






浅浅叙述匈牙利算法
目录
基本思路
匈牙利法的基本思路:对费用矩阵C的行和列减去某个常数,将C化为有n个位于不同行不同列的零元素,令这些零元素对应的变量取1,其余变量取0,即得到指派问题的最优解。
匈牙利法是基于指派问题的标准型的,标准型需满足以下3个条件:
(1)目标函数求min;
(2)效率矩阵为n阶方阵;
(3)效率矩阵中所有元素Cij20,且为常数。
计算步骤
匈牙利法的计算步骤:
(1)变换效率矩阵C,使每行每列至少有一个0,变换后的矩阵记为B
●行变换:找出每行min值,该行各元素减去它;
●列变换:找出每列min值,该列各元素减去它;
●若某行列已有0元素,则不用减。
来一道简单例题
如何安排工作使得成本最低?(注:①每个人只能做一项工作;②每项工作只能分配给一个人做;③所有工作都要安排完。)
表1 不同人对每一项工作收费表
|
| 第一件 | 第二件 | 第三件 | 第四件 | 第五件 |
| 甲 | 12 | 7 | 9 | 7 | 9 |
| 乙 | 8 | 9 | 6 | 6 | 6 |
| 丙 | 7 | 17 | 12 | 14 | 9 |
| 丁 | 15 | 14 | 6 | 6 | 10 |
| 戊 | 4 | 10 | 10 | 10 | 9 |
1.1 符号规定
1.2目标函数
1.3约束条件

1.4代码
from scipy.optimize import linear_sum_assignment
#由于python有scipy库的支持,已经有了现成的匈牙利方法,可以直接调用就行。
import numpy as np
#在使用的过程中,也需要调用numpy库使矩阵的建立更简单
cost_mat = np.array([[12, 7, 9, 7, 9],
[8, 9, 6, 6, 6],
[7, 17, 12, 14, 9],
[15, 14, 6, 6, 10],
[4, 10, 7, 10, 9]])
work_idx_ls, pokeman_idx_ls = linear_sum_assignment(cost_mat)
cost = 0
work = ['第一件', '第二件', '第三件', '第四件', "第五件"]
pokeman = ["甲", "乙", "丙", '丁', "戊"]
for work_idx, poken_idx in zip(work_idx_ls, pokeman_idx_ls):
print(f"工作 {work[work_idx]} 指派给 工人 {pokeman[poken_idx]}")
cost += cost_mat[work_idx][poken_idx]
print(f"最后消耗 {cost}元!")
#匈牙利法具体的python求解过程放在了文章末尾的py代码段里,可以自行查看
#实际中可以直接使用scipy库进行求解
那么现在,让我们来点真家伙吧!
废话不多说,直接上题
2013年国赛b题第二问
题目复述
对于重大突发事件,需要调度全区20个交巡警服务平台的警力资源,对进出该区的13条交通要道实现快速全封锁。实际中一个平台的警力最多封锁一个路口,请给出该区交巡警服务平台警力合理的调度方案。
————————————此处应该有数据表格,原题数据放文章结尾——————————
基本假设
1、假设每个突发事件需要处理的时间相同。
2、假设在出警过程中匀速行驶。
3、 假设嫌疑犯逃亡时匀速行驶。
4、假设嫌疑犯逃离的速度不会大于警察迫捕速度。
问题分析
第二小问要求制定A区交巡警服务平台警力合理的调度方案,调度全区20个交巡警服务平台的警力资源,对进出该区的13条交通要道实现快速封锁。考虑实际中一个平台的警,力至多能够封锁一个路口,对每个路口分配-一个平台警力进行围堵。
当突发事件发生时, 全区各个服务点对于交通要道的封锁是同步进行的。由于距离原因,每个服务点对要封锁的交通要道所需时间是不同的,最后一个交通要道完成封锁才算对全区的封锁完成。本文考虑按最后完成对交通要道封锁的时间作为标准,选择最快完成全区封锁的调度方案。考虑对20个平台与13个交通要道进行遍历,计算出每种组合中平台到达交通要道的最大时间,将每种组合的最大时间进行比较,选取值最小的组合作为交巡警服务平台警力的调度方案。
本文考虑采用 0-1整数规划的方法,对20个平台分配13个交通要道以获得最合理的调度方案。对每个平台分配一个交通要道,并在分配完这些任务后,使完成全部任务的总时间为最小。
符号说明

模型的建立与求解
模型建立思路
制定合理的调度方案,使全区20个交巡警服务平台的警力快速封锁该区的13条交通要道,建立0-1整数规划中的不平衡的指派类型模型求解此问。通过建立目标函数和约束条件,利用匈牙利算法寻找最优解,即选取完成时间最少的调度方案。
考虑一个平台的警力最多封锁一个路口,调度A区20各个交巡警服务平台的警力资源对13条
交通要道进行全封锁。全封锁是参与道路封锁的各交巡警服务平台同时进行的以完成封锁自标为标准结果。但由于各平台与所要封锁道路的距离的不同,在警车时速相同的情况下,各平台的出勤时间是不同的,到达所要封锁自的地的时间不同,即结束封锁时间不同。计算茁每个方案的结束时间,选取完成时间最少的方案作为最佳方案。
模型建立的过程
建立目标函数本文根据0-1整数规划中不平衡的指派类型求解此问,将A区20个交巡警服务平台的警力资源分配13条交通要道以实现快速封锁,设第i个服务点完成第j条交通要道的封锁,给每条交通要道分配一个服务点进行封锁管理,并要求封锁完成,以使完成全部任务的总时间为最小,以此建立目标函数minZ=max T 式中T表示时间。
建立0-1整数规划模型
①每个服务点的警力最多封锁一个交通要道,即>xy = 1,j=1,2.... ,
②每个交通要道为避免警力资源浪费而只需一个服务点的平台警力,
即x, =1,i=1,2...n
③对每个交通要道有无服务点的警力封锁判断,即x, = 0,1,其中0为
该交通要道没有警力封锁,1为该交通要道有警力封锁。

对目标函数进行整合,最后最终的函数为:
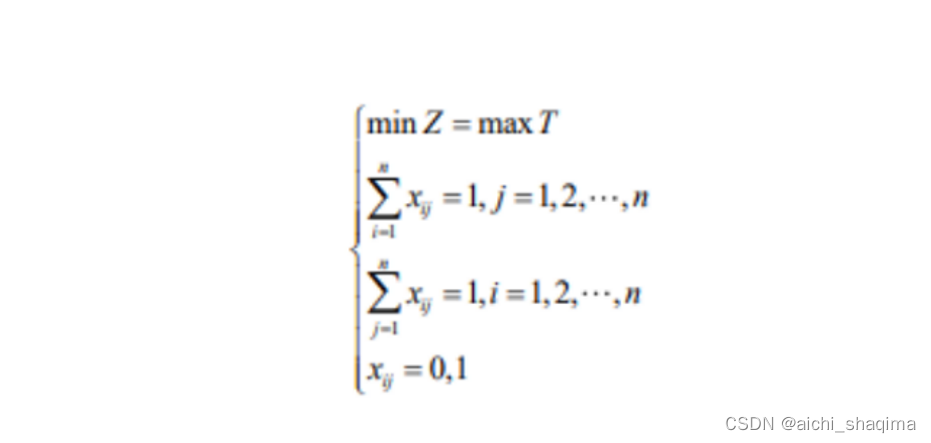
运用匈牙利方法:
这个时候我们再来使用刚刚提到的匈牙利法来进行求解
这个时候遇到一个问题:
20个巡警和13个交通路口无法构成nx n的矩阵,无法构成方阵,则无法进行匈牙利法的求解
解决问题的方法:我们补7列0向量,让其满足20x 20的方阵,由于补足的列为0,则相当于无用工作,不影响最后的结果。
这个题中
1,要求最小值
2,所有值都是正数
3,补完以后是方阵
所以可以用匈牙利法来做
针对0- 1整数规划中不平衡的指派问题利用匈牙利法求解,步骤如下:
(1)将系数矩阵标准化,并变换系数矩阵,使其各行各列中都出现0元素。将20个交巡警服务平台分别与13个交通要道的最短距离列为系数矩阵Cij,i=1,2...2.0.j=1.2..13.将Cj化为标准型,增加7列虚拟工作0,矩阵的阶数为20。
(2)然后再将Cij系数矩阵带入python的程序进行求解即可
代码实现
from json.encoder import INFINITY
import numpy as np
import xlrd
data = xlrd.open_workbook('2011B.xls')
#print("sheets:" + str(data.sheet_names())) #打印sheets名
table1 = data.sheet_by_name('全市交通路口节点数据')
loc = []
#节点位置列表
w = []
#发案率列表
loc.append([0, 0])
w.append(0.0) # 为使索引值和节点编号对应,填入一个数据
#读入A区各节点的坐标数据
for k in range(1, 93):
x = table1.cell(k, 1).value #注意,excel里的计数是从0开始的,和图像化界面里显示的不同
y = table1.cell(k, 2).value
loc.append([x, y])
w.append(table1.cell(k, 4).value)
table2 = data.sheet_by_name('全市交通路口的路线')
distance = np.zeros((93, 93), dtype=np.float)
for i in range(1, 93):
for j in range(1, 93):
if i == j:
distance[i, j] = 0.0
else:
distance[i, j] = INFINITY
#路程矩阵
for k in range(1, table2.nrows):
i = int(table2.cell(k, 0).value)
j = int(table2.cell(k, 1).value)
#print(i, j)
if i <= 92 and j <= 92:
distance[i, j] = np.sqrt((loc[i][0]-loc[j][0])**2 + (loc[i][1]-loc[j][1])**2)
distance[j, i] = np.sqrt((loc[i][0]-loc[j][0])**2 + (loc[i][1]-loc[j][1])**2)
#最短距离
for k in range(1, 93):
for i in range(1, 93):
for j in range(1, 93):
if distance[i, k] + distance[k, j] < distance[i, j]:
distance[i, j] = distance[i, k] + distance[k, j]
time = np.zeros((93, 93), dtype=np.float)
for i in range(1, 93):
for j in range(1, 93):
time[i, j] = distance[i, j]/10
filename = 'rask2.txt'
pingtai = range(1, 21)
table3 = data.sheet_by_name('全市区出入口的位置')
chukou = []
for k in range(1, 14):
#print(int(table3.cell(k, 2).value))
chukou.append(int(table3.cell(k, 2).value))
#创建文档写入数据
with open(filename, 'w') as f:
for i in pingtai:
for j in chukou:
f.write('%.4f' % time[i, j] +",")
f.write("\n")
from scipy.optimize import linear_sum_assignment
import numpy as np
cost_mat = np.array([[22.2362,16.0285,9.2868,19.2934,21.0962,22.5018,22.8932,19.0012,19.5158,12.0834,5.8809,11.8501,4.8852,0,0,0,0,0,0,0],
[20.4639,14.1297,7.3881,17.3947,19.1975,20.6030,21.1210,17.2289,17.7436,10.3112,3.9822,10.3095,6.0351,0,0,0,0,0,0,0],
[18.3523,12.7672,6.0256,16.0322,17.8350,19.2405,19.0093,15.1173,15.6319,8.1996,6.0938,8.1979,4.3934,0,0,0,0,0,0,0],
[21.9974,15.0085,8.2669,18.2735,20.0763,21.4818,22.6544,16.2269,15.5353,8.1030,4.8610,7.3959,0.3500,0,0,0,0,0,0,0],
[17.6282,12.9696,6.2280,16.2346,17.7495,19.1551,18.2852,11.3069,10.6153,3.1829,9.4211,2.4758,5.2551,0,0,0,0,0,0,0],
[17.6588,13.0002,6.2586,16.2652,17.7801,19.1856,18.3158,11.3375,10.6459,3.2135,9.4517,2.5064,5.3373,0,0,0,0,0,0,0],
[14.9149,10.9012,4.1596,14.1662,15.0363,16.4418,15.5720,8.5702,8.0155,0.5831,7.3527,1.2902,7.9917,0,0,0,0,0,0,0],
[14.0925,9.4339,2.6923,12.6989,14.2138,15.6194,14.7496,10.2280,10.4932,3.0608,5.8854,3.0995,8.6773,0,0,0,0,0,0,0],
[13.0107,8.2742,1.5325,11.5392,13.1320,14.5376,13.6678,9.7757,10.7244,3.4923,4.7257,4.1994,9.3367,0,0,0,0,0,0,0],
[7.5866,12.7757,6.9567,9.5107,7.7079,9.1135,8.2436,14.1949,15.1435,7.9114,10.1498,8.6186,14.7608,0,0,0,0,0,0,0],
[3.7914,8.3373,11.3950,5.0723,3.2696,4.6751,3.8053,18.6332,19.5819,12.3498,14.5882,13.0569,19.1992,0,0,0,0,0,0,0],
[0.0000,11.9503,14.5433,8.6853,6.8825,6.4770,3.5916,21.7814,22.7301,15.4980,17.7364,16.2051,22.3474,0,0,0,0,0,0,0],
[5.9770,5.9733,12.7149,2.7083,0.9055,0.5000,2.3854,22.8083,23.7570,16.5249,16.1208,17.2320,21.3318,0,0,0,0,0,0,0],
[11.9503,0.0000,6.7417,3.2650,5.0677,6.4733,8.3587,18.0499,18.9167,11.4843,10.1475,12.1914,15.3585,0,0,0,0,0,0,0],
[17.0296,13.2981,6.5564,16.5630,17.1509,18.5565,17.6867,4.7518,5.7005,4.4015,9.7496,5.1086,11.8101,0,0,0,0,0,0,0],
[14.5433,6.7417,0.0000,10.0066,11.8094,13.2149,15.1003,11.3083,12.1750,4.7427,3.4059,5.4498,8.6169,0,0,0,0,0,0,0],
[21.8921,14.9032,8.1616,18.1682,19.9710,21.3765,22.5492,18.6571,19.5239,12.0915,4.7557,12.7986,7.8205,0,0,0,0,0,0,0],
[24.2472,18.5145,11.7728,21.7795,23.5822,24.9878,24.9042,21.0122,21.5268,14.0945,8.3669,13.6993,6.7344,0,0,0,0,0,0,0],
[22.5465,16.9615,10.2198,20.2264,22.0292,23.4348,23.2036,19.3115,19.8262,12.3938,7.6393,11.9986,5.0337,0,0,0,0,0,0,0],
[26.9458,21.2131,14.4714,24.4781,26.2809,27.6864,27.6029,23.0108,22.3192,14.8869,11.0656,14.1798,6.4489,0,0,0,0,0,0,0]])
work_idx_ls, pokeman_idx_ls = linear_sum_assignment(cost_mat)
cost = 0
work = ['a1', 'a2', 'a3', 'a4', "a5",'a6','a7','a8','a9','a10','a11','a12','a13']
pokeman = ["1", "2", "3", '4', "5",'6','7','8','9','10','11','12','13','14','15','16','17','18','19','20']
filename = '最后的结果.txt'
for work_idx, poken_idx in zip(work_idx_ls, pokeman_idx_ls):
print(f"交通 {work[work_idx]} 指派给 警察 {pokeman[poken_idx]}")
cost += cost_mat[work_idx][poken_idx]
print(f"最后消耗 {cost}时间!")
2011年数学建模国赛b题附件数据
https://download.csdn.net/download/aichi_shaqima/86438453















 4657
4657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









