







梯度下降法
首先引出梯度的定义:
梯度是一个矢量,其方向上的方向导数最大,其值的大小正好是此最大方向导数
最优化问题在机器学习中有非常重要的地位,很多机器学习算法最后都归结为求解最优化问题。在各种最优化算法中,梯度下降法是最简单、最常见的一种,在深度学习的训练中被广为使用。
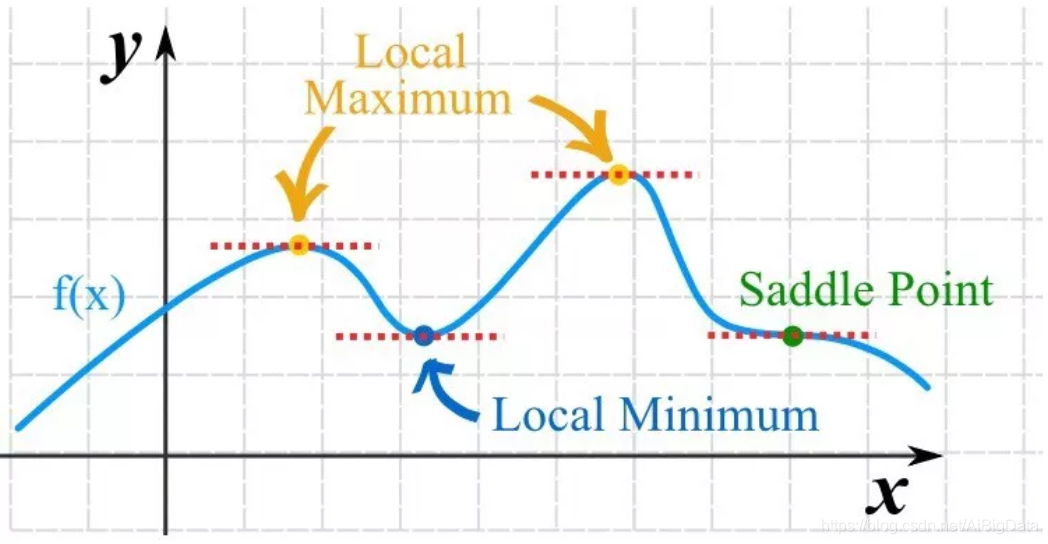
最优化问题
最优化问题是求解函数极值的问题,包括极大值和极小值。相信所有的读者对这个问题都不陌生,在初中时我们就学会了求解二次函数的极值(抛物线的顶点),高中时学习了幂函数,指数函数,对数函数,三角函数,反三角函数等各种类型的函数,求函数极值的题更是频频出现。这些方法都采用了各种各样的技巧,没有一个统一的方案。
真正的飞跃发生在大学时,微积分为我们求函数的极值提供了一个统一的思路:找函数的导数等于0的点,因为在极值点处,导数必定为0。这样,只要函数的可导的,我们就可以用这个万能的方法解决问题,幸运的是,在实际应用中我们遇到的函数基本上都是可导的。
在机器学习之类的实际应用中,我们一般将最优化问题统一表述为求解函数的极小值问题,即:
m
i
n
x
f
(
x
)
min_xf(x)
minxf(x)
其中x称为优化变量,f称为目标函数。极大值问题可以转换成极小值问题来求解,只需要将目标函数加上负号即可:
m
a
x
x
f
(
x
)
<
=
>
m
i
n
x
−
f
(
x
)
max_xf(x)<=>min_x-f(x)
maxxf(x)<=>minx−f(x)
有些时候会对优化变量x有约束,包括等式约束和不等式约束,它们定义了优化变量的可行域,即满足约束条件的点构成的集合。在这里我们先不考虑带约束条件的问题。
一个优化问题的全局极小值
x
∗
x^*
x∗是指对于可行域里所有的x,有:
f
(
x
∗
)
≤
f
(
x
)
f(x^*)\leq f(x)
f(x∗)≤f(x)
即全局极小值点处的函数值不大于任意一点处的函数值。局部极小值
x
∗
x^*
x∗定义为存在一个
δ
\delta
δ邻域,对于在邻域内:
∣
∣
x
−
x
∗
∣
∣
≤
δ
||x-x^*||\leq \delta
∣∣x−x∗∣∣≤δ
并且在可行域内的所有x,有:
f
(
x
∗
)
≤
f
(
x
)
f(x^*)\leq f(x)
f(x∗)≤f(x)
即局部极小值点处的函数值比一个局部返回内所有点的函数值都小。在这里,我们的目标是找到全局极小值。不幸的是,有些函数可能有多个局部极小值点,因此即使找到了导数等于0的所有点,还需要比较这些点处的函数值。
导数与梯度
由于实际应用中一般都是多元函数,因此我们跳过一元函数,直接介绍多元函数的情况。梯度是导数对多元函数的推广,它是多元函数对各个自变量偏导数形成的向量。多元函数的梯度定义为:
∇
f
(
x
)
=
(
∂
f
∂
x
1
,
.
.
.
,
∂
f
∂
x
n
)
T
\nabla f(x)=(\frac{\partial f}{\partial} x_1,...,\frac{\partial f}{\partial x_n})^T
∇f(x)=(∂∂fx1,...,∂xn∂f)T
其中
∇
\nabla
∇称为梯度算子,它作用于一个多元函数,得到一个向量。下面是计算函数梯度的一个例子:
∇
(
x
2
+
x
y
−
y
2
)
=
(
2
x
+
y
,
x
−
2
y
)
\nabla(x^2+xy-y^2)=(2x+y,x-2y)
∇(x2+xy−y2)=(2x+y,x−2y)
可导函数在某一点处取得极值的必要条件是梯度为0,梯度为0的点称为函数的驻点,这是疑似极值点。需要注意的是,梯度为0只是函数取极值的必要条件而不是充分条件,即梯度为0的点可能不是极值点。
至于是极大值还是极小值,要看二阶导数/Hessian矩阵,Hessian矩阵我们将在后面的文章中介绍,这是由函数的二阶偏导数构成的矩阵。这分为下面几种情况:
如果Hessian矩阵正定,函数有极小值
如果Hessian矩阵负定,函数有极大值
如果Hessian矩阵不定,则需要进一步讨论
这和一元函数的结果类似,Hessian矩阵可以看做是一元函数的二阶导数对多元函数的推广。一元函数的极值判别法为,假设在某点处导数等于0,则:
如果二阶导数大于0,函数有极小值
如果二阶导数小于0,函数有极大值
如果二阶导数等于0,情况不定
在这里我们可能会问:直接求函数的导数/梯度,然后令导数/梯度为0,解方程,问题不就解决了吗?事实上没这么简单,因为这个方程可能很难解。比如下面的函数:
f
(
x
,
y
)
=
x
3
−
2
x
2
+
e
x
y
−
y
3
+
10
y
2
+
100
s
i
n
(
x
y
)
f(x,y)=x^3-2x^2+e^{xy}-y^3+10y^2+100sin(xy)
f(x,y)=x3−2x2+exy−y3+10y2+100sin(xy)
我们分别对x和y求偏导数,并令它们为0,得到下面的方程组:
{
3
x
2
−
4
x
+
y
e
x
y
+
100
y
c
o
n
(
x
y
)
=
0
x
e
x
y
−
3
y
2
+
20
y
+
x
c
o
s
(
x
y
)
=
0
\begin{cases} 3x^2-4x+ye^{xy}+100ycon(xy)=0\\ xe^{xy}-3y^2+20y+xcos(xy)=0 \end{cases}
{3x2−4x+yexy+100ycon(xy)=0xexy−3y2+20y+xcos(xy)=0
这个方程非常难以求解,对于有指数函数,对数函数,三角函数的方程,我们称为超越方程,求解的难度并不比求极值本身小。
精确的求解不太可能,因此只能求近似解,这称为数值计算。工程上实现时通常采用的是迭代法,它从一个初始点
x
0
x_0
x0开始,反复使用某种规则从
x
k
x_k
xk移动到下一个点
x
k
1
x_{k1}
xk1,构造这样一个数列,直到收敛到梯度为0的点处。即有下面的极限成立:
lim
k
−
>
+
∞
∇
f
(
x
k
)
=
0
\lim_{k->+\infty}\nabla f(x_k)=0\\
k−>+∞lim∇f(xk)=0
这些规则一般会利用一阶导数信息即梯度;或者二阶导数信息即Hessian矩阵。这样迭代法的核心是得到这样的由上一个点确定下一个点的迭代公式:
x
k
+
1
=
h
(
x
k
)
x_{k+1}=h(x_k)
xk+1=h(xk)
这个过程就像我们处于山上的某一位置,要到山底找水喝,因此我们必须到达最低点处:

此时我们没有全局信息,根本就不知道哪里是地势最低的点,只能想办法往山下走,走 一步看一步。刚开始我们在山上的某一点处,每一步,我们都往地势更低的点走,以期望能走到山底。
推导过程
梯度下降法(gradient descent)或最速下降法(steepest descent)是无解无约束最优化问题的一种最常见的方法,具有实现简单的优点。梯度下降法是迭代算法,每一步需要求解目标函数的梯度向量。
假设f(x)是
R
n
R^n
Rn上具有一阶连续偏导的函数。要求解的无约束最优化问题是
min
x
∈
R
n
f
(
x
)
(A.1)
\min_{x\in R^n} f(x) \tag{A.1}\\
x∈Rnminf(x)(A.1)
x
∗
x^*
x∗表示目标函数f(x)的极小点。
梯度下降法是一种迭代算法。选取适当的初值 x ( 0 ) x^{(0)} x(0),不断迭代,更新x的值,进行目标函数的极小化,直到收敛。由于负梯度方向是使函数值下降最快的方向,在迭代的每一步,以负梯度方向更新x的值,从而达到减少函数值的目的。
由于f(x)具有一节连续偏导数,若第k次迭代值为
x
(
k
)
x^{(k)}
x(k),则可将f(x)在
x
(
k
)
x^{(k)}
x(k)附近进行一阶泰勒展开:
f
(
x
)
=
f
(
x
(
k
)
)
+
g
k
T
(
x
−
(
x
(
k
)
)
(A.2)
f(x)=f(x^{(k)})+g^T_k(x-(x^{(k)})\tag{A.2}
f(x)=f(x(k))+gkT(x−(x(k))(A.2)
这里,
g
k
=
g
(
x
(
k
)
)
=
∇
f
(
x
(
k
)
)
g_k=g(x^{(k)})=\nabla f(x^{(k)})
gk=g(x(k))=∇f(x(k))为f(x)在
x
(
k
)
x^{(k)}
x(k)的梯度。
求出第k+1次迭代值
x
(
k
+
1
)
x^{(k+1)}
x(k+1):
x
(
k
+
1
)
←
x
(
k
)
+
λ
k
p
k
(A.3)
x^{(k+1)}\leftarrow x^{(k)}+\lambda_kp_k \tag{A.3}
x(k+1)←x(k)+λkpk(A.3)
其中,
p
k
p_k
pk是搜索方向,取负梯度方向
p
k
=
−
∇
f
(
x
(
k
)
)
,
λ
k
p_k=-\nabla f(x^{(k)}),\lambda_k
pk=−∇f(x(k)),λk是步长,由一维搜索确定,即
λ
k
\lambda_k
λk使得
注:此时 g k T ( x − ( x ( k ) ) 中 g k T 与 ( x − ( x ( k ) ) 是 相 反 方 向 g^T_k(x-(x^{(k)})中g^T_k与(x-(x^{(k)})是相反方向 gkT(x−(x(k))中gkT与(x−(x(k))是相反方向
f ( x ( k ) + λ k p k ) = min λ ≥ 0 f ( x ( k ) + λ p k ) (A.4) f(x^{(k)}+\lambda_kp_k)=\min_{\lambda\geq0}f(x^{(k)}+\lambda p_k) \tag{A.4} f(x(k)+λkpk)=λ≥0minf(x(k)+λpk)(A.4)
梯度下降法算法如下:
算法A.1(梯度下降法)
输入:目标函数f(x),梯度函数g(x)= ∇ f ( x ) \nabla f(x) ∇f(x),计算精度 ϵ \epsilon ϵ;
输出:f(x)的极小值 x ∗ x^* x∗
(1)取初始值 x ( 0 ) ∈ R n x^{(0)}\in R^n x(0)∈Rn,置k=0。
(2)计算 f ( x ( k ) ) f(x^{(k)}) f(x(k))。
(3)计算梯度 g k = g ( x ( k ) ) , g_k=g(x^{(k)}), gk=g(x(k)),当 ∣ ∣ g k ∣ ∣ < ϵ ||g_k||<\epsilon ∣∣gk∣∣<ϵ ,时,停止迭代,令 x ∗ = x ( k ) x^*=x^{(k)} x∗=x(k);否则,令 p k = − g ( x ( k ) ) , p_k=-g(x^{(k)}), pk=−g(x(k)),求 λ k \lambda_k λk,使
f ( x ( k ) + λ k p k ) = min λ ≥ 0 f ( x ( k ) + λ p k ) f(x^{(k)}+\lambda_kp_k)=\min_{\lambda\geq0}f(x^{(k)}+\lambda p_k) f(x(k)+λkpk)=λ≥0minf(x(k)+λpk)
(4)置 x ( k + 1 ) = x ( k ) + λ k p k x^{(k+1)}=x^{(k)}+\lambda_kp_k x(k+1)=x(k)+λkpk,计算 f ( x ( k + 1 ) ) f(x^{(k+1)}) f(x(k+1))当 ∣ ∣ f ( x ( k + 1 ) − f ( x ( k ) ∣ ∣ < ϵ ||f(x^{(k+1)}-f(x^{(k)}||<\epsilon ∣∣f(x(k+1)−f(x(k)∣∣<ϵ或 ∣ ∣ x ( k + 1 ) − x ( k ) ∣ ∣ < ϵ ||x^{(k+1)}-x^{(k)}||<\epsilon ∣∣x(k+1)−x(k)∣∣<ϵ时,停止迭代,令 x ∗ = x ( k + 1 ) x^*=x^{(k+1)} x∗=x(k+1).
(5)否则,置k=k+1,转(3)。
当目标函数是凸函数时,梯度下降法的解是全局最优解。一般情况下,其解不保证是全局最优解。梯度下降法的收敛速度为未必是很快的。
实现细节问题
下面我们介绍梯度下降法实现时的一些细节问题,包括初始值的设定,学习率的设定,下面分别进行介绍。
初始值的设定
一般的,对于不带约束条件的优化问题,我们可以将初始值设置为0,或者设置为随机数,对于神经网络的训练,一般设置为随机数,这对算法的收敛至关重要[1]。
学习率的设定
学习率设置为多少,也是实现时需要考虑的问题。最简单的,我们可以将学习率设置为一个很小的正数,如0.001。另外,可以采用更复杂的策略,在迭代的过程中动态的调整学习率的值。比如前1万次迭代为0.001,接下来1万次迭代时设置为0.0001。
面临的问题
在实现时,梯度下降法可能会遇到一些问题,典型的是局部极小值和鞍点问题,下面分别进行介绍。
局部极小值
有些函数可能有多个局部极小值点,下面是一个例子:
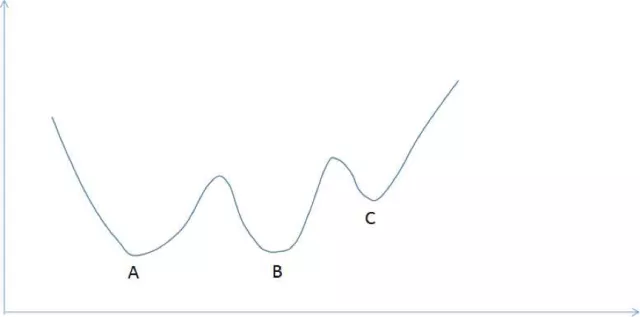
这张图中的函数有3个局部极值点,分别是A,B和C,但只有A才是全局极小值,梯度下降法可能迭代到B或者C点处就终止。
鞍点
鞍点是指梯度为0,Hessian矩阵既不是正定也不是负定,即不定的点。下面是鞍点的一个例子,假设有函数: x 2 − y 2 x^2-y^2 x2−y2,显然在(0, 0)这点处不是极值点,但梯度为0,下面是梯度下降法的运行结果:
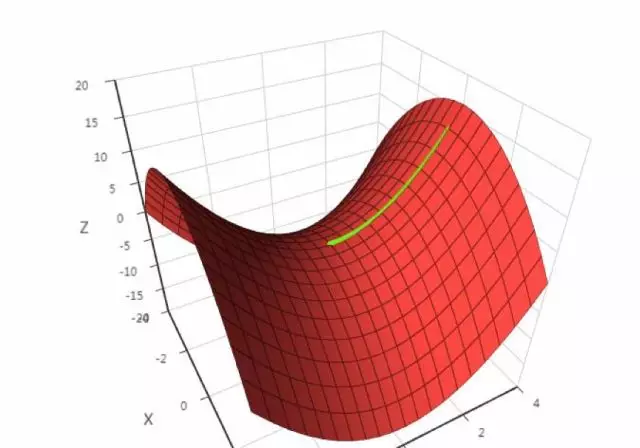
在这里,梯度下降法遇到了鞍点,认为已经找到了极值点,从而终止迭代过程,而这根本不是极值点。对于怎么逃离局部极小值点和鞍点,有一些解决方案。
随机梯度下降法(Stochastic Gradient Descent)
随机梯度下降法,其实和批量梯度下降法原理类似,区别在与求梯度时没有用所有的样本的数据,而是仅仅选取一个样本来求梯度。
随机梯度下降法,和批量梯度下降法是两个极端,一个采用所有数据来梯度下降,一个用一个样本来梯度下降。自然各自的优缺点都非常突出。对于训练速度来说,随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快,而批量梯度下降法在样本量很大的时候,训练速度不能让人满意。对于准确度来说,随机梯度下降法用于仅仅用一个样本决定梯度方向,导致解很有可能不是最优。对于收敛速度来说,由于随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。
小批量梯度下降法(Mini-batch Gradient Descent)
对于有些机器学习问题,我们的目标函数是对样本的损失函数。假设训练样本集有N个样本,训练时优化的目标是这个数据集上的平均损失函数:
L
(
w
)
=
1
N
∑
i
=
1
N
L
(
w
,
x
i
,
y
i
)
L(w)=\frac{1}{N}\sum_{i=1}^NL(w,x_i,y_i)
L(w)=N1i=1∑NL(w,xi,yi)
其中
L
(
w
,
x
i
,
y
i
)
L(w,x_i,y_i)
L(w,xi,yi)是对单个训练样本
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)的损失函数,w是需要学习的参数。如果训练时每次都用所有样本计算梯度并更新,成本太高,作为改进可以每次迭代时选取一批样本,将损失函数定义在这些样本上。
批量随机梯度下降法在每次迭代中使用上面目标函数的随机逼近值,即只使用M<<N个样本来近似计算损失函数。在每次迭代时要优化的目标函数变为:
L
(
w
)
≈
1
M
∑
i
=
1
M
L
(
w
,
x
i
,
y
i
)
L(w)\approx\frac{1}{M}\sum_{i=1}^ML(w,x_i,y_i)
L(w)≈M1i=1∑ML(w,xi,yi)
已经证明,随机梯度下降法在数学期望的意义下收敛,即随机采样产生的梯度的期望值是真实的梯度。因为每次迭代时的目标函数实际上是不一样的,因此随机梯度下降法并不能保证每次迭代时函数值一定下降。
变种
梯度下降法有大量的变种,它们都只利用之前迭代时的梯度信息来构造每次的更新值,下面我们分别进行介绍。
迭代公式加上动量项
最直接的改进是为迭代公式加上动量项,动量项累积了之前的权重更新值,加上此项之后的参数更新公式为:
X
t
+
1
=
X
t
+
V
t
+
1
X_{t+1}=X_t+V_{t+1}
Xt+1=Xt+Vt+1
其中
V
t
+
1
V_{t+1}
Vt+1是动量项,它取代了之前的梯度项。动量项的计算公式为:
V
t
+
1
=
−
α
∇
f
(
x
1
)
+
μ
V
t
V_{t+1}=-\alpha \nabla f(x_1)+\mu V_t
Vt+1=−α∇f(x1)+μVt
动量项累积了之前的梯度信息,类似于保持行走时的惯性,以避免来回震荡,加快收敛速度。
AdaGrad为自适应梯度
AdaGrad为自适应梯度,即adaptive gradient算法[2],是梯度下降法最直接的改进。唯一不同的是,AdaGrad根据前几轮迭代时的历史梯度值来调整学习率,参数更新公式为:
(
x
t
+
1
)
i
=
(
x
t
)
i
−
α
(
g
i
)
i
∑
j
=
1
t
(
(
g
j
)
i
)
2
+
ϵ
(x_{t+1})_i=(x_t)_i-\alpha\frac{(g_i)_i}{\sqrt{\sum_{j=1}^t((g_j)_i)^2+\epsilon}}
(xt+1)i=(xt)i−α∑j=1t((gj)i)2+ϵ(gi)i
其中
α
\alpha
α是学习因子,
g
t
g_t
gt是第t次迭代时的参数梯度向量,
ϵ
\epsilon
ϵ是一个很小的正数,为了避免除0操作,下标i表示向量的分量。和标准梯度下降法唯一不同的是多了分母中的这一项,它积累了到本次迭代为止梯度的历史值信息用于用于生成梯度下降的系数值。
为什么分母要进行平方根的原因是去掉平方根操作算法的表现会大打折扣。
Adagrad的一大优势时可以避免手动调节学习率,比如设置初始的缺省学习率为0.01,然后就不管它,另其在学习的过程中自己变化。当然它也有缺点,就是它计算时要在分母上计算梯度平方的和,由于所有的参数平法必为正数,这样就造成在训练的过程中,分母累积的和会越来越大。这样学习到后来的阶段,网络的更新能力会越来越弱,能学到的更多知识的能力也越来越弱,因为学习率会变得极其小,为了解决这样的问题又提出了Adadelta算法。
AdaDelta算法[3]
- 在一个窗口
w中对梯度进行求和,而不是对梯度一直累加 - 因为存放 w 之前的梯度是低效的,所以可以用对先前所有梯度均值(使用RMS即均方根值实现)的一个指数衰减作为代替的实现方法。
更新公式如下:
① 将累计梯度信息从全部历史梯度变为当前时间向前的一个窗口期内的累积:
E
[
g
2
]
t
=
ρ
∗
E
[
g
2
]
t
−
1
+
(
1
−
ρ
)
∗
g
t
2
E[g^2]_t=\rho * E[g^2]_{t-1}+(1-\rho)* g_t^2
E[g2]t=ρ∗E[g2]t−1+(1−ρ)∗gt2
相当于历史梯度信息的累计乘上一个衰减系数
ρ
\rho
ρ,然后用
(
1
−
ρ
)
(1-\rho)
(1−ρ)作为当前梯度的平方加权系数相加。
②然后将上述
E
[
g
t
2
]
E[g^2_t]
E[gt2]开放后,作为每次迭代更新后的学习率衰减系数。
x
t
+
1
=
x
t
−
η
E
[
g
2
]
t
+
ϵ
∗
g
t
x_{t+1}=x_t-\frac{\eta}{\sqrt{E[g^2]_t+\epsilon}}*g_t
xt+1=xt−E[g2]t+ϵη∗gt
记作:
R
M
S
(
g
t
)
=
E
[
g
2
]
t
+
ϵ
RMS(g_t)=\sqrt{E[g^2]_t+\epsilon}
RMS(gt)=E[g2]t+ϵ,其中ϵ是为了防止分母为0而加上的一个极小值。
这种更新方法解决了对历史梯度一直累加而导致学习率一直下降的问题,当时还是需要自己选择初始的学习率。
Adam算法[4]全称为adaptive moment estimation
它由梯度项构造了两个向量m和v,它们的初始值为0,更新公式为:
(
m
t
)
i
=
β
1
(
m
t
−
1
)
i
+
(
1
−
β
1
)
(
g
t
)
i
(
v
t
)
i
=
β
2
(
m
t
−
1
)
i
+
(
1
−
β
2
)
(
g
t
)
i
2
(m_t)_i=\beta_1(m_{t-1})_i+(1-\beta_1)(g_t)_i\\ (v_t)_i=\beta_2(m_{t-1})_i+(1-\beta_2)(g_t)_i^2\\
(mt)i=β1(mt−1)i+(1−β1)(gt)i(vt)i=β2(mt−1)i+(1−β2)(gt)i2
其中
β
1
,
β
2
\beta_1,\beta_2
β1,β2是人工指定的参数,i为向量的分量下标。依靠这两个值构造参数的更新值,参数的更新公式为:
(
x
t
+
1
)
i
=
(
x
t
)
i
−
α
1
−
(
β
2
)
i
t
1
−
(
β
2
)
i
t
(
m
t
)
i
(
v
t
)
i
+
ϵ
(x_{t+1})_i=(x_t)_i-\alpha\frac{\sqrt{1-(\beta_2)^t_i}}{1-(\beta_2)^t_i}\frac{(m_t)_i}{\sqrt{(v_t)_i}+\epsilon}
(xt+1)i=(xt)i−α1−(β2)it1−(β2)it(vt)i+ϵ(mt)i
在这里,用m代替梯度,用v来构造学习率。
NAG算法是一种凸优化方法,由Nesterov提出。和标准梯度下降法的权重更新公式类似,NAG算法构造一个向量v,初始值为0。v的更新公式为:
梯度下降法和最小二乘法
梯度下降法和最小二乘法相比,梯度下降法需要选择步长,而最小二乘法不需要。梯度下降法是迭代求解,最小二乘法是计算解析解。如果样本量不算很大,且存在解析解,最小二乘法比起梯度下降法要有优势,计算速度很快。但是如果样本量很大,用最小二乘法由于需要求一个超级大的逆矩阵,这时就很难或者很慢才能求解解析解了,使用迭代的梯度下降法比较有优势。
原文地址:https://mp.weixin.qq.com/s/lqwUkimO4irkIZmAnp0bcg
参考文献:
[1] I. Sutskever, J. Martens, G. Dahl, and G. Hinton. On the Importance of Initialization and Momentum in Deep Learning. Proceedings of the 30th International Conference on Machine Learning, 2013.
[2] Duchi, E. Hazan, and Y. Singer. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. The Journal of Machine Learning Research, 2011.
[3] M. Zeiler. ADADELTA: An Adaptive Learning Rate Method. arXiv preprint, 2012.
[4] D. Kingma, J. Ba. Adam: A Method for Stochastic Optimization. International Conference for Learning Representations, 2015.
[5] T. Tieleman, and G. Hinton. RMSProp: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning.Technical report, 2012.
[6] Rumelhart, David E.; Hinton, Geoffrey E.; Williams, Ronald J. (8 October 1986). Learning representations by back-propagating errors. Nature. 323 (6088): 533–536.
[7] L. Bottou. Stochastic Gradient Descent Tricks. Neural Networks: Tricks of the Trade. Springer, 2012.
[8] 李航:《统计学习方法(第二版)》,清华大学出版社














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









