







独家作者(csdn、掘金、知乎、微信公众号):PaperAgent
每天一篇大模型(LLM)文章来锻炼我们的思维,简单的例子,不简单的方法,提升自己
一、论文信息
- 论文题目:TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones
- 论文链接:https://arxiv.org/abs/2312.16862
- Github:https://github.com/DLYuanGod/TinyGPT-V
二、概要
该文件介绍了TinyGPT-V,这是一种高效的多模态大语言模型(MLLM),它将小语言主干与预训练的视觉模块相结合。作者强调了闭源mlm带来的挑战和现有开源模型的计算需求。他们提出TinyGPT-V作为一种解决方案,它需要更少的计算资源,同时仍能实现令人印象深刻的性能。该模型利用Phi-2语言主干和来自BLIP-2或CLIP的预训练视觉模块。TinyGPT-V独特的量化过程允许在8G设备上进行本地部署和推理。作者强调了成本效益和高效的传销对现实世界应用的重要性。本文还概述了高级语言模型和多模态语言模型的相关工作。方法部分描述了TinyGPT-V的体系结构,包括可视编码器骨干、线性投影层和Phi-2语言模型骨干。它还讨论了使用规范化和LoRA(学习相对注意)来训练较小的语言模型。
要点:
-
TinyGPT-V是一个高效的多模态大型语言模型,需要较少的计算资源。
-
它结合了一个小的语言骨干和预训练的视觉模块。该模型利用Phi-2语言主干和来自BLIP-2或CLIP的预训练视觉模块。
-
TinyGPT-V独特的量化过程允许在8G设备上进行本地部署和推理。具有成本效益和高效的mlm对于实际应用非常重要。
-
TinyGPT-V 训练流程
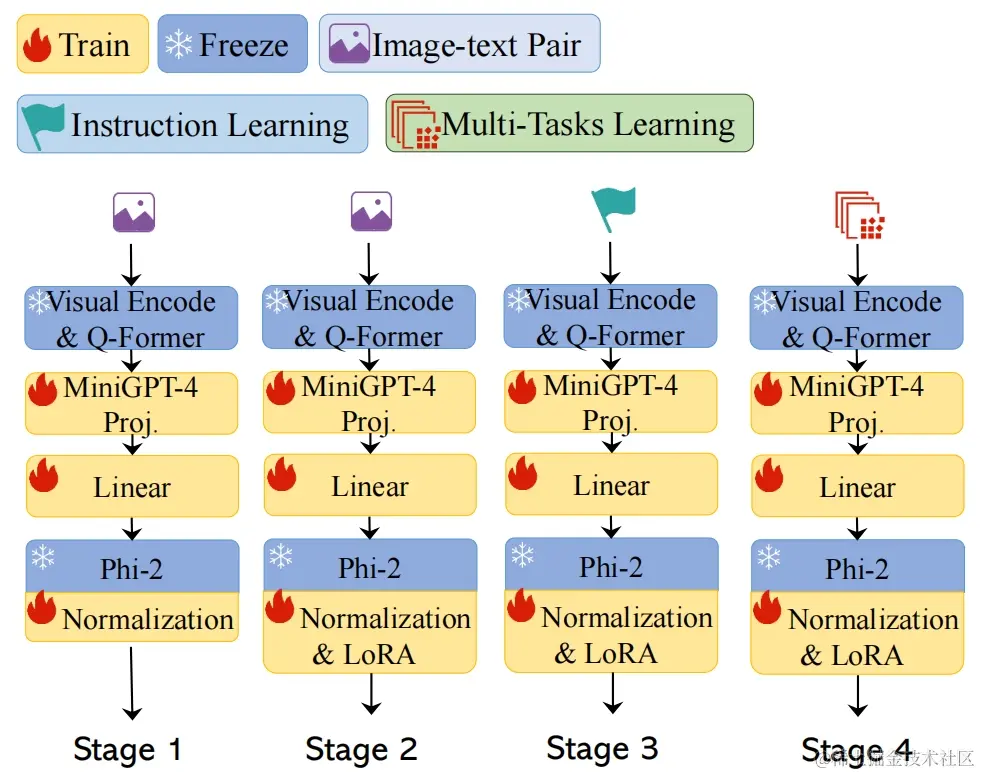
- TinyGPT-V 模型框架

- TinyGPT-V 效果评测
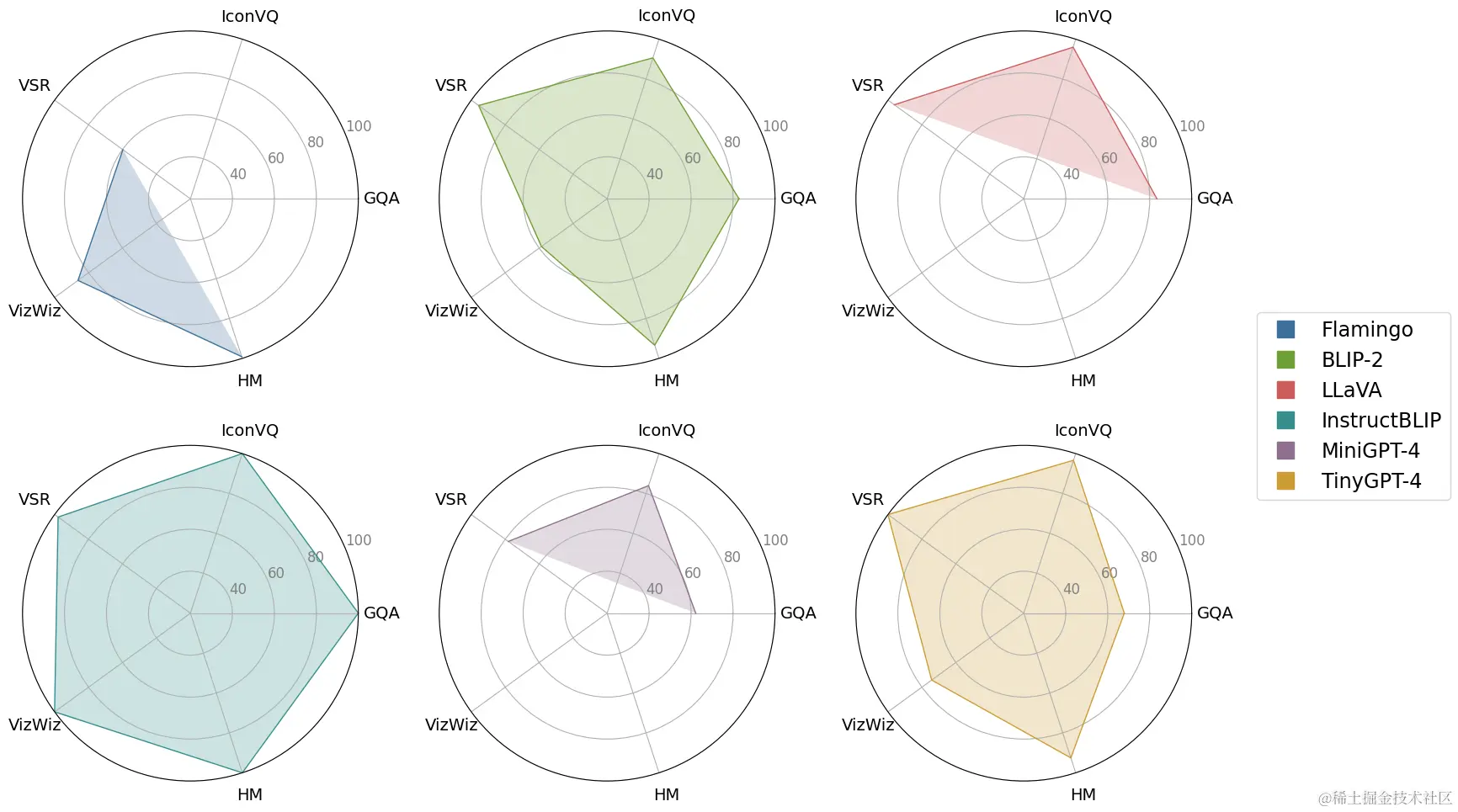
三、讨论
- TinyGPT-V模型在视觉问答任务中的表现如何?
TinyGPT-V模型在视觉问答任务中表现良好,与具有130亿参数的模型相比,TinyGPT-V模型在参数规模上较小,但仍然具有竞争力。在Visual Spatial Reasoning(VSR)零样本任务中,TinyGPT-V模型取得了最高的53.2%的分数,而在其他任务中,TinyGPT-V模型的表现也接近或超过其他大型模型。例如,在GQA基准测试中,TinyGPT-V模型得分为33.6%,在IconVQ挑战中得分为43.3%,在VizWiz任务中得分为24.8%,在Hateful Memes(HM)数据集中得分为53.2%。这些结果表明,TinyGPT-V模型在视觉问答任务中具有较高的性能和效率。
- TinyGPT-V的参数规模、训练与部署资源是多少?
TinyGPT-V的参数规模为2.8亿,训练资源为24G GPU,部署资源为8G GPU或CPU。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









