







1.Word2vec简介
Word2vec,为一些用来产生词向量的有关模型。这些模型是浅层的神经网络,经过训练可以重新建立语言文本。网络用文字表示,有必要猜测相邻位置的输入字。
训练完成后,word2vec模型可用于将每个单词映射到矢量,该矢量可用于表示单词和单词之间的关系。该向量为神经网络之隐藏层。总之,word2vec使用一层神经网络将one-hot 形式的单词向量映射到分布式形式的单词向量。word2vec涉及到很多自然语言处理的名词。第一个是单词vector。这可以很容易地用于各种后续计算,即单词矢量。词向量最简单的形式是one-hot形式;还有更复杂的分布式字矢量,而word2vec是用于学习该分布式字矢量的算法。
Word2vec是由Google开发的一个计算词向量的开源工具,它是一个浅层神经网络(如图1),神经网络模型包含输入层、输出层以及隐藏层。
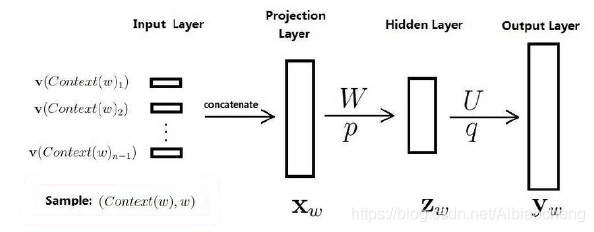
图1 神经网络模型
Word2vec的实质是用来计算词向量的CBOW模型和Skip-gram模型。
CBOW是一种根据上下文的词语预测当前词语的出现概率的模型。训练CBOW模型的输入数据是某个特征词的上下文相关的词相对应的词向量,其输出数据是这个特定词的词向量。在训练CBOW模型时,词向量只是个副产品,换句话说,词向量是CBOW模型的一个参数。训练开始的时候,词向量初始化为一个随机值,在模型训练的过程中,词向量进行不断地更新。投影层对其求和,也就是简单的向量加法。对于输出层,由于语料库中的词汇量是固定的C个,所以可以将模型的训练看作是多分类问题:对于给定特征,模型从C个分类中输出一个最近的。CBOW模型中上下文距离是可以自定义的,使用的是词袋模型,所以上下文中的词都是平等的,不需考虑其与关注词的距离。
Skip-Gram模型和CBOW模型正好相反,其输入数据是一个特定词的词向量,输出结果是输入的词对应的上下文词向量。Skip-Gram模型的实质是计算输入的词的输入向量 和目标词的输出向量之间的余弦相似度,并进行softmax归一化。
CBOW模型和Skip-Gram模型的原理图如图2。
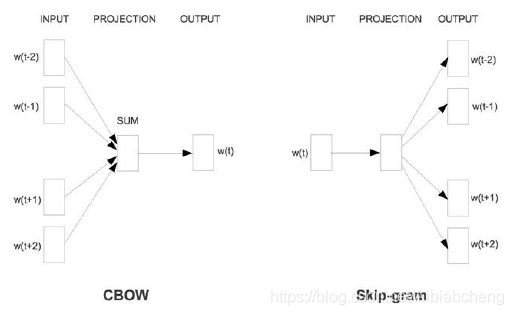
图2 CBOW模型和Skip-Gram模型的原理图
2.Word2vec训练
Word2vec在使用前需要线进行训练,本文训练使用的语料库是Wiki百科的中文语料库(1.61G,337336篇文章)。
语料库下载链接:https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2
(1)数据抽取。
下载的原始语料数据包是*-articles.xml.bz2格式的,需要对其进行处理,提取数据存入*.txt文件中。本文使用的提取方式是gensim.corpora中的WikiCorpus。代码如下。
import logging
import os.path
import sys
import warnings
warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim')
from gensim.corpora import WikiCorpus
if __name__ == '__main__':
program = os.path.basename(sys.argv[0]) # 得到文件名
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
if len(sys.argv) < 3:
print(globals()['__doc__'] % locals())
sys.exit(1)
inp, outp = sys.argv[1:3]
space = " "
i = 0
output = open("out.txt", "w", encoding='utf-8')
# gensim里的维基百科处理类WikiCorpus
wiki = WikiCorpus(inp, lemmatize=False, dictionary=[])
# 通过get_texts将维基里的每篇文章转换位1行text文本
# 并且去掉了标点符号等内容
for text in wiki.get_texts():
output.write(space.join(text) + "\n")
i = i + 1
if (i % 1000 == 0):
logger.info("Saved " + str(i) + " articles.")
output.close()
logger.info("Finished Saved " + str(i) + " articles.")(2)数据预处理。
提取后的预料中包含很多繁体字,需要将其转化为简体字;然后再对其进行结巴分词及去停用词处理。
中文繁体转成中文简体,使用的是OpenCC,它是一款开源的中文处理工具,支持字符级别的转换。该工具下载成功之后,双击opencc.exe文件,在当前目录下打开dos窗口,输入如下命令行:
opencc -i wiki_zh_1.6g.txt -o wiki_zh_simp.txt -c t2s.json对语料库进行分词,采用的结巴分词与去停留词等方法与【NLP】之 结巴分词-CSDN博客相同,在此不在赘述。
使用上述处理完毕的语料库对Word2vec进行训练,本文设置词向量维度为200维,上下文窗口大小为5,最小词频为5。核心代码如下。
import logging
import os.path
import sys
import multiprocessing
from gensim.corpora import WikiCorpus
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
if __name__ == '__main__':
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# check and process input arguments
if len(sys.argv) < 4:
print (globals()['__doc__'] % locals())
sys.exit(1)
inp, outp1, outp2 = sys.argv[1:4]
model = Word2Vec(LineSentence(inp), size=200, window=5, min_count=5, workers=2)
model.save(outp1)
model.wv.save_word2vec_format(outp2, binary=False)然后运行如下命令
python word2vec_model.py out.txt out.model out.vector3.用Word2vec将评论转为词向量
利用维基百科将Word2vec训练完成后,就得到了语料库中的相应词的词向量,将评论信息转化为词向量的实质是利用“键值对”的原理,将特定词的词向量取出。将评论中的中文词全部转化为词向量后,整条评论的向量值就是其所有分词向量的平均值。核心代码如下。
from gensim.models import Word2Vec
import codecs, sys
import pymysql
import numpy
numpy.set_printoptions(suppress=True)
fcoms = codecs.open('coms_all.txt', 'r', encoding="utf8")
w2v_model = Word2Vec.load('wiki.zh.1.6gr.model')
w = codecs.open('vec_all.txt', 'w', encoding="utf8")
size = 200
def count_vec_sentence():
line = fcoms.readline()
i = 0
id = 0
while line :
words = line.split(' ')
vec = numpy.zeros(size).reshape((1, size))
vec0 = numpy.zeros(size).reshape((1, size))
count = 0
flag = True
for item in words :
word = item.strip()
if word.__len__() > 0 :
if flag :
attitude = word
flag = False
else :
try :
vec += w2v_model[word].reshape((1, size))
count += 1
except KeyError :
# print('==== fault: ', word)
continue
if i % 100 == 0 :
print(i)
i += 1
line = fcoms.readline()
if count != 0 :
vec /= count
w.write(attitude + ' ')
w.write(str(vec)[2:-2])
w.write('$')
if '__main__' == __name__:
count_vec_sentence()词向量结果
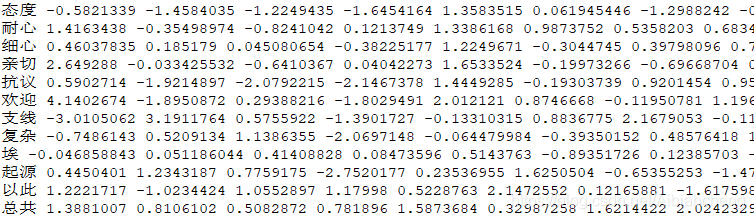
















 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











