hugepage
sudo vi /etc/default/grub,添加如下配置
GRUB_CMDLINE_LINUX_DEFAULT="quiet numa=off transparent_hugepage=never"
- 保存,更新配置,重启机器
sudo grub-mkconfig -o /boot/grub/grub.cfg
sudo reboot
2. Kibana
1.下载
官方地址:https://www.elastic.co/cn/downloads/past-releases#kibana
2.配置
#2.解压
tar -zvxf kibana-7.17.5-linux-x86_64.tar.gz
#3.修改配置文件 config/kibana.yml
server.port: 5601
server.host: "xx"
elasticsearch.hosts: ["http://xx1:9200","http://xx2:9200","http://xx3:9200"]
elasticsearch.username: "elastic"
elasticsearch.password: "pwd123"
#4. 启动
nohup /data/services/kibana-7.17.5/bin/kibana >> /data/services/kibana-7.17.5/logs/kibana.log 2>&1 &
#5. 查验启动后运行结果
ps -ef | grep kibana
#浏览器访问 http://xx:5601
3.ElasticSearch-head插件
1.下载
官方地址:https://github.com/mobz/elasticsearch-head
2.安装和配置
- 安装node:安装node
- 安装head:
unzip elasticsearch-head-5.0.0.zip
cd elasticsearch-head-5.0.0
npm config set registry https://registry.npm.taobao.org
npm install --ignore-scripts
- 修改_site/app.js,修改es的链接地址(在4354行),改为ES的IP(一台即可)

- 修改_site/vendor.js文件,将x-www-form-urlencoded改为json;charset=UTF-8:
# 6886行
contentType: "application/x-www-form-urlencoded"
# 改成
contentType: "application/json;charset=UTF-8"
# 7574行
var inspectData = s.contentType === "application/x-www-form-urlencoded" &&
# 改成
var inspectData = s.contentType === "application/json;charset=UTF-8" &&
- 修改Gruntfile.js 文件,在 connect下的options 属性内增加 hostname,设置为该机器的ip:

3.启动和测试
- 启动:
nohup npm run start >> logs/head.log 2>&1 &
- 打开网页测试:http://xxx:9400
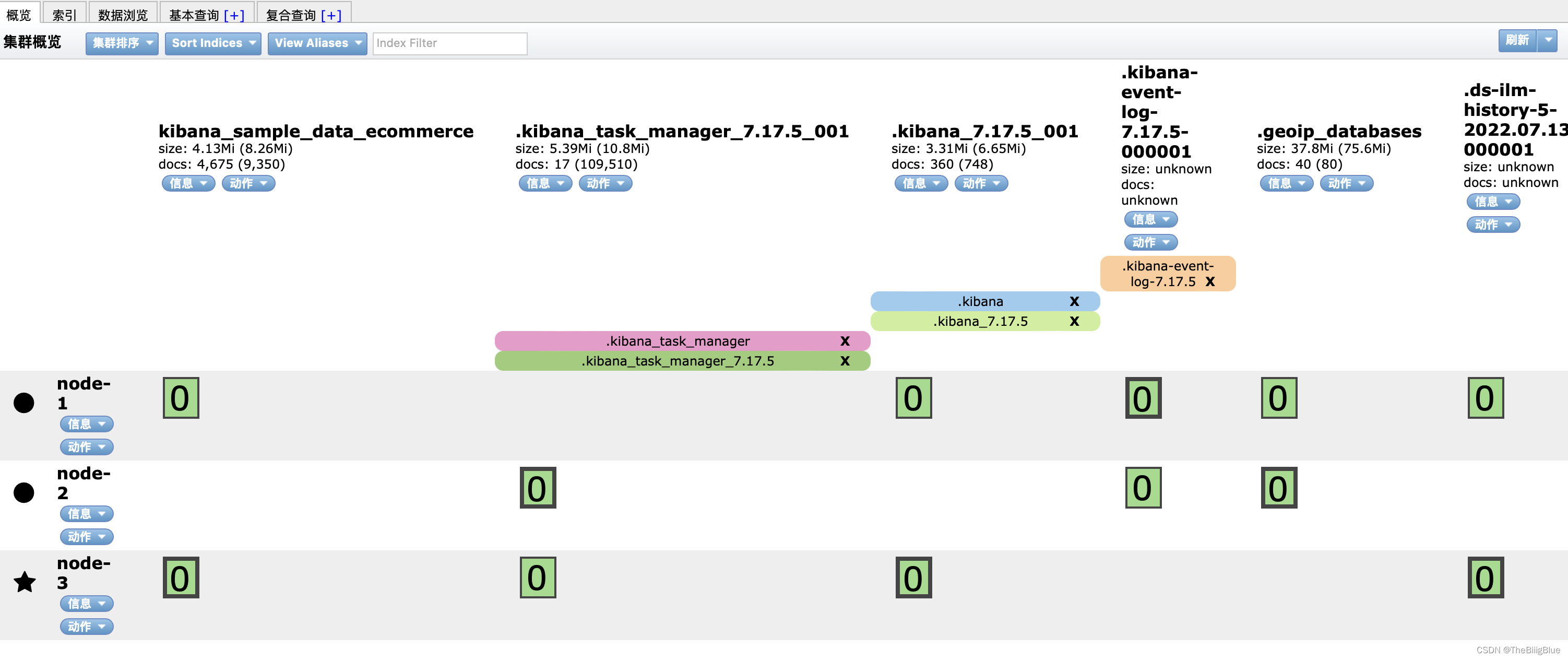
4.ik 分词器插件
1.下载
官方地址:https://github.com/medcl/elasticsearch-analysis-ik
注意:需要下载和ES版本一致的插件,在ES中安装IK插件的时候,需要在ES集群的所有节点中都安装
2.安装和配置
在每个节点本地安装:
bin/elasticsearch-plugin install file:///data/soft/elasticsearch-7.17.5/elasticsearch-analysis-ik-7.17.5.zip
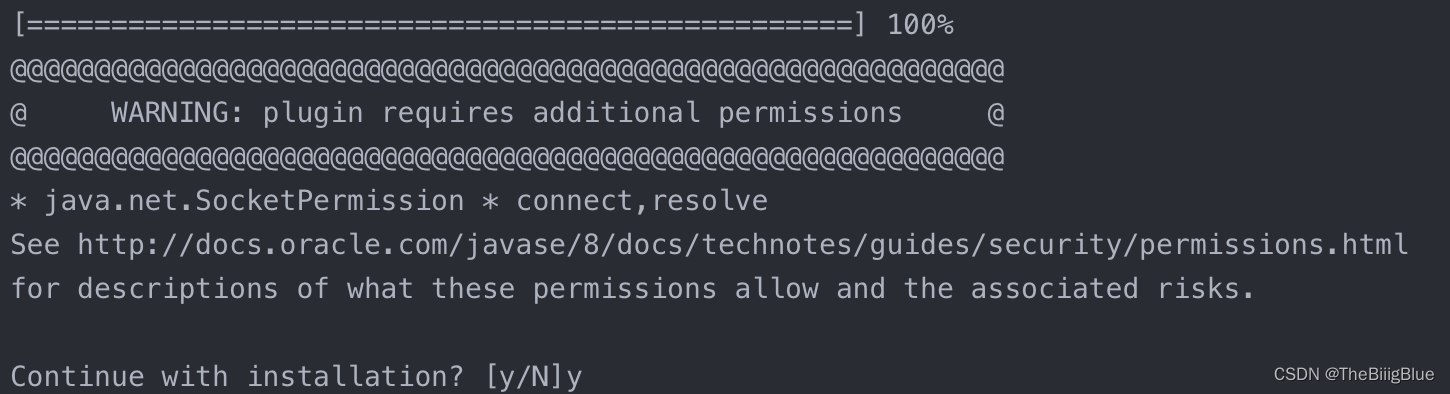
注意:在安装的过程中会有警告信息提示需要输入y确认继续向下执行:
最后看到如下内容就表示安装成功了:

注意:插件安装成功之后在elasticsearch-7.17.5的config和plugins目录下会产生一个analysis-ik目录。
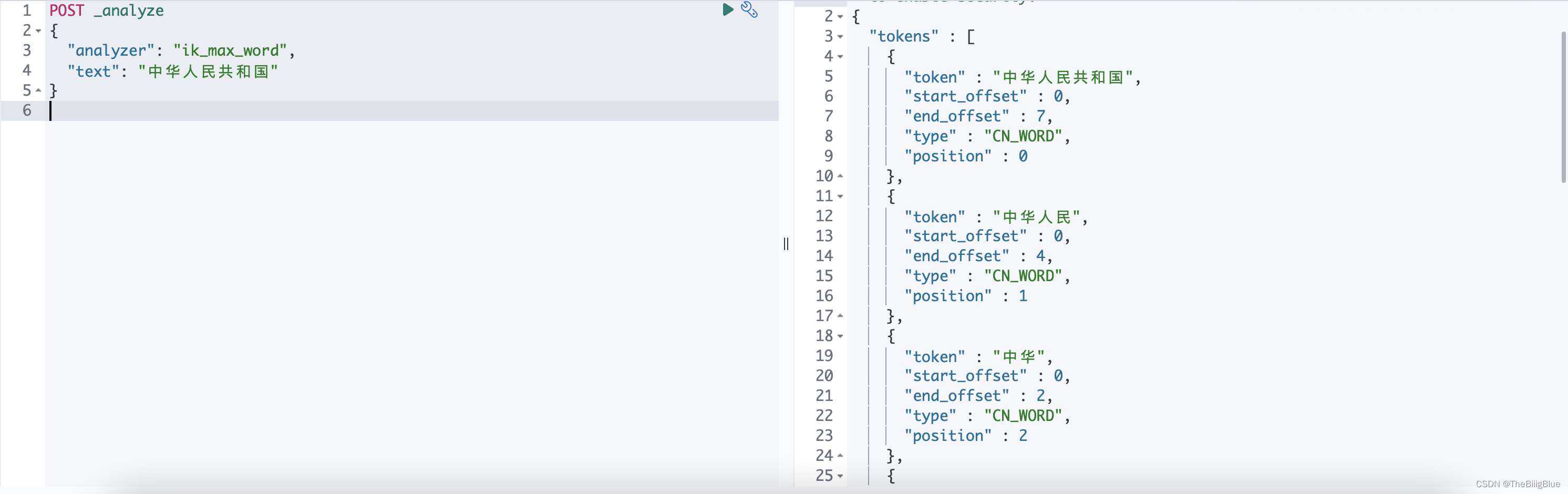
重启集群,kibana dev tools 测试:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国"
}
5.pinyin 分词器插件
1.下载
官方地址:https://github.com/medcl/elasticsearch-analysis-pinyin/releases?page=2
注意:下载和ES版本一致的插件,在ES中安装插件的时候,需要在ES集群的所有节点中都安装
2.安装和配置
在每个节点本地安装:
bin/elasticsearch-plugin install file:///data/services/elasticsearch-7.17.5/elasticsearch-analysis-pinyin-7.17.5.zip
最后看到如下内容就表示安装成功了:

注意:插件安装成功之后在elasticsearch-7.17.5的plugins目录下会产生一个analysis-pinyin目录。
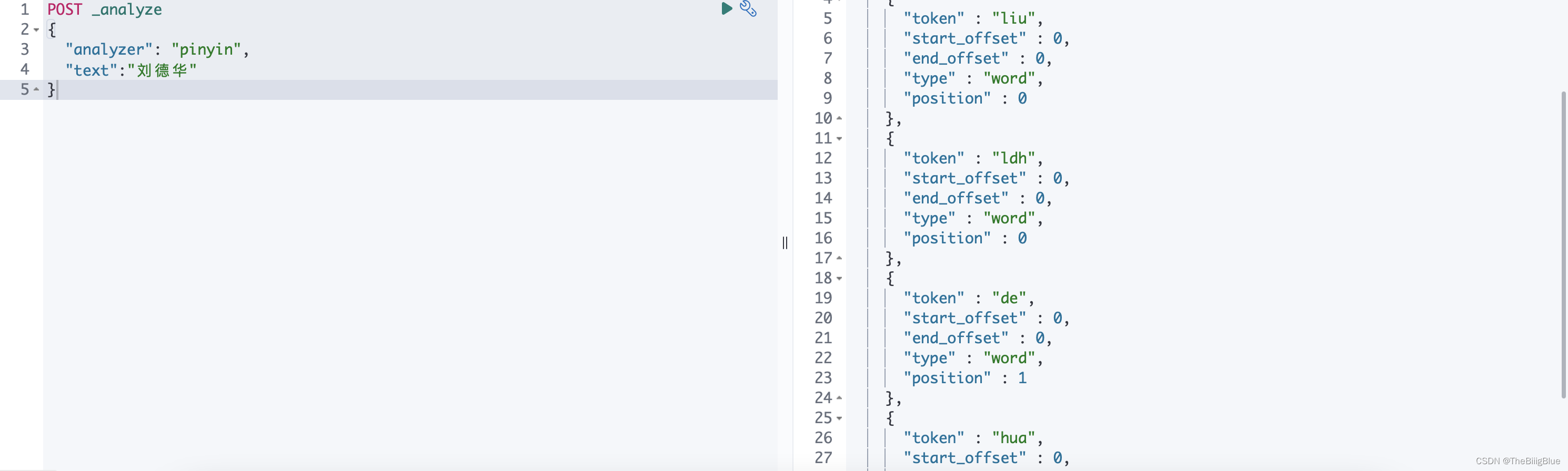
重启集群,kibana dev tools 测试:
POST _analyze
{
"analyzer": "pinyin",
"text":"刘德华"
}














 577
577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









