






目录
引用在使用时,相当于给变量起别名,所以我们在使用引用的时候,会有一些小小的变化,以下面的代码为例
什么是引用
为了简化指针,C++提出了引用
引用变量就是一个别名,也就是是说,它是某个已存在变量的另一个名字。一旦把引用初始化为某个变量,就可以使用该引用名称或变量名称来指向变量。
引用和指针的区别
引用和指针之间主要有三个不同:
1、 不存在空引用。引用必须连接到一块合法的内存,而指针可以是空指针
2、 一旦引用被初始化为一个对象,就不能被指向到另一个对象。而指针可以在任何时候指向到另一个对象
3、 引用必须在创建时被初始化,而指针可以在任何时间被初始化
对于这三个区别,其实很好理解:由于引用不允许更改指向,所以空引用将没有任何意义,故而产生了第一个区别,而第二个第三个就是基本概念罢了,所以引用和指针最大的区别总结起来就一句话:引用不能修改指向。
引用的作用
由于引用是给变量起别名,所以使用引用可以简化部分函数,下面以swap函数为例
#include <iostream>
void swap(int a, int b){
int tmp = a;
a = b;
b = tmp;
}此代码中,a与b是形参,而形参的改变不能影响实参的改变,所以此函数不能完成我们的要求
#include <iostream>
void swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
此代码中,a与b是对应实参的地址的拷贝,*a与*b与实参访问同一块地址,所以可以完成交换,但由于此处传的是地址,故函数内部需要解地址,传参时需要传地址,而取地址符&敲起来特别麻烦,所以这个代码就不是一个很好的选择
#include <iostream>
void swap(int& a, int& b)
{
int tmp = a;
a = b;
b = tmp;
}此代码中,a与b是对应实参的别名,也就是说,形参和实参是同一个东西。a,b不过是你给实参起的外号而已,并且传参时,也不需要取地址,写起来就非常的舒服了。这也是引用的好处之一。
引用的底层实现

通过反汇编我们可以得知,引用实际上也是一个指针。在底层中,引用和指针的操作原理相同。
事实上,引用就是一个指针常量,也就是不可修改指向的指针。由于这个特性,编译器在处理引用时会自动对该引用对应的指针解地址,这就使得引用在书写时,比较方便,同时也使得引用的大小与指针的大小不相同。
由于编译处理引用时会将其自动解地址。所以,当我们用sizeof去求引用的大小时,我们获取的大小实际是引用所指对象的大小,这也是为什么我们说引用是给变量起别名的原因。而指针的大小与地址总线的数目有关,也就是与环境(硬件)有关。以long为例:64位系统有64个地址总线,每一个地址总线决定一个位,所以也就是64位8字节,而32位(win32/x86)系统有32个地址总线,所以是32位4字节。
引用的细节
引用时发生类型转换
引用在使用时,相当于给变量起别名,所以我们在使用引用的时候,会有一些小小的变化,以下面的代码为例
#include <iostream>
int main()
{
double d = 12.34;
int& r = (int)d;
return 0;
}此代码,在编译的时候会报错,原因很简单,r是一个int类型的引用,而d是一个double类型的浮点数,在将double类型的数据赋值给int类型时,会产生截断。
在截断的时候,会产生一个与double类型值相同的临时变量,而这个临时变量是不可修改的,而应用指向的对象是可以通过引用来修改的,上面的代码相当于放大了权限,所以编译器会报错,如果我们非要这么做,可以在引用前加上const进行修饰,将其指向的值变成不可修改的,就可以通过编译。
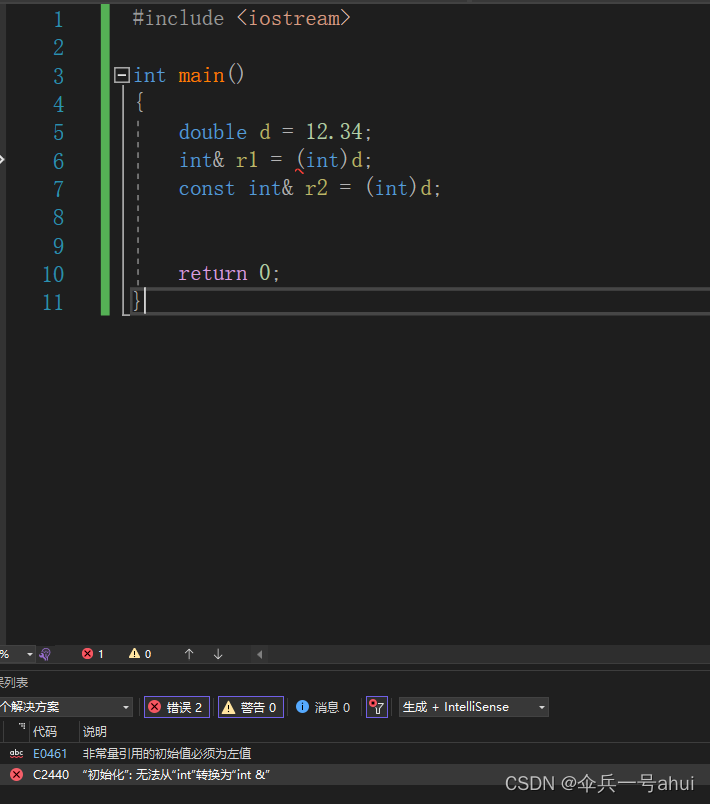
我们看到,编译器只在第6行报了错误,这也验证了我们的说法。
引用返回一个销毁的变量
用引用去接受一个销毁的变量时,那么该引用会是一个随机值
#include <iostream>
int& Func()
{
int n = 0;
//执行的操作
n++;
return n;
}
int main()
{
int& a = Func();
std::cout << a << "\n";
std::cout << a << "\n";
std::cout << a << "\n";
return 0;
}运行结果:

我们知道,函数在被调用时,首先会为这个函数创建其对应的栈帧,用来给这个函数开辟空间,使其正常执行,这也是递归深度较深时,栈溢出导致程序崩溃的原因。而函数调用结束后会释放这块空间。
这里n在函数Func执行结束后被销毁,对应的a访问的地址就变成了一块已经被释放的空间,所以a对应的值就会变为随机值,那么为什么第一次输出会是1呢?
其实,cout也是一个函数,在运算符重载那块我们会详细说明。在cout调用的时候它的栈帧覆盖了Func调用时使用的空间,这就导致这个值从1变成了随机值。
就相当于你去住酒店,你走的时候在酒店里放了个苹果,然后你自己偷偷的复制了一张门卡。当你下一次再去打开那间房子时,你的苹果可能会被酒店的人员整理打扫,苹果就不见了,或者下一个用户在里面放了个梨,你进去没有找到苹果,但是看到了一个梨。这里也是相同的原理。
为了验证我们的说法,我们可以用以下代码进行测试:
#include <iostream>
int& Func()
{
int n = 0;
//执行的操作
n++;
return n;
}
void Func2()
{
int c = 100;
}
int main()
{
int& a = Func();
std::cout << a << "\n";
std::cout << a << "\n";
Func2();
std::cout << a << "\n";
return 0;
}运行结果:

这里就是由于Func2的栈帧覆盖了Func的栈帧,并且Func2中c的位置与n的地址刚好一样,得到了这样的结果。
如果你在测试这段代码时发现其结果不同,可以看一下自己是否关掉了SDL检查,方法:
项目-->属性-->C/C++-->常规-->SDL检查,点否即可。
当你没有关闭SDL检查时可能得到如下结果:

请跟据自己的结果进行调试。















 311
311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









