






一 ASCII字符集及本地化
ASCII(American Standard Code for Information Interchange)使用一个字节表示英语世界内的常用符号。其中,0到32状态表示一些控制字符,33到127状态表示标点,数字,字母等。
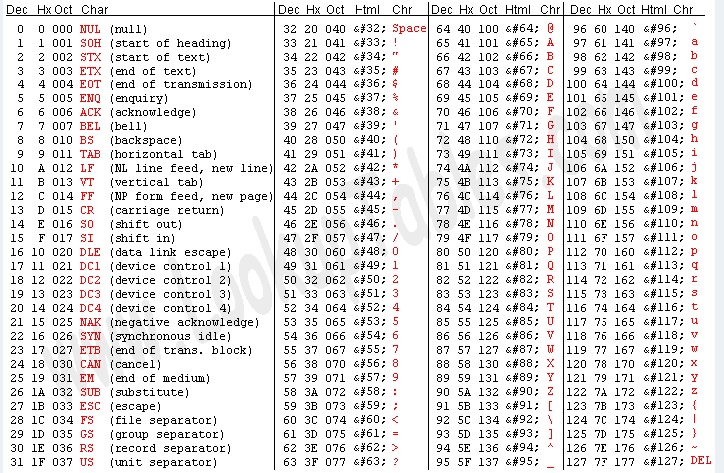 (来自 www.asciitable.com)
(来自 www.asciitable.com)
后来,ASCII扩展了128到255状态形成扩展ASCII,加入了一些特殊字符。一般情况下,最常使用的就是ASCII的0到127状态。
当需要表示象形文字时,一个字节已经无法完成编码。针对简体中文,出现了GB2312编码,该编码规则如下:
1)针对ASCII码0到127状态;
2)取消ASCII码扩展部分,使用扩展部分(0XA1-0XF7)与下一个字节高四位(0XA1-0XFE)组合表示汉字,则可表示大约七八千简体汉字。
这部分编码也重复包括了一些数学符号,标点符号等,即全角字符。而ASCII码中符号被称为半角字符。
GB2312后面还进行了一些扩展,但针对简体中文本地化编码中,通常使用GB2312编码。繁体中文使用BIG5编码。到目前为止,针对ASCII即其之上的扩展(如GB2312),编码与字符集可以视为等同的。
二 UNICODE字符集
使用ASCII字符集及本地化解决方案(如GB2312,BIG5等),可以在计算机上使用不同语言。但在跨语言交流中,需要一个统一的编码方式,这就是UNICODE字符集(Universal Multiple-Octet Coded Character Set),其基本规则如下:
1)使用两个字节表示字符;
2)对ASCII字符直接一个字节补零扩展到两个字节;
3)使用其他状态表示世界上其他语言字符。
UNICODE字符集可以被多种方式编码,其中,字符集定义就是一种编码方式。在VS开发环境中,将字符集选择为:Use Unicode Character Set,编译器使用 UNICODE _UNICODE选项,这直接导致TCHAR被定义为wchar_t,系统按UNICODE字符规则使用两个字节表示一个字符。当字符集选择为:Use Multi-Byte Character Set,编译器使用 _MBCS 选项,TCHAR被定义为char,系统使用ASCII字符集及本地化解释字符。
UNICODE可以使用不同方式编码,包括UTF8, UTF16等,在网络上一般使用UTF8作为UNICODE编码实现,基本规则如下:
1)对UNICODE前127个字符,使用一个字节编码;
2)对剩下的字符,针对不同区间,使用2,3,4个字节编码,其中每个字节开始插入10,110,1110,11110等;
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
三 字符集间转换
在编程应用中,windows提供了不同字符集间转换函数,如下:
MultiByteToWideChar:将多字节转换为UNICODE字符集定义编码,其中多字节包括:1)ASCII字符集及本地化;2)UTF8(UNICODE变长编码方案)等。
WideCharToMultiByte:将UNICODE字符集定义编码转换为多字节编码,多字节定义如上。
1 char* str_ascii = "中"; // ASCII扩展,简体中文中为GB2312 2 wchar_t str_ucs[260]; 3 char str_utf8[260]; 4 memset(str_ucs, 0, 260* sizeof(wchar_t)); 5 memset(str_utf8, 0, 260); 6 7 // GB2312编码转换成unicode字符集 8 int len = MultiByteToWideChar(CP_ACP, 0, str_ascii, strlen(str_ascii), str_ucs, sizeof(str_ucs)); 9 10 // unicode字符集转换为utf8编码 11 int len2 = WideCharToMultiByte(CP_UTF8, 0, str_ucs, wcslen(str_ucs), str_utf8, sizeof(str_utf8), NULL, NULL); 12 13 // utf8编码转换为unicode字符集 14 int len3 = MultiByteToWideChar(CP_UTF8, 0, str_utf8, strlen(str_utf8), str_ucs, sizeof(str_ucs));















 1411
1411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









