






目录
K-means先验框
1、K-means算法简介
聚类是一个将数据集中在某些方面相似的数据成员进行分类组织的过程,聚类就是一种发现这种内在结构的技术,聚类技术经常被称为无监督学习。
k均值聚类是最著名的划分聚类算法,由于简洁和效率使得他成为所有聚类算法中最广泛使用的。给定一个数据点集合和需要的聚类数目k,k由用户指定,k均值算法根据某个距离函数反复把数据分入k个聚类中。
Yolov3的先验框是通过K-means聚类得到的,Yolov3一共有三个特征层,每个特征层有三种不同类型的先验框,所以Yolov3聚类的先验框个数是九;下面讲解一下K-means聚类先验框的步骤:
1、在所有真实框里随机选取9个框作为初始聚类中心-先验框;
2、计算每个真实框和1中初始化先验框1,2.......9的交并比值(IOU),在Yolov3中使用交并比的大小来判断聚类的距离大小;传统的K-means聚类方法是通过欧氏距离来判断;
3、经过上一步计算得到每一个真实框和所有先验框的距离D,将其中小于某一阈值的真实框留下来,代表这些框属于该先验框;
4、经过上一步确定每一个先验框及其所属真实框;针对先验框所属的真实框,对其按宽高进行排序,取中间值作为新的先验框的尺寸,按照此种方法对所有先验框进行更新;
5、重复2、3、4步,直至先验框的尺寸不再变化;有些人在最开始选初始化聚类中心的时候使用了不同的方法,提出不同的优化。
下图为传统K-means算法聚类过程图。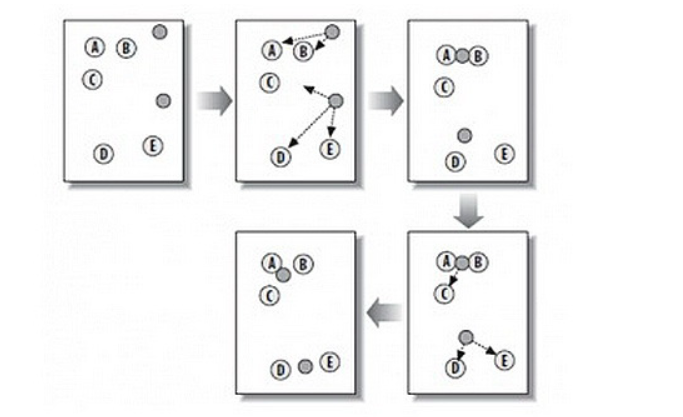
在COCO数据集这9个先验框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。
分配上,在最小的13 * 13特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象。
中等的26 * 26特征图上(中等感受野)应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。
较大的52 * 52特征图上(较小的感受野)应用较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。
感受一下9种先验框的尺寸,下图中蓝色框为聚类得到的先验框。黄色框式ground truth,红框是对象中心点所在的网格:

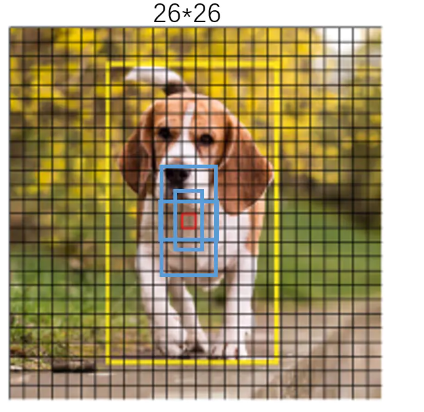















 1263
1263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









