







曾经遇到的一个面试题:主键与索引区别
主键:主键是唯一的,一个表中只能包含一个主键,也可以利用主键查询记录
索引:可根据索引快速访问表中的特定信息,它是对表中一列或多列的值进行排序的一种结构,等价于书的目录
是不是还是体会不到两者真正的区别~~~~~
详解:参照:
第一部分:环境搭建
1.安装MySQL:https://blog.csdn.net/bobo553443/article/details/81383194
2.启动以及创建用户
3.数据类型:数值类型、日期和时间类型、字符串类型
第二部分:MySQL的常用命令复习
1.MySQL 创建数据表:
mysql> create table employee(
-> emp_id int not null auto_increment,
-> name char(20) not null,
-> age int not null,
-> work char(32) not null,
-> register_date date,
-> primary key (emp_id)
-> );
Query OK, 0 rows affected (0.04 sec)
mysql> desc employee;
+---------------+----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------------+----------+------+-----+---------+----------------+
| emp_id | int(11) | NO | PRI | NULL | auto_increment |
| name | char(20) | NO | | NULL | |
| age | int(11) | NO | | NULL | |
| work | char(32) | NO | | NULL | |
| register_date | date | YES | | NULL | |
+---------------+----------+------+-----+---------+----------------+
5 rows in set (0.01 sec)备注:auto_increment 定义列为自增的属性,一般用于主键,数值会自动加1,primary key 关键字用于定义列为主键。 可以使用多列来定义主键,列间以逗号分隔
2.MySQL插入数据:
mysql> insert into employee (name,age,work,register_date) values('Json',25,'teacher','2010-01-12');
Query OK, 1 row affected (0.00 sec)
mysql> insert into employee (name,age,work,register_date)
-> values
-> ('Mark',24,'teacher','2010-01-20'),
-> ('Join',28,'programmer','2010-04-20');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from employee;
+--------+------+-----+------------+---------------+
| emp_id | name | age | work | register_date |
+--------+------+-----+------------+---------------+
| 1 | Json | 25 | teacher | 2010-01-12 |
| 2 | Json | 25 | teacher | 2010-01-12 |
| 3 | Mark | 24 | teacher | 2010-01-20 |
| 4 | Join | 28 | programmer | 2010-04-20 |
+--------+------+-----+------------+---------------+
4 rows in set (0.00 sec)备注:插入数据时,注意批量插入数据的使用
3.MySQL查询数据:
- 可进行单表或者多表查询,表之间用逗号(,)分割
- select * from table,会返回表中的所有字段数据
- 使用where语句设置任何查询条件
- 使用limit属性限制返回记录条数
- 使用offset置顶select语句开始查询的数据偏移量,默认为0
语法:
SELECT column_name,column_name
FROM table_name
[WHERE Clause]
[OFFSET M ][LIMIT N]演习:
mysql> select * from table_A
-> ;
+---+------+
| a | name |
+---+------+
| 1 | Mark |
| 2 | Json |
| 3 | Json |
| 4 | Rany |
+---+------+
4 rows in set (0.00 sec)
mysql> select * from table_B;
+---+------+
| b | name |
+---+------+
| 4 | Json |
| 4 | Rany |
| 1 | Mark |
+---+------+
3 rows in set (0.00 sec)
mysql> select * from table_A,table_B where table_A.a=table_B.b;
+---+------+---+------+
| a | name | b | name |
+---+------+---+------+
| 1 | Mark | 1 | Mark |
| 4 | Rany | 4 | Json |
| 4 | Rany | 4 | Rany |
+---+------+---+------+
3 rows in set (0.00 sec)
mysql> select name from table_A where name like 'J%';
+------+
| name |
+------+
| Json |
| Json |
+------+
2 rows in set (0.00 sec)
mysql> select name from table_A limit 3 offset 2;
+------+
| name |
+------+
| Json |
| Rany |
+------+
2 rows in set (0.00 sec)科普一下limit、offset用法:
① select * from table_A limit 2,1;
是跳过前面的2条记录之后,取出1条数据,limit后面是从第2条开始读,读取1条信息,即读取第3条数据
② select * from table_A limit 2 offset 1;
是从第1条(不包括)数据开始取出2条数据,limit后面跟的是2条数据,offset后面是从第1条开始读取,即读取第2,3条
mysql> select * from table_A;
+---+------+
| a | name |
+---+------+
| 1 | Mark |
| 2 | Json |
| 3 | Json |
| 4 | Rany |
| 5 | cao |
| 5 | zhi |
| 5 | yun |
+---+------+
7 rows in set (0.00 sec)
mysql> select * from table_A limit 4,2;
+---+------+
| a | name |
+---+------+
| 5 | cao |
| 5 | zhi |
+---+------+
2 rows in set (0.00 sec)
mysql> select * from table_A limit 2 offset 3 ;
+---+------+
| a | name |
+---+------+
| 4 | Rany |
| 5 | cao |
+---+------+
2 rows in set (0.00 sec)4.group by 使用:
语法:
SELECT column_name, function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;mysql> select * from table_A;
+---+--------+
| a | name |
+---+--------+
| 1 | Mark |
| 2 | Json |
| 3 | Json |
| 4 | Rany |
| 5 | lixian |
| 5 | lixian |
+---+--------+
6 rows in set (0.00 sec)
mysql> select name,count(*) from table_A group by name;
+--------+----------+
| name | count(*) |
+--------+----------+
| Json | 2 |
| lixian | 2 |
| Mark | 1 |
| Rany | 1 |
+--------+----------+
4 rows in set (0.00 sec)
#:此处count(*),是为了统计分组后,每组成员(name)的总和
mysql> select name,count(*) as sum from table_A group by name;
+--------+-----+
| name | sum |
+--------+-----+
| Json | 2 |
| lixian | 2 |
| Mark | 1 |
| Rany | 1 |
+--------+-----+
4 rows in set (0.00 sec)
#:重命名语法 as
mysql> select name from table_A group by name;
+--------+
| name |
+--------+
| Json |
| lixian |
| Mark |
| Rany |
+--------+
4 rows in set (0.00 sec)
mysql> select name,a from table_A group by name with rollup;
+--------+---+
| name | a |
+--------+---+
| Json | 2 |
| lixian | 5 |
| Mark | 1 |
| Rany | 4 |
| NULL | 4 |
+--------+---+
5 rows in set (0.00 sec)
#:这里with rollup是为了统计分组后,有多少组,这里分组后有4组
mysql> select name,count(*) as sum from table_A group by name with rollup;
+--------+-----+
| name | sum |
+--------+-----+
| Json | 2 |
| lixian | 2 |
| Mark | 1 |
| Rany | 1 |
| NULL | 6 |
+--------+-----+
5 rows in set (0.00 sec)
#:此处with rollup之后是null和6,null表示所有成员,6是统计的每组成员的总和
mysql> select coalesce(name, 'name_sum'),count(*) as sum from table_A group by name with rollup;
+----------------------------+-----+
| coalesce(name, 'name_sum') | sum |
+----------------------------+-----+
| Json | 2 |
| lixian | 2 |
| Mark | 1 |
| Rany | 1 |
| name_sum | 6 |
+----------------------------+-----+
5 rows in set (0.00 sec)
# coalesce 来设置一个可以取代 NUll 的名称
mysql> select name,count(*) as sum ,a,a as b from table_A group by name with rollup;
+--------+-----+---+---+
| name | sum | a | b |
+--------+-----+---+---+
| Json | 2 | 2 | 2 |
| lixian | 2 | 5 | 5 |
| Mark | 1 | 1 | 1 |
| Rany | 1 | 4 | 4 |
| NULL | 6 | 4 | 4 |
+--------+-----+---+---+
5 rows in set (0.00 sec)
备注:所以后面不管你加多少列 这里都是统计分组后的组数总和第三部分:Mysql连接
#table_A表:
mysql> select * from table_A;
+---+--------+
| a | name |
+---+--------+
| 1 | Mark |
| 2 | Json |
| 3 | Json |
| 4 | Rany |
| 5 | lixian |
| 5 | lixian |
+---+--------+
6 rows in set (0.00 sec)
#table_B表:
mysql> select * from table_B;
+---+------+
| b | name |
+---+------+
| 4 | Json |
| 4 | zhi |
| 1 | nan |
| 7 | liu |
| 6 | yang |
+---+------+
5 rows in set (0.00 sec)1.内连接:获取两个表中字段匹配关系的记录
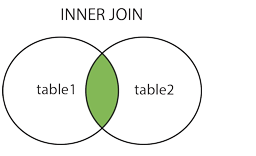
mysql> select * from table_A A inner join table_B B on A.a=B.b;
+---+------+---+------+
| a | name | b | name |
+---+------+---+------+
| 1 | Mark | 1 | nan |
| 4 | Rany | 4 | Json |
| 4 | Rany | 4 | zhi |
+---+------+---+------+
3 rows in set (0.00 sec)
mysql> select * from table_A A, table_B B where A.a=B.b;
+---+------+---+------+
| a | name | b | name |
+---+------+---+------+
| 1 | Mark | 1 | nan |
| 4 | Rany | 4 | Json |
| 4 | Rany | 4 | zhi |
+---+------+---+------+
3 rows in set (0.00 sec)
#:内链接,也就是求交集,平常中用的最多,等价于where2.左连接:获取左表所有记录,即使右表没有对应匹配的记录
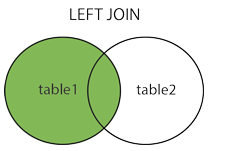
mysql> select * from table_A A left join table_B B on A.a=B.b;
+---+--------+------+------+
| a | name | b | name |
+---+--------+------+------+
| 4 | Rany | 4 | Json |
| 4 | Rany | 4 | zhi |
| 1 | Mark | 1 | nan |
| 2 | Json | NULL | NULL |
| 3 | Json | NULL | NULL |
| 5 | lixian | NULL | NULL |
| 5 | lixian | NULL | NULL |
+---+--------+------+------+
7 rows in set (0.00 sec)3.右连接:与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录
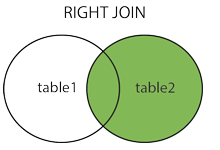
mysql> select * from table_A A right join table_B B on A.a=B.b;
+------+------+---+------+
| a | name | b | name |
+------+------+---+------+
| 1 | Mark | 1 | nan |
| 4 | Rany | 4 | Json |
| 4 | Rany | 4 | zhi |
| NULL | NULL | 7 | liu |
| NULL | NULL | 6 | yang |
+------+------+---+------+
5 rows in set (0.00 sec)4.多表并集:
mysql> select * from table_A A right join table_B B on A.a=B.b union select * from table_A A left join table_B B on A.a=B.b
-> ;
+------+--------+------+------+
| a | name | b | name |
+------+--------+------+------+
| 1 | Mark | 1 | nan |
| 4 | Rany | 4 | Json |
| 4 | Rany | 4 | zhi |
| NULL | NULL | 7 | liu |
| NULL | NULL | 6 | yang |
| 2 | Json | NULL | NULL |
| 3 | Json | NULL | NULL |
| 5 | lixian | NULL | NULL |
+------+--------+------+------+
8 rows in set (0.01 sec)第四部分:事务的使用
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









