







在掌握了urllib几个模块的相关用法后,接下来就是进入实战步骤了~
(一)抓取豆瓣网站同城活动
豆瓣北京同城活动 该链接指向豆瓣同城活动的列表,向该链接发起request:
# encoding=utf-8
import urllib
import urllib2
import cookielib
import re
cj=cookielib.CookieJar()
opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
url="http://beijing.douban.com/events/future-all?start=0"
req=urllib2.Request(url)
event=urllib2.urlopen(req)
str1=event.read()我们会发现返回的html代码中,除了我们需要的信息之外,还夹杂了大量的页面布局代码:

如上图所示,我们只需要中间那些关于活动的信息。而为了提取信息,我们就需要正则表达式了~
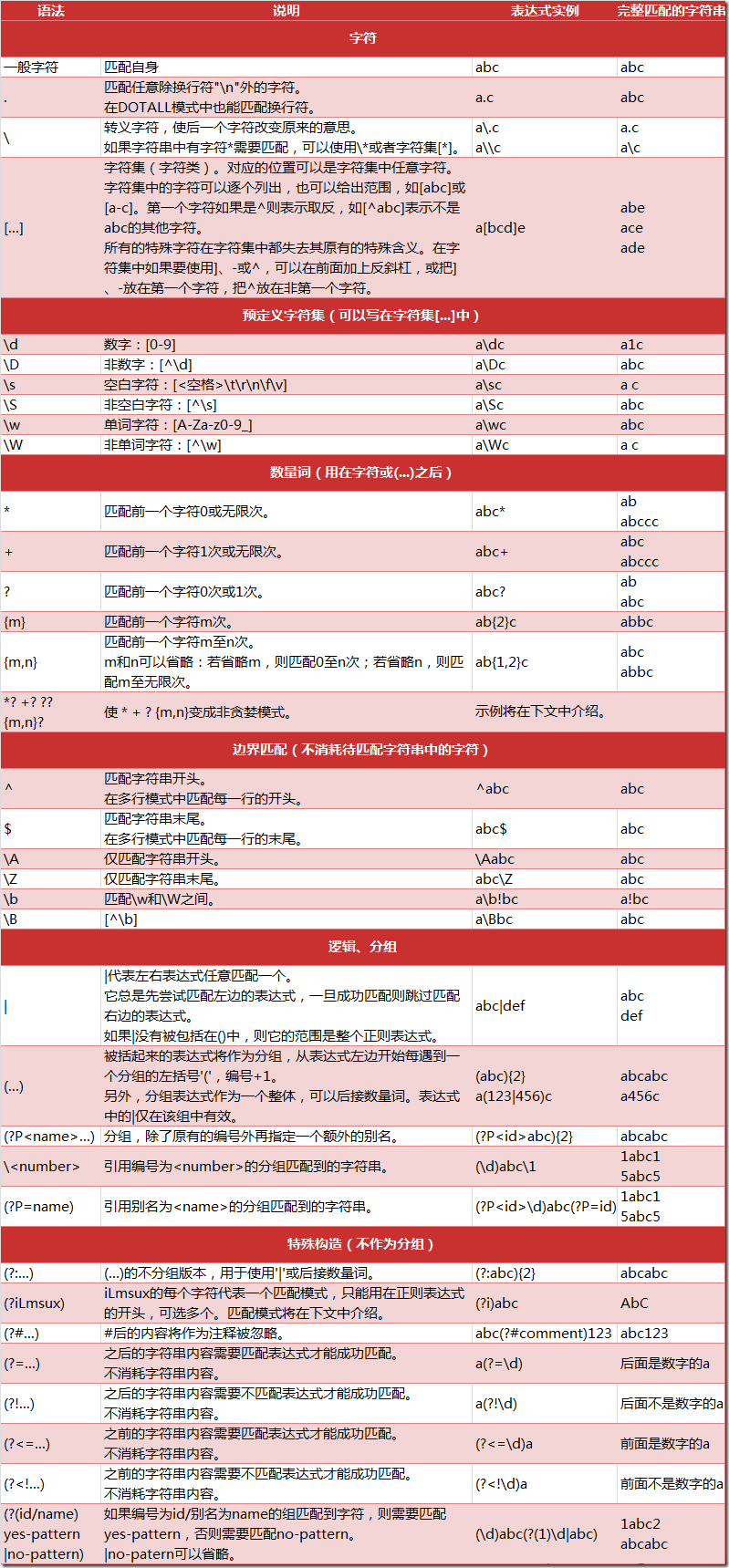
正则表达式是一种跨平台的字符串处理工具/方法,通过正则表达式,我们可以比较轻松的提取字符串中我们想要的内容~
这里不做详细介绍了,个人推荐余晟老师的正则指引,挺适合新手入门的。下面给出正则表达式的大致语法:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









