






主题一:反爬
为什么爬虫不用太担心禁止IP的反爬方法(顶多封几个小时IP,我们也有对应的方案),原因如下:
1.比方说一个学校/网吧,对外的IP只有一个或者几个,大家都通过局域网对外访问,如果因为学校里面的学生写了一个爬虫而把公网IP封了,那么整个学校1万多人都无法访问该的网站,损失量巨大
2.IP是动态分配的,如果将IP禁止访问,当把此IP分配给其他"无辜的人"时,他就无法登陆你的网站
信心来源:理论上,网站是不可能从技术上禁止爬虫,最后肯定是爬虫获胜的 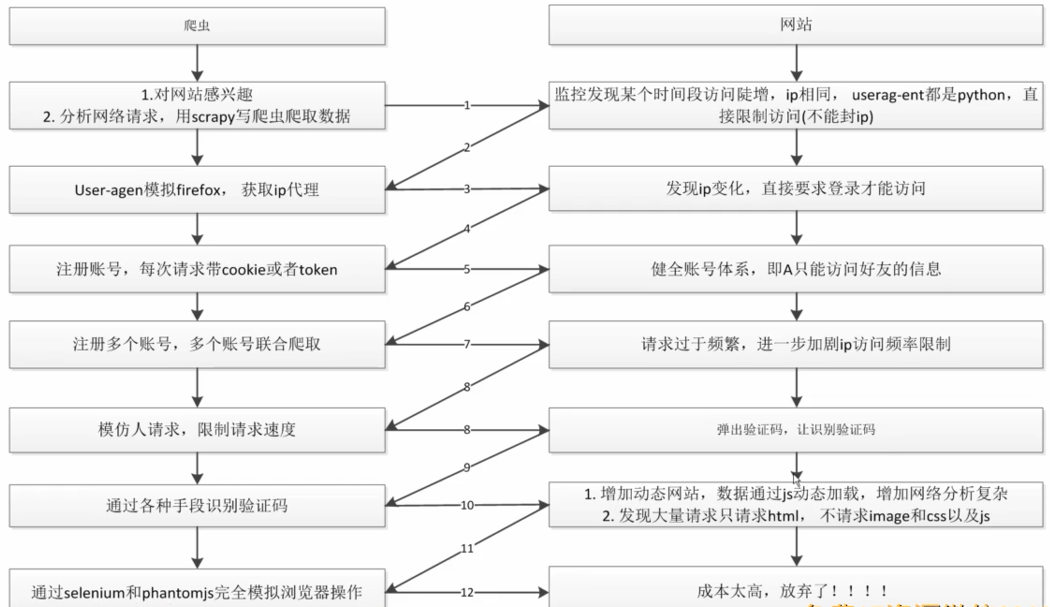
主题二:scrapy架构图
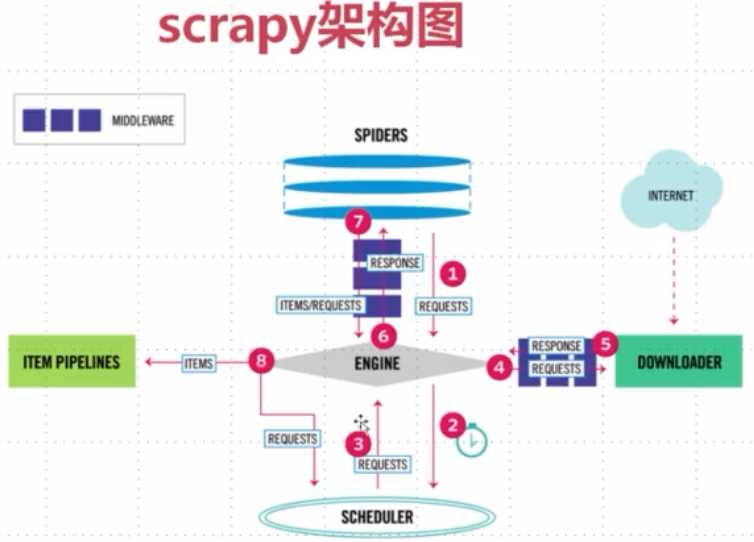
看图中的序号和主件。
-
SPIDER:爬虫;1.用于yield出各个请求;2.定义回调函数处理请求下载的response,提取数据;3.对应提取出来的数据yield出item
-
ENGINE:引擎,理解成调度机制(大总管),当序号1来的请求进入到ENGINE,就会被识别为请求并经过序号2被放到调度器中。
-
SCHEDULER:调度器,涉及爬取顺序:队列(广度优先)、堆栈(深度优先),将准备好的请求一个个丢给ENGINE(序号3)
-
DOWNLOADER:下载器,下载网页内容。途径4和5是下载中间件,对请求和响应做拦截,比如对请求统一的加头、加代理或者集成selenium自己爬取。经过序号5回到ENGINE中,被ENGINE识别为响应,就回到SPIDERS中做解析。
-
ITEM PIPELINES:管道,负责数据的清洗和入库
主题三:针对反"反爬"的几个注意点
1.如何随机的更换user-agent(用户-代理)
首先,scrapy提供了一个默认的UserAgentMiddleware(源码),用于从配置文件中读取USER_AGENT,给request的请求头设置上
但是如果老是用同一个USER_AGENT去爬,则很容易被反爬,所以有了更换请求头的中的USER_AGENT。
要使用我们自己的中间件来实现随机变换user-agent,就需要将scrapy默认的这个中间件置为None,并配置上自己写的middlewares.

具体如下:在scrapy项目新建之初,项目目录下就有一个middlewares.py的文件用于编写自定义的中间件。
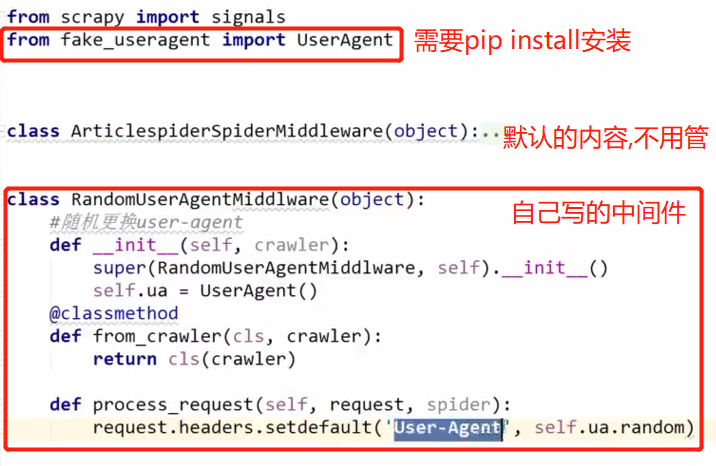
process_request()请求来的时候做拦截,它有三种类型的返回值
-
return none:程序继续往后执行 -
return response对象:不走downloader,直接把响应对象返回给engine,然后给spider做解析 -
return request对象:不走downloader,直接把请求对象返回给engine,然后丢到调度器中排序继续来发请求 -
raise异常:流程转到process_exception方法中处理(常用于拦截不需要下载的url)
#request.headers是一个Headers对象,继承至字典
print(type(request.headers))
print(request.headers)
from scrapy.http.headers import Headers
# 给USER_AGENT随机换值,也可以这么写
request.headers['User-Agent']='UserAgent().random'
2.IP的变化方案:设置IP代理
在刚刚上面的中间件的process_request()末尾加上代理,语句就一句,如下:
request.meta["proxy"] = 'http://IP地址:端口'
但是不能只用1个IP,而需要一个IP代理池
百度中搜索IP代理,将高匿的IP代理爬取下来放在数据库中,每次随机取一条即可,专门写一个工具来处理,如下:
import requests
from scrapy.selector import Selector
import MySQLdb
conn = MySQLdb.connect(host="127.0.0.1", user="root", passwd="root", db="article_spider", charset="utf8")
cursor = conn.cursor()
def crawl_ips():
#爬取西刺的免费ip代理
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0"}
for i in range(1568):
re = requests.get("http://www.xicidaili.com/nn/{0}".format(i), headers=headers)
selector = Selector(text=re.text)
all_trs = selector.css("#ip_list tr")
ip_list = []
for tr in all_trs[1:]:
speed_str = tr.css(".bar::attr(title)").extract()[0]
if speed_str:
speed = float(speed_str.split("秒")[0])
all_texts = tr.css("td::text").extract()
ip = all_texts[0]
port = all_texts[1]
proxy_type = all_texts[5]
ip_list.append((ip, port, proxy_type, speed))
for ip_info in ip_list:
cursor.execute(
"insert proxy_ip(ip, port, speed, proxy_type) VALUES('{0}', '{1}', {2}, 'HTTP')".format(
ip_info[0], ip_info[1], ip_info[3]
)
)
conn.commit()
class GetIP(object):
def delete_ip(self, ip):
#从数据库中删除无效的ip
delete_sql = """
delete from proxy_ip where ip='{0}'
""".format(ip)
cursor.execute(delete_sql)
conn.commit()
return True
def judge_ip(self, ip, port):
#判断ip是否可用
http_url = "http://www.baidu.com"
proxy_url = "http://{0}:{1}".format(ip, port)
try:
proxy_dict = {
"http":proxy_url,
}
response = requests.get(http_url, proxies=proxy_dict)
except Exception as e:
print ("invalid ip and port")
self.delete_ip(ip)
return False
else:
code = response.status_code
if code >= 200 and code < 300:
print ("effective ip")
return True
else:
print ("invalid ip and port")
self.delete_ip(ip)
return False
def get_random_ip(self):
#从数据库中随机获取一个可用的ip
random_sql = """
SELECT ip, port FROM proxy_ip
ORDER BY RAND()
LIMIT 1
"""
result = cursor.execute(random_sql)
for ip_info in cursor.fetchall():
ip = ip_info[0]
port = ip_info[1]
judge_re = self.judge_ip(ip, port)
if judge_re:
return "http://{0}:{1}".format(ip, port)
else:
return self.get_random_ip()
# print (crawl_ips())
if __name__ == "__main__":
get_ip = GetIP()
get_ip.get_random_ip()
改为加上这句request.meta["proxy"] = GetIP().get_random_ip()
github上scrapy-proxies,scrapy-crawlera有时间可以去了解下
tor 洋葱浏览器,经过洋葱网络后,自己的IP会被隐藏,其稳定性会比收费的IP代理还稳定一些,也可以去了解下
3.scrapy中集成selenium
middlewares.py中新建一个中间件类JSPageMiddleware,将其配置到settings中的DOWNLOAD_MIDDLEWARES
from selenium import webdriver
from scrapy.http import HtmlResponse
class JSPageMiddleware(object):
#通过chrome请求动态网页
def process_request(self, request, spider):
if spider.name == "jobbole":
browser = webdriver.Chrome(executable_path="D:/Temp/chromedriver.exe")
browser.get(request.url)
import time
time.sleep(3)
print ("访问:{0}".format(request.url))
return HtmlResponse(url=browser.current_url, body=browser.page_source, encoding="utf-8", request=request)
-
process_request中return response对象:不走downloader不去下载,直接把响应对象返回给engine,然后给spider做解析
但是这样每次运行到中间件都会启动一个chrome,不合理,如下演变:
在JSPageMiddleware中间件类中添加一个构造函数__init__(),将browser作为对象属性,在初始化的时候给其赋值,变成这样:
class JSPageMiddleware(object):
def __init__(self):
self.browser=webdriver.Chrome(executable_path="")
super().__init__()
def process_request(self, request, spider):
if spider.name == "jobbole":
self.browser.get(request.url)
import time
time.sleep(3)
print ("访问:{0}".format(request.url))
return HtmlResponse(url=self.browser.current_url, body=self.browser.page_source, encoding="utf-8", request=request)
这种方式也存在问题: 当爬虫结束的时候,chrome浏览器没有自动关掉
方案: 可以将browser不放在中间件的对象属性中,而放在spider的属性中,中间件中的browser从spider中取:

主题四:一些配置可以让爬虫被识别率降低
COOKIES_ENABLED = False禁用cookie;
有的网站会根据cookie进行分析,判断是否是爬虫,对于不需要登陆也能访问的网站,就把cookie禁用掉,Request就不会把cookie给带过去;
DOWNLOAD_DELAY = 10 对同一个网站的下一个url的延迟时间
AUTOTHROTTLE_ENABLED = TRUE 启用AutoThrottle扩展,然后可以设置一些延迟,比如AUTOTHROTTLE_START_DELAY(初始下载延迟),AUTOTHROTTLE_MAX_DELAY(最大的下载延迟)等(查文档)
如何在不同的spider里面配置一些不同的setting值
有些网站我们需要登陆才能访问,就需要开启cookie,有些网站需要禁用cookie,而settings.py中的设置就一个,此时就需要针对不同的爬虫设置不同的setting值.
Spider类中有一个custom_settings字典属性,子类中重写这个属性,把配置写在这里面,就可以使用各自的配置
相应的视频教程在这里 https://mp.weixin.qq.com/s/DG-T965Y9yKLwNYPus2cXA
本文由 mdnice 多平台发布















 4600
4600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









