







1.Spark 集成 Hudi
1.1 pom
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<scope>${scope.default}</scope>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-spark3.2-bundle_2.12</artifactId>
</dependency>
1.2 代码
import org.apache.hudi.DataSourceWriteOptions
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.current_timestamp
object TestSparkHudi {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder
.master("local[4]").config("spark.driver.host", "127.0.0.1")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.hudi.catalog.HoodieCatalog")
.config("spark.sql.extensions", "org.apache.spark.sql.hudi.HoodieSparkSessionExtension")
.appName("Test").getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val input = "data/input/cdc-json.txt"
val output = "data/output"
//写入hudi
val df = spark.read.json(input).withColumn("ts", current_timestamp())
df.show()
df.write.format("hudi")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD.key(), "ts")
.option(DataSourceWriteOptions.RECORDKEY_FIELD.key(), "id")
// .option(DataSourceWriteOptions.PARTITIONPATH_FIELD.key(), "partitionpath")
// .option(DataSourceWriteOptions.TABLE_NAME.key(), "central_gov")
.option("hoodie.table.name", "central_gov")
.option(DataSourceWriteOptions.OPERATION.key(), "upsert")
.mode("overwrite")
.save(output)
//读取hudi
val tripsSnapshotDF = spark.read.format("hudi").load(output)
tripsSnapshotDF.show()
spark.close()
}
}
2.Spark集成Hudi同步Hive
2.1 pom
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-spark3.2-bundle_2.12</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>3.1.3</version>
</dependency>
2.2 代码
package cc.icourt.test
import org.apache.hudi.DataSourceWriteOptions
import org.apache.hudi.common.table.HoodieTableConfig
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.{col, current_timestamp}
import java.util.Properties
object TestSparkHudiHive {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder
.master("local[4]").config("spark.driver.host", "127.0.0.1")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.appName("Test").getOrCreate()
spark.sparkContext.setLogLevel("WARN")
//写入hudi
val input = "file:///data/input/cdc-json.txt"
//必须是hdfs路径
val output = "/data/spark/output"
//写入hudi
val df = spark.read.json(input).withColumn("ts", current_timestamp())
df.show()
df.write.format("hudi")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD.key(), "ts")
.option(DataSourceWriteOptions.RECORDKEY_FIELD.key(), "id")
// .option(DataSourceWriteOptions.PARTITIONPATH_FIELD.key(), "partitionpath")
// .option(DataSourceWriteOptions.TABLE_NAME.key(), "central_gov")
.option("hoodie.index.type","SIMPLE")
.option("hoodie.datasource.write.hive_style_partitioning","true")
.option("hoodie.datasource.hive_sync.jdbcurl","jdbc:hive2://172.16.75.101:10000/")
.option("hoodie.datasource.hive_sync.username","hadoop")
.option("hoodie.datasource.hive_sync.database","default")
.option("hoodie.datasource.hive_sync.table","hudi_test")
// .option("hoodie.datasource.hive_sync.partition_fields","partitionId")
.option("hoodie.datasource.hive_sync.enable","true")
.option("hoodie.table.name", "central_gov")
.option(DataSourceWriteOptions.OPERATION.key(), "upsert")
.mode("overwrite")
.save(output)
spark.close()
}
}
2.3 报错
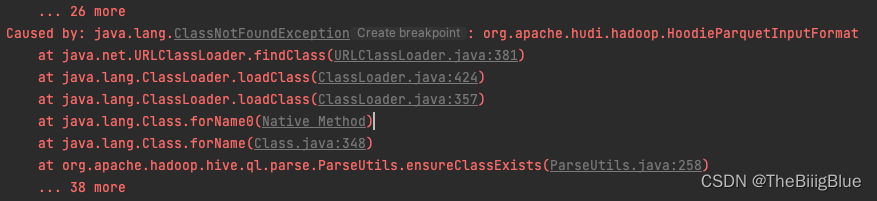
由于hudi未和hive集成,向hive写hudi表报错,如果是hudi不需要同步hive(spark直接写hudi,然后手动hive建表,那可以不集成hive),但是想写入hudi的时候在hive上自动建表就需要集成hive
Caused by: org.apache.hadoop.hive.ql.parse.SemanticException: Cannot find class 'org.apache.hudi.hadoop.HoodieParquetInputFormat'
at org.apache.hadoop.hive.ql.parse.ParseUtils.ensureClassExists(ParseUtils.java:260)
at org.apache.hadoop.hive.ql.parse.StorageFormat.fillStorageFormat(StorageFormat.java:57)
at org.apache.hadoop.hive.ql.parse.SemanticAnalyzer.analyzeCreateTable(SemanticAnalyzer.java:13004)
at org.apache.hadoop.hive.ql.parse.SemanticAnalyzer.genResolvedParseTree(SemanticAnalyzer.java:11974)
at org.apache.hadoop.hive.ql.parse.SemanticAnalyzer.analyzeInternal(SemanticAnalyzer.java:12129)
at org.apache.hadoop.hive.ql.parse.CalcitePlanner.analyzeInternal(CalcitePlanner.java:330)
at org.apache.hadoop.hive.ql.parse.BaseSemanticAnalyzer.analyze(BaseSemanticAnalyzer.java:285)
at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:659)
at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:1826)
at org.apache.hadoop.hive.ql.Driver.compileAndRespond(Driver.java:1773)
at org.apache.hadoop.hive.ql.Driver.compileAndRespond(Driver.java:1768)
at org.apache.hadoop.hive.ql.reexec.ReExecDriver.compileAndRespond(ReExecDriver.java:126)
at org.apache.hive.service.cli.operation.SQLOperation.prepare(SQLOperation.java:197)
... 26 more
Caused by: java.lang.ClassNotFoundException: org.apache.hudi.hadoop.HoodieParquetInputFormat
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.hadoop.hive.ql.parse.ParseUtils.ensureClassExists(ParseUtils.java:258)
... 38 more
3.Hudi集成Hive
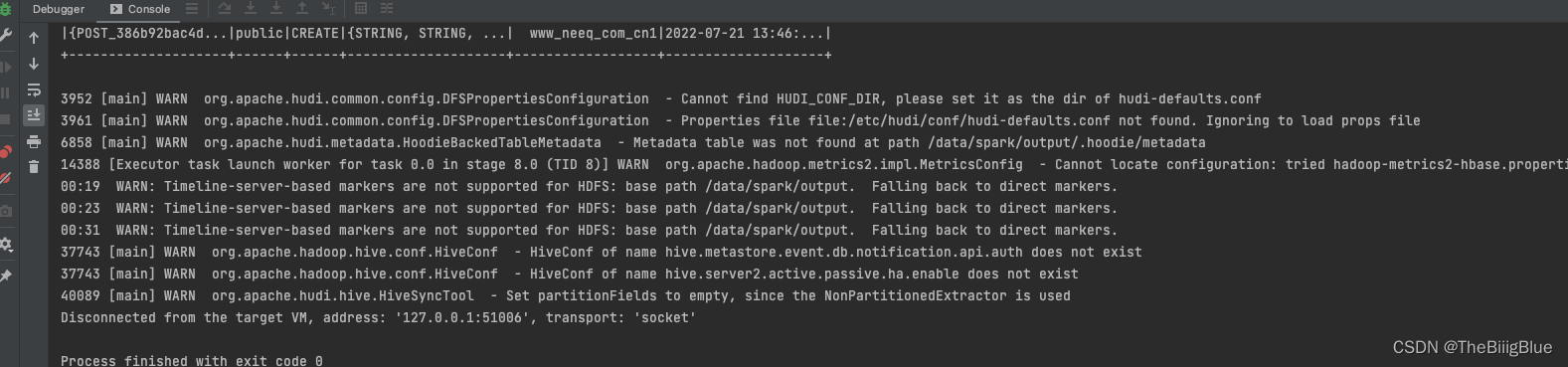
- 将 hudi-hadoop-mr-bundle-0.11.1.jar 添加到hive/lib目录下, 重启hive metastore和hiveserver2
- 重新执行代码















 2717
2717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









