






 本文介绍如何在Scrapy中使用Selenium实现模拟登录知乎的过程,并获取cookies以供后续爬虫请求使用。
本文介绍如何在Scrapy中使用Selenium实现模拟登录知乎的过程,并获取cookies以供后续爬虫请求使用。
如何在scrapy中使用selenium完成模拟登陆,获取cookie
以下以模拟登陆知乎为例,讲解思路
一.入口方法
在爬虫类中有一个入口方法,如下:
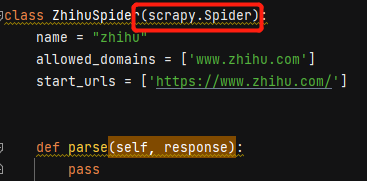
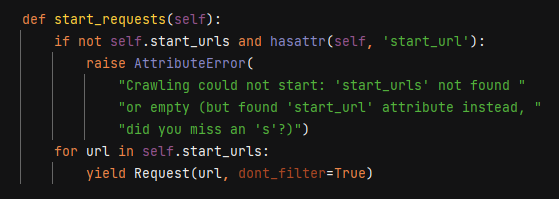
这个start_requests()方法的作用是将start_urls中的url给Request对象去下载.
只要重写这个方法,就可以完成入口控制,每次启动scrapy之前使用selenium完成模拟登陆;
二.使用浏览器驱动控制当前打开的浏览器实例
但用上面所讲的思路来模拟登陆会出现如下问题
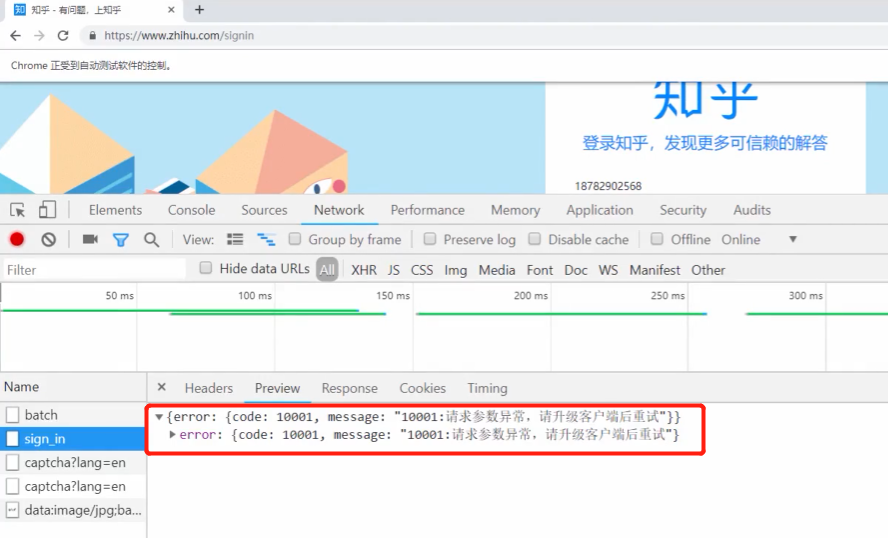
这是因为Chrome的driver被知乎给识别了,无法使用selenium模拟登陆,这如何解决呢
解决方法: 手动启动chrome,让drive去控制当前的chrome
第一步:在cmd命令行中cd到chrome安装目录下,
输入:chrome.exe --remote-debugging-port=9222(前提:需要关闭chrome浏览器)
第二步:验证
打开浏览器窗口,输入127.0.0.1:9222/json
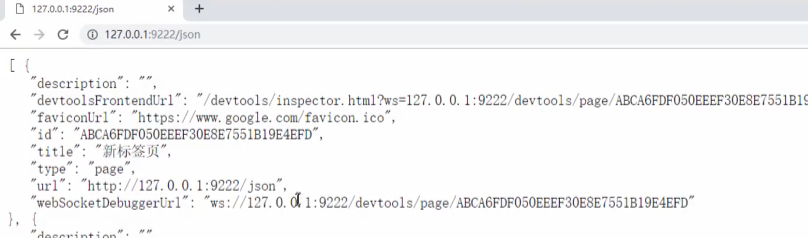
第三步:start_requests()方法中使用如下代码控制当前chrome实例
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--disable-extensions")
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
browser = webdriver.Chrome(executable_path="E:/chromedriver/chromedriver_win32/chromedriver.exe",
chrome_options=chrome_options)
第四步:这里还会出现一个问题:直接使用chromedrive打开的浏览器窗口是纯净的,不包含cookies
如果直接控制手动打开的chrome,就含有cookies,此时如果使用selenium方法输入用户名密码时,浏览器会自动输入缓存下来的用户名密码,导致账号密码输入了两次.可以用如下小技巧 解决
from selenium.webdriver.common.keys import Keys
browser.find_element_by_css_selector(".SignFlow-accountInput.Input-wrapper input").send_keys(Keys.CONTROL + "a")
browser.find_element_by_css_selector(".SignFlow-accountInput.Input-wrapper input").send_keys("1878XXXX568")
第五步:在使用selenium方法点击登陆的时候,发现click()方法无法使用.于是我用了另外一种方式来实现
python里面有一个库叫mouse,可以很随意的操纵鼠标
pip install mouse
from mouse import move,click
move(895,604)
click()
三.获取/使用cookies
selenium登陆后,拿到所有的cookies,将cookies写到文件中
def start_requests(self):
#...此处为selenium模拟登陆的代码
cookies = browser.get_cookies()
import pickle
pickle.dump(cookies,open("","wb")) #将cookies写到文件中
cookie_dict = {} #将cookies放到字典中
for cookie in cookies:
cookie_dict[cookie["name"]]=cookie["value"]
#拦截了入口方法后,需要return回去,保证程序可以继续进行
return [scrapy.Request(url=self.start_url[0],dont_filter=True,cookies=cookie_dict)]
另外,settings.py里面这几个设置要注意下
COOKIES_ENABLED = True #后续所有的请求不需要手动加cookie,会自动从上一个Requests去取cookie
COOKIES_DEGUB = True
USER_AGENT = '...'
既然把cookie写到了文件里面,则第二次运行就不需要模拟登陆来取cookie,则只需从文件中读取即可(会遇到cookies失效的情况,后续讲)
def start_requests(self):
...
cookies = pickle.load(open("",rb))
cookie_dict = {}
for cookie in cookies:
cookie_dict[cookie["name"]]=cookie["value"]
#拦截了入口方法后,需要return回去,保证程序可以继续进行
return [scrapy.Request(url=self.start_url[0],dont_filter=True,cookies=cookie_dict)]
本文由 mdnice 多平台发布


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









