






一、Tesseract训练
大体流程为:安装jTessBoxEditor -> 获取样本文件 -> Merge样本文件 –> 生成BOX文件 -> 定义字符配置文件 -> 字符矫正 -> 执行批处理文件 -> 将生成的traineddata放入tessdata中
1、用jTessBoxEditor把要训练样本图片文件合并成tif文件(样本图片一定要为有效的格式图片)
运行jTessBoxEditor程序,界面如下:

点击顶栏的Tools选项,选择Merge TIFF.. 进入你要训练的样本图片所在的目录,点击Ctrl+Alt+A,选择所有图片点击打开:
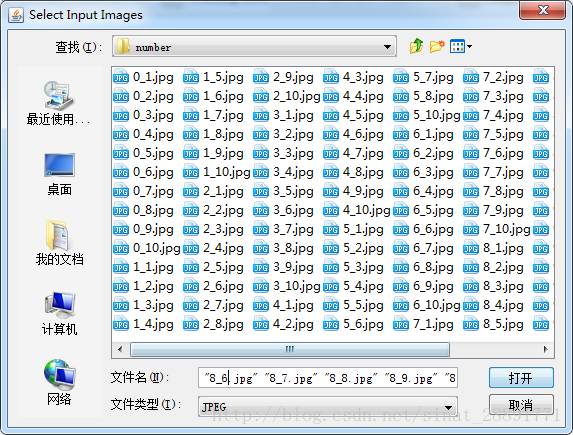
然后保存文件名到指定目录,我这里保存的文件名为: langyp.font.exp0.tif
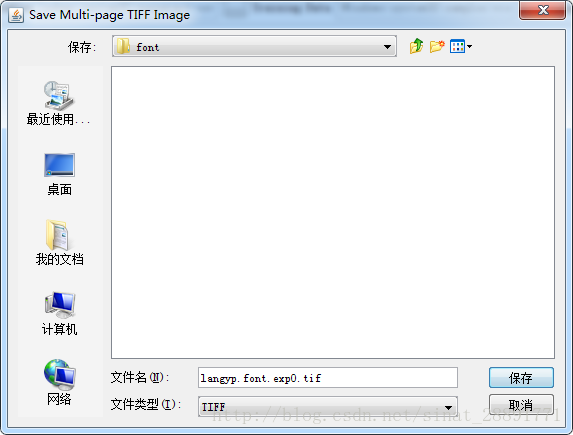
2、生成Box文件
打开cmd,到你langyp.font.exp0.tif文件所在目录,执行:
tesseract langyp.font.exp0.tif langyp.font.exp0 batch.nochop makebox
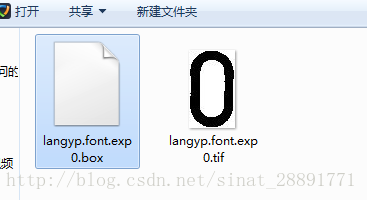
结果生成了langyp.font.exp0.box文件
3、 对样本图片用jTessBoxEditor工具进行矫正
点击jTessBoxEditor工具的Box Editor选项,点击下方的open选项,打开刚刚生成的langyp.font.exp0.tif文件,结果如下:
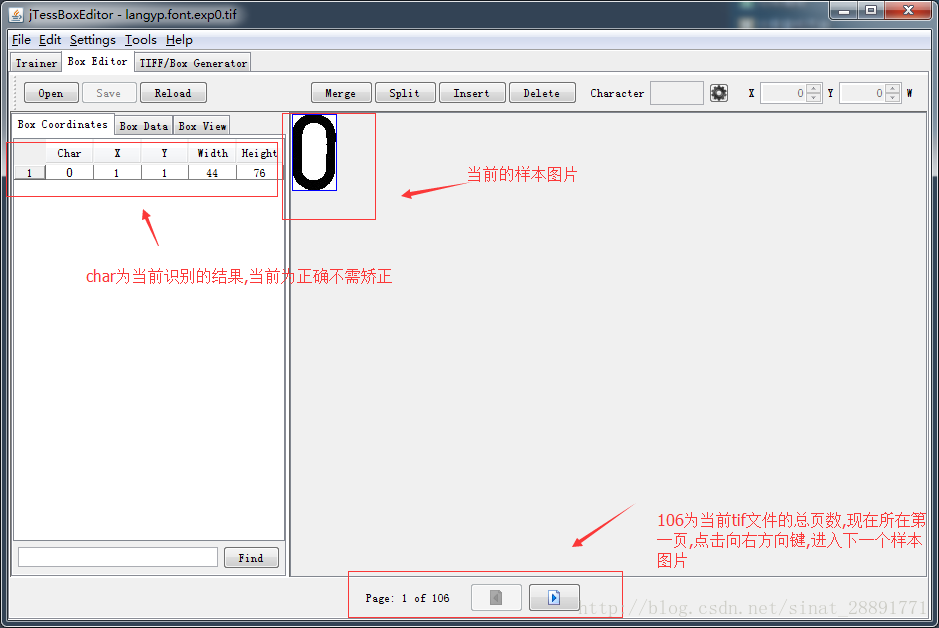
右侧为对应的Box文件数据,如果char的字符和当前的样本图片一致时就进行矫正,修改char里的字符,然后进行save,这样就矫正了,进入下张样本图片时,同样,矫正后点击save,当所有样本图片都矫正了,这一步也就完成了
4、生成font_properties文件(该文件没有后缀名)
在命令行执行:echo font 0 0 0 0 0 >font_properties
结果生成了font_properties文件
内容为字体名font,后面带5个0,分别代表字体的粗体、斜体等属性,这里全部是0
5、生成.tr训练文件
在命令行执行: tesseract langyp.font.exp0.tif langyp.font.exp0 -l eng -psm 7 nobatch box.train
6、生成字符集文件
在命令行执行 : unicharset_extractor langyp.font.exp0.box

结果生成了unicharset文件
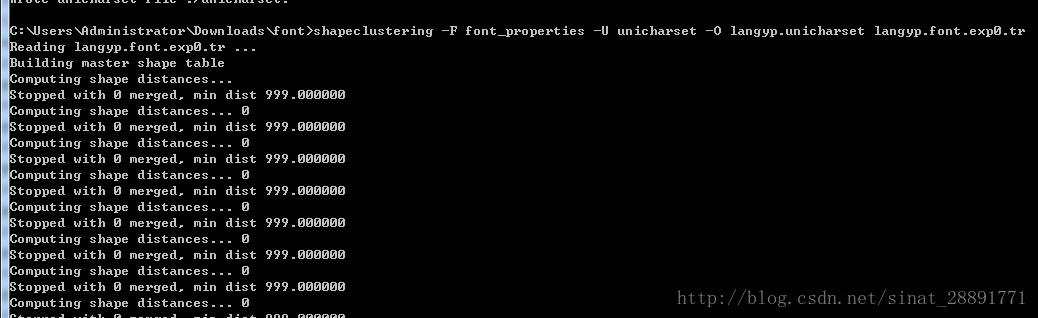
7、生成shape文件
在命令行执行 : shapeclustering -F font_properties -U unicharset -O langyp.unicharset langyp.font.exp0.tr
结果生成了shapetable文件和langyp.unicharset文件
8、生成聚集字符特征文件
在命令行执行: mftraining -F font_properties -U unicharset -O langyp.unicharset langyp.font.exp0.tr

结果生成了pffmtable,inttemp,unicharset文件
9、生成字符正常化特征文件
在命令行执行: cntraining langyp.font.exp0.tr

结果生成了normproto文件
10、把h,i步骤生成的文件用rename命令进行更名
在命令行执行:
**rename normproto fontyp.normproto
rename inttemp fontyp.inttemp
rename pffmtable fontyp.pffmtable
rename unicharset fontyp.unicharset
rename shapetable fontyp.shapetable**

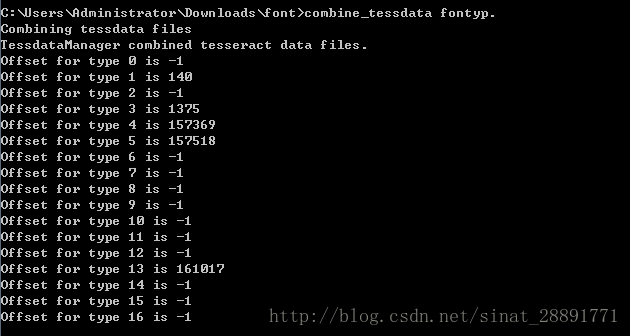
11、合并训练文件
在命令行执行: combine_tessdata fontyp.
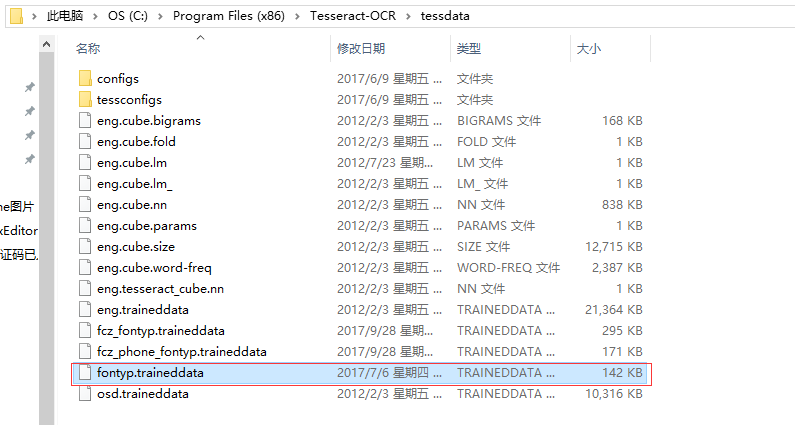
12、将fontyp.traineddata文件拷贝至Tesseract-OCR文件夹里的tessdata语言包文件夹里
windows下面:
linux下面:
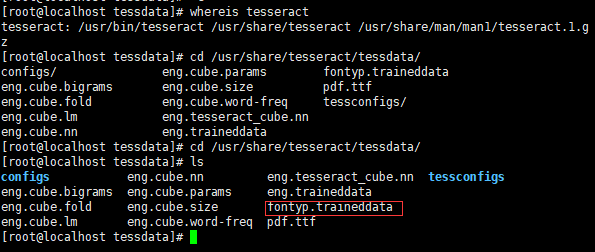
输入命令查找安装文件夹:whereis tesseract
然后拷贝到图上的地址:
二、Python验证码识别代码
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









