







本节将介绍如何使用Sklearn进行数据处理,以及其自带的几个标准数据集的调用方法。本节是学习后面内容的基础,如果您已经对本节内容相当熟悉,可跳过本节内容。
1.1 数据处理基础
数据 (data) 是经验的另一种说法,也是信息的载体。
在使用机器学习时,必须要有汇总并整理到一定程度的数据。以数据为基础,按规定的法则进行学习,最终才能进行预测。因此没有数据,就不能进行机器学习,数据的收集和整理是进行机器学习的第一步。
有这样一种说法:机器学习工作 80% 以上的时间花在了数据预处理上。在实际用机器学习解决问题之前,要先收集数据,有时还需要做问卷调查,甚至购买数据。然后,需要为收集到的数据人工标注答案标签,或者将其加工为机器学习算法易于处理的形式,删除无用的数据,加入从别的数据源获得的数据等。另外,基于平均值和数据分布等统计观点查看数据,或者使用各种图表对数据进行可视化,把握数据的整体情况也很重要。此外,有时还需要对数据进行正则化处理。这些操作被称为数据预处理。
1.1.1 数据类型的划分
机器学习中使用各种类型的数据,主要可分为:
- 结构化数据和非结构化数据(按数据具体类型划分);
- 原始数据和加工数据(按数据表达形式划分);
- 样本内数据和样本外数据 (按数据统计性质划分);
(1)结构化数据和非结构化数据
- 结构化数据 (structured data)是由二维表结构来逻辑表达和实现的数据。常见的结果话数据类型常以文本形式保存,如后缀为txt或csv格式的文件。
- 非结构化数据是没有预定义的数据,不便用数据库二维表来表现的数据。常见的非结构化数据类型包括图片、文字、语音和视频,等等。
两者相比,机器学习模型主要使用的是结构化数据,即二维的数据表。表中的列含有表示数据本身特征的多种信息,行则是由多个信息构成的数据集。即,不同的列代表不同的特征,不同的行代表不同的样本。
对于非结构化数据,在处理之前需要预先转换成结构化数据,比如把图像数据中的像素点重组成一维数组(有时称为张量),将语音信号借助时域采样转换为一维时间序列,等等。
下面以一个篮球运动员的比赛数据为例,说明结构化数据中的一些术语。
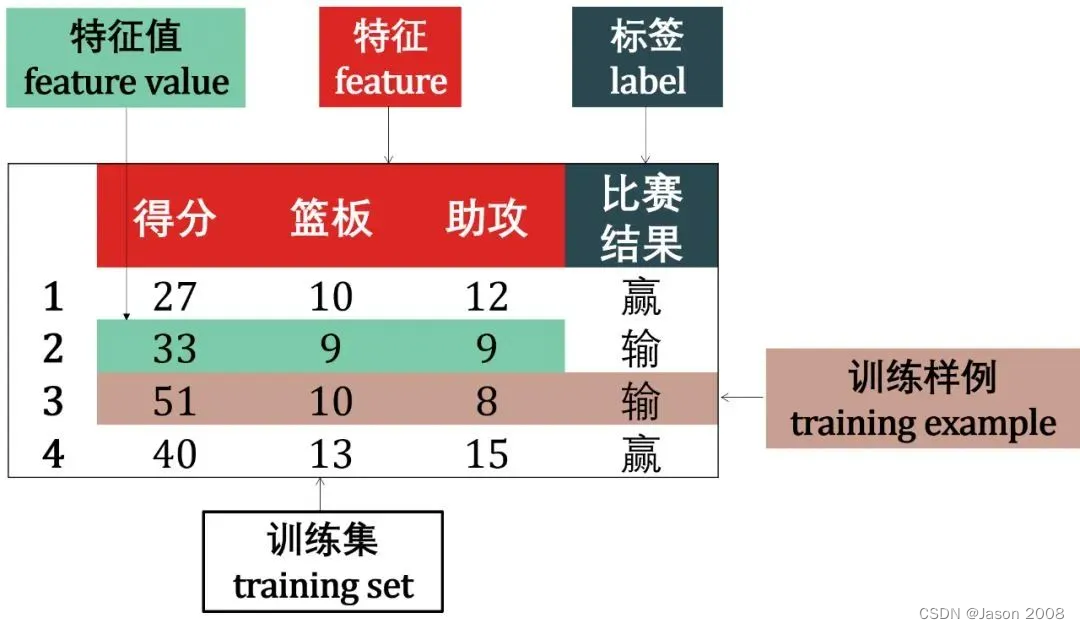
以上数据中:
- 每行的记录,称为一个实例(instance)
- 反映对象在某方面的性质,例如得分,篮板,助攻,称为特征(feature)或输入 (input)
- 特征上的取值,例如"实例1"对应的 27, 10, 12 称为特征值(feature value)
- 关于示例结果的信息,例如"赢",称为标签(label)或输出(output)
- 包含标签信息的示例,则称为样例(example),即样例 = (特征, 标签)
- 从数据中学得模型的过程称为学习(learning) 或训练(training)
- 在训练数据中,每个样例称为训练样例(training example),整个集合称为训练集(training set)
1.2 数据预处理
Sklearn自带许多标准数据集,这些数据集从简单到复杂,可用于机器学习的各个领域。主要包括以下四类:
- Toy datasets
- Real world datasets
- Generated datasets 生成式数据集
1.3 Sklearn库标准数据集
Sklean中使用的模型数据有两种形式:
- Numpy 二维数组(ndarray)的稠密数据(dense data),大部分数据采用这种格式。
- SciPy 矩阵(scipy.sparse.matrix)的稀疏数据(sparse data)。
在机器学习中通常用符号 X 表示数据,即模型的自变量。
它的大小 = [样本数, 特征数],如下图所示。假定某数据有21000 条,即样本数为21000,每一个样本包含21栏,即21个特征值,则该数据形状为 [21000, 21]。
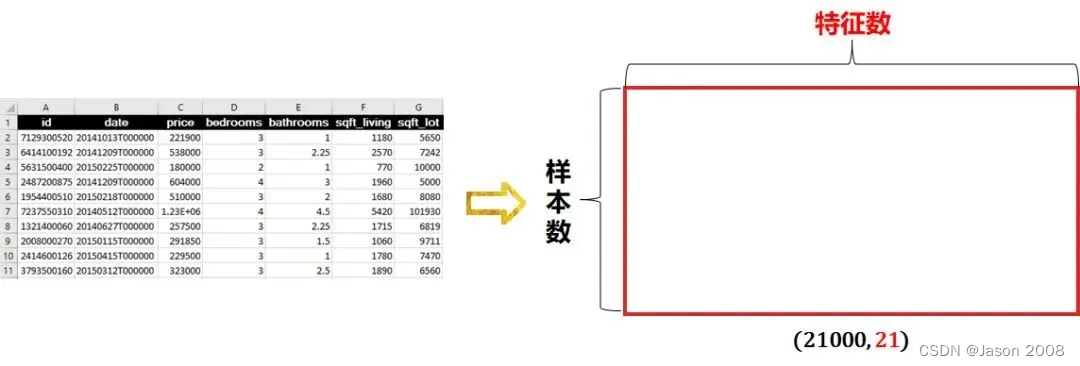
对于监督学习,除了需要特征 X 之外,还需要一个对应的标签向量y, y 通常是 Numpy 一维数组,其行数与样本数相等(即每一个样本对应一个标签),无监督学习没有y。
Sklearn自带许多标准数据集,这些数据集从简单到复杂,可用于机器学习的各个领域。主要包括以下四类:
- Toy datasets
- Real world datasets
- Generated datasets 生成式数据集
- Loading other datasets 其它来源数据集
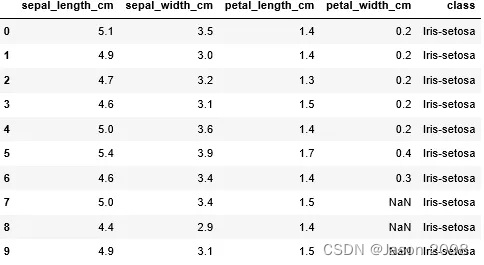
(1)鸢尾花数据集
鸢尾花数据集(Iris Dataset)是常用的分类实验数据集,由Fisher, 1936收集整理。它是一类多重变量分析的数据集。数据集包含150个数据样本,分为3类(Setosa,Versicolour,Virginica),每类50个数据,每个数据包含4个属性(花萼长度、花萼宽度、花瓣长度、花瓣宽度)。

下图所示为
(2)波士顿房价数据集
波士顿房价数据集(Boston Housing Dataset)
该数据集包含了 506 个波士顿地区的房屋数据,其中每个数据点都有 13 个变量(例如犯罪率、房产税率、房间数量等)和一个目标变量(房屋价格的中位数)。该数据集最初由 Harrison, D. 和 Rubinfeld, D.L. 在 1978 年发布。
https://zhuanlan.zhihu.com/p/618818240















 2369
2369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









