










数据库设计tips & idea自动生成Entity
数据库设计tips
sql语句的生成
概念模型生成物理模型 -> 物理模型生成sql语句 -> sql语句进行建表 ->
概念模型对词汇的要求很高,其支持的类型和数据库类型有对应关系,但不是一一对应的,有其自己的转换规则
是比较麻烦的
solution
- 直接设计物理模型
- 将数据库设计好之后反向生成E-R图
数据库中的约束越少越好, 更多的约束在代码中实现
因为数据库更趋向于分布式
数据库中主键的设置使用int型的id
虽然对于用户没有实际意义, 但是对于在实际开发中会很方便
数据库表名使用下划线全小写命名法
遵循全小写, 下划线分段的命名方法
在数据库的设计中不定义外键关联
因为数据关系之间肯定会有外键关系, 但是不在数据库中定义
- 数据库很大, 当涉及到分表 / 分库操作时, 有外键关联很麻烦
- 数据库本身规模较大, 外键关联对数据库集群产生影响
- 案例本身可能不是关系型数据库, 可能会放在非关系型数据库中以便搜索, 会将elasticSearch中的id放到数据库中的id中;
- 可能案例放在关系型数据库不是一个很好的选择, 如果要转移到非关系型数据库要大量的修改代码, 所以外键的关联用代码来进行实现, 不在数据库中进行约束.
- 如果是小系统, 会使用外键关联来保持数据的一致性; 如果是大系统不要用数据库来保证, 要用代码来保证.
- 如果在数据库中设计了外键关联, 那么Springdata也提供了多种关于外键关联的实现方式.
自动生成Entity的意义
实际的开发中是基于数据库搭建整个项目,需要维护的是数据库,而不是Java文件
所以需要根据数据库表自动生成Entity文件, 快速的生成数据库,并且使用JpaRepository的基本增删查改
基于idea的操作步骤
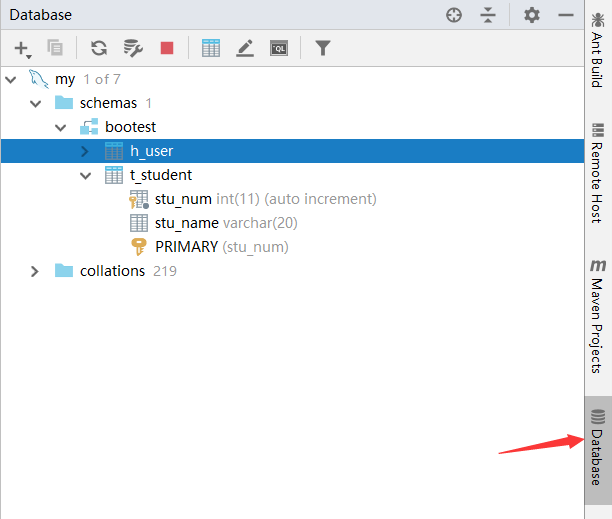
在idea右边栏中连接数据库
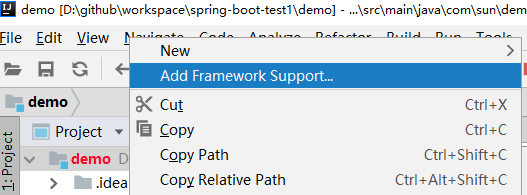
在File中添加框架支持
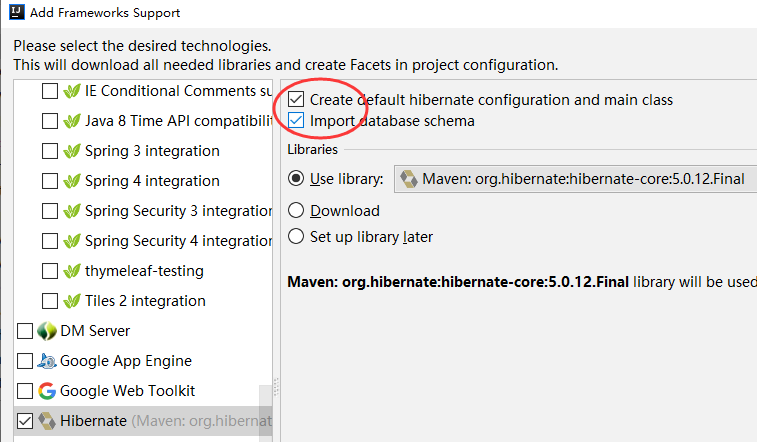
选择hibernate
之后项目中生成以下两个文件

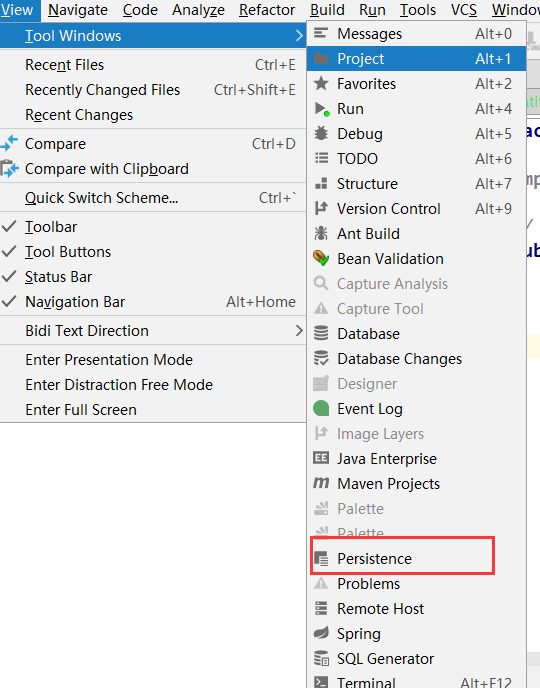
在view -> Tool Windows -> persistence中选中生成持久性映射
然后选择通过数据库模式进行生成
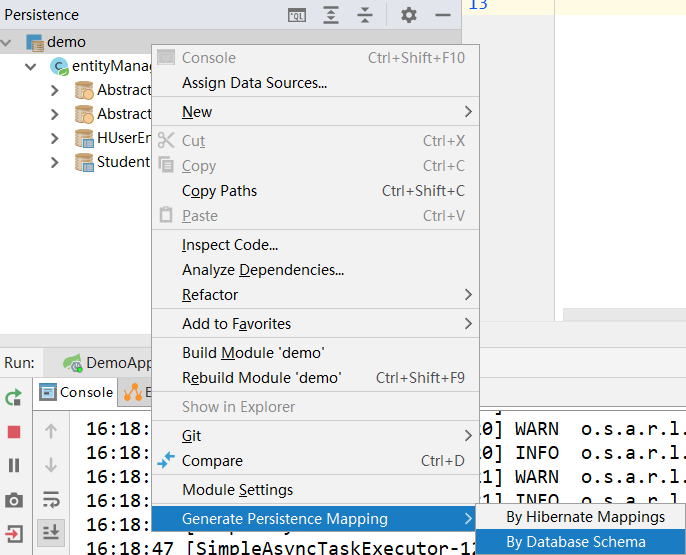
选择包,和文件名前缀,后缀
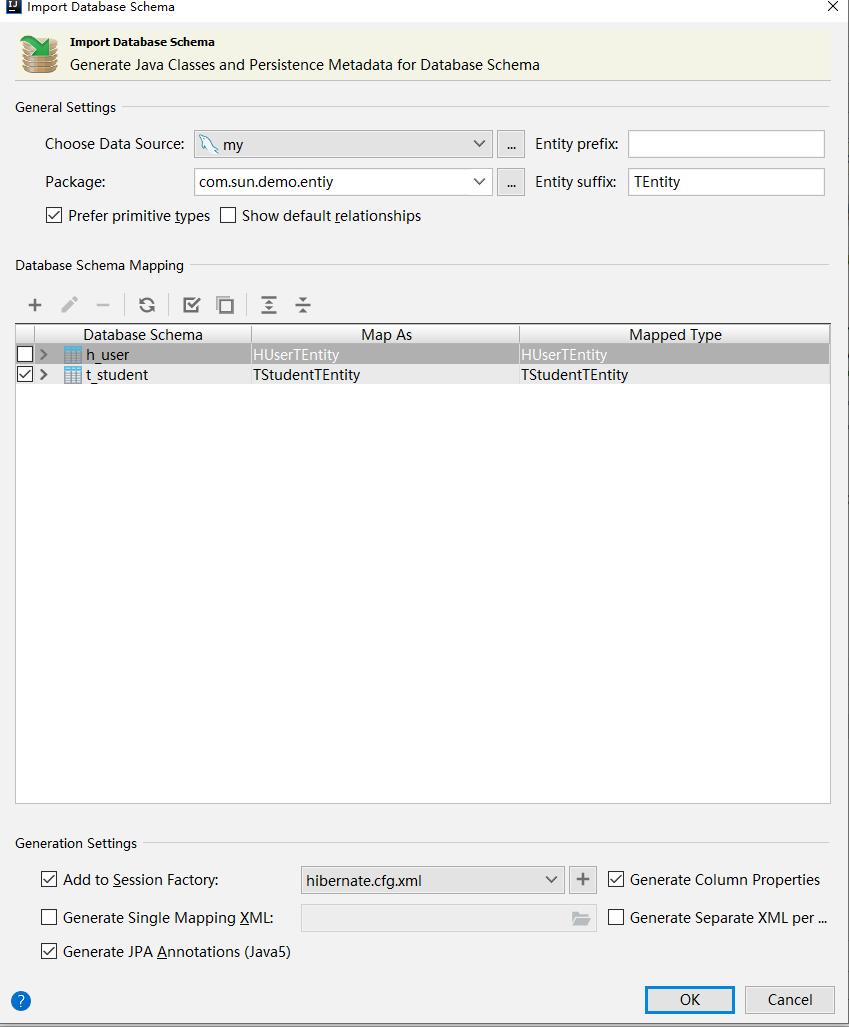
成功生成
PS
char -> String
在navicat的数据库属性类型是有char类型的, 但是在自动生成Entity的过程中, char会被自动转化为String, 这是需要手动进行修改

















 5993
5993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











