






TF-DF 算法
- 基本的概念和定义
- 算法的步骤
- 代码实践
定义
TF-IDF是Term Frequency - Inverse Document Frequency的缩写,即“词频-逆文本频率”。它由两部分组成,TF和IDF。
TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处. 在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)
来自百度百科的定义
简而言之,一般都的文档处理,基本都会用分词,统计词频等常规的方法啊, 但是,单纯词频的高低是无法衡量其重要性的。
算法
TF:

IDF:
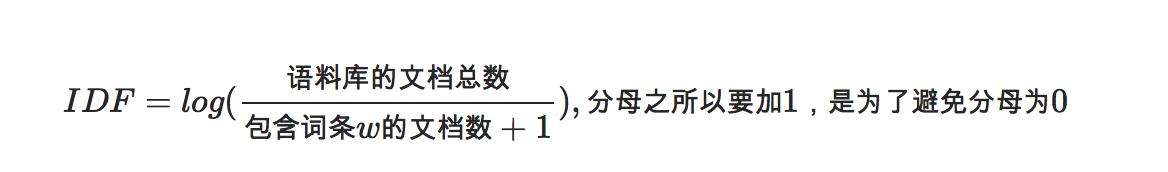
TFIDF:
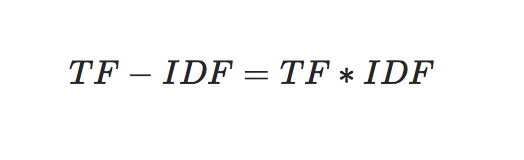
从上,我们可以看出如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。
代码实现
from sklearn.feature_extraction.text import TfidfVectorize
vectorizer.fit(train_data['word_seg'])
Xtrain=vectorizer.fit_transform(train_data['word_seg'])
Xval=vectorizer.fit_transform(validation_data['word_seg'])
参考链接:
[1]:https://baike.baidu.com/item/tf-idf/8816134?fr=aladdin
[2]: https://www.cnblogs.com/pinard/p/6693230.html














 3395
3395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









