









 本文介绍了Oxford-102 Flower花卉数据集,包含数据量、种类等信息。详细说明了DF-GAN配置该数据集的步骤,如下载图像和文本数据集、相关配置文件,以及数据集的配置方法。还提及修改代码以适配花数据集,最后提供了资源下载链接。
本文介绍了Oxford-102 Flower花卉数据集,包含数据量、种类等信息。详细说明了DF-GAN配置该数据集的步骤,如下载图像和文本数据集、相关配置文件,以及数据集的配置方法。还提及修改代码以适配花数据集,最后提供了资源下载链接。
一、Oxford-102 Flower简介
Oxford-102 Flower是牛津工程大学于2008年发布的用于图像分类的花卉数据集,原论文链接:Automated flower classification over a large number of classes
,该数据集选择的花通常在英国本土,详细信息和每个类别的图像数量可以在网站的类别统计页面上找到,如下:

花内类别之间有很大的相似性,比如一朵花与另一朵花的区别有时是颜色,例如蓝色的钟形与向日葵,有时是形状,例如水仙花与蒲公英,有时是花瓣上的图案,例如三色堇与虎耳草等。

1️⃣数据量:8189张图像组成的数据集,这些图像被划分为103个花卉类别,都是英国常见的花卉。数据集分为训练集、验证集和测试集,训练集和验证集各包含10个图像,测试集由剩余的6129张图像组成(每类至少20张)。
2️⃣种类:每个类包含40到250个图像,百香花的图像数量最多,桔梗、墨西哥紫菀、青藤、月兰、坎特伯雷钟和报春花的图像最少,即每类40个,图像被重新缩放,使最小尺寸为500像素。
二、DF-GAN配置Oxford-102 Flower 数据集
2.1、下载数据集
首先进入Oxford-102 Flower的官方网站:https://www.robots.ox.ac.uk/~vgg/data/flowers/102/index.html 然后在Downloads栏目中,点击Dataset images下载原始图像数据集:
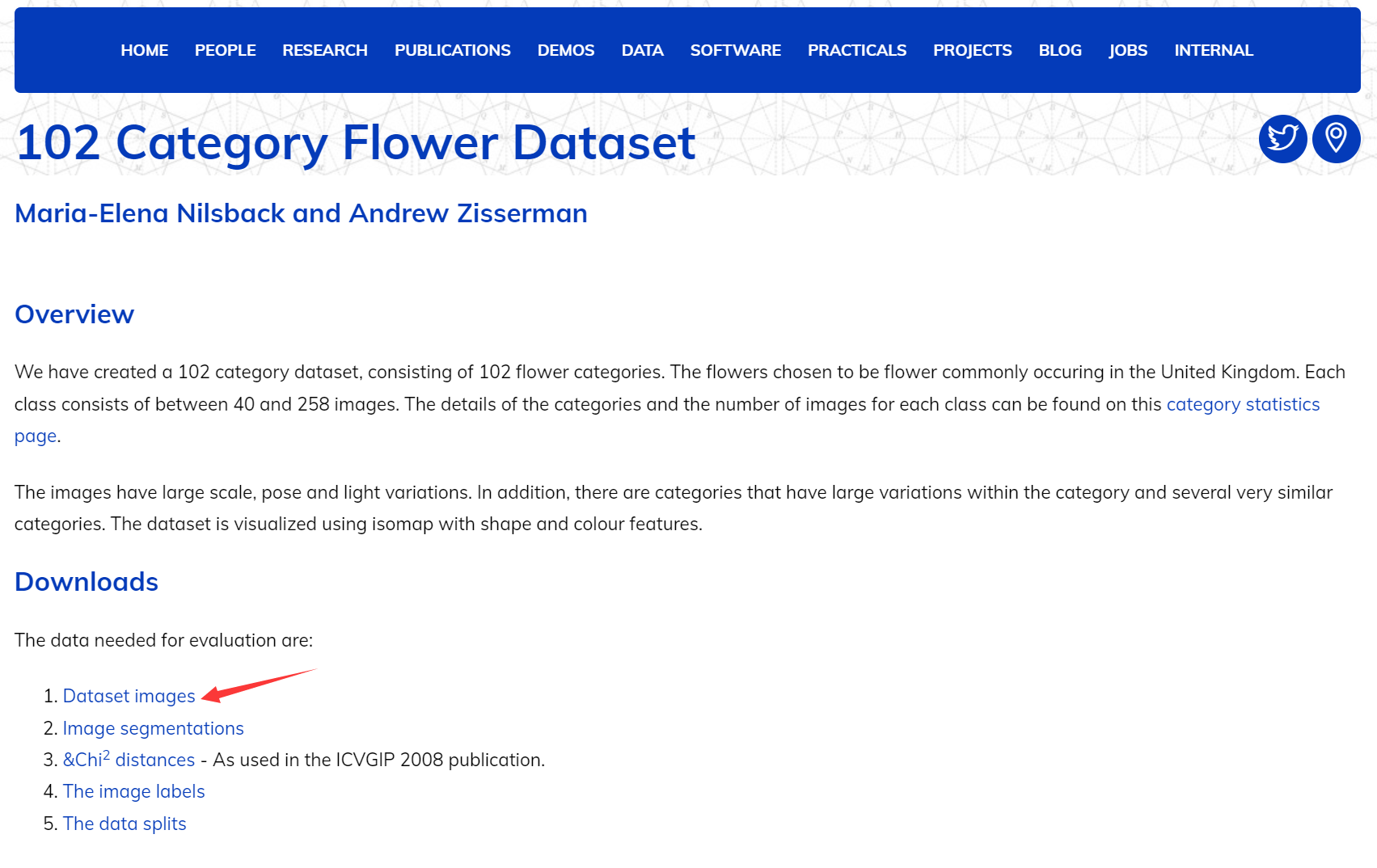
原网站较慢,建议直接使用谷歌云盘进行下载:https://drive.google.com/file/d/1cL0F5Q3AYLfwWY7OrUaV1YmTx4zJXgNG/view
下载好图像数据集后,其次需要下载对应的文本数据集,同样使用谷歌云盘下载:https://drive.google.com/file/d/1G4QRcRZ_s57giew6wgnxemwWRDb-3h5P/view
还需要下载的文件有:
1️⃣:text_encoder250.pth和image_encoder250.pth即预训练好的的文本编码器和图像编码器文件:
2️⃣:flower_val256_FIDK0.npz即FID预训练文件
3️⃣:flower_cat_dic.pkl即字典数据文件
4️⃣:cat_to_name.json即一个用于分类的json文件
5️⃣:captions_DAMSM.pickle即DAMSM的说明文件
6️⃣:captions.pickle即数据集的说明文件
这几项文件部分需要自己训练,部分可在https://github.com/senmaoy/RAT-GAN仓库中找到,为了方便,我已经将其所有打包为一个配置数据包,可供下载:https://download.csdn.net/download/air__Heaven/88842966
2.2、配置数据集
在下载好图像数据集、文本数据集和相关配置文件后,将其解压,并开始配置,首先创建一个主文件夹名为flower,其次参考coco数据集的做法,在主文件夹中创建train、test、text、npz、images、DAMSMencoder文件夹,然后将flower_cat_dic.pkl等文件放到文件夹下:
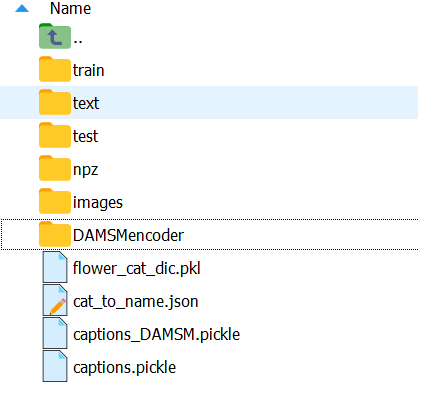
数据集的配置可以参考coco文件夹的配置,其中train文件夹用于放训练集,test文件夹用于放测试集,text用于放刚刚下载好的文本数据集,npz文件夹用于放FID的预训练文件即flower_val256_FIDK0.npz,images文件夹用于放刚下载好的图像数据集,DAMSMencoder用于放刚下载的text_encoder和image_encoder文件。
训练集与测试集的划分可以根据自己设计来划分,以下是可参考的文件夹内部的配置:
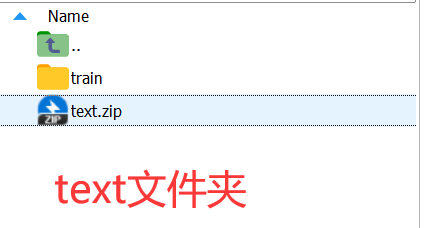

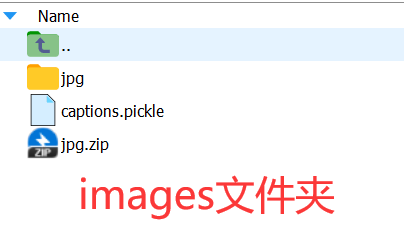
这里提供配置好的花数据集,可直接用于DF-GAN2022版本的训练测试:https://download.csdn.net/download/air__Heaven/88843196
三、修改代码
由于花数据集和CUB-Bird数据集相差较大,不能完全照用原版的dataset.py文件,需要重新设计,这里可以使用RAT-GAN提供的dataset_flower.py:
from nltk.tokenize import RegexpTokenizer
from collections import defaultdict
import torch
import torch.utils.data as data
from torch.autograd import Variable
import torchvision.transforms as transforms
import os
import sys
import time
import numpy as np
import pandas as pd
from io import BytesIO
from PIL import Image
import numpy.random as random
if sys.version_info[0] == 2:
import cPickle as pickle
else:
import pickle
from .utils import truncated_noise
def get_one_batch_data(dataloader, text_encoder, args):
data = next(iter(dataloader))
imgs, captions, sorted_cap_lens, class_ids, sent_emb, words_embs, keys = prepare_data(data, text_encoder)
return imgs, words_embs, sent_emb
def get_fix_data(train_dl, test_dl, text_encoder, args):
fixed_image_train, fixed_word_train, fixed_sent_train = get_one_batch_data(train_dl, text_encoder, args)
fixed_image_test, fixed_word_test, fixed_sent_test = get_one_batch_data(test_dl, text_encoder, args)
fixed_image = torch.cat((fixed_image_train, fixed_image_test), dim=0)
fixed_sent = torch.cat((fixed_sent_train, fixed_sent_test), dim=0)
# 备注:未知原因导致fixed_word_train为([32, 256, 15]) 无法与后续fixed_word_test连接。
# 这里为fixed_word_train补零,扩展成([32, 256, 18])
if fixed_word_train.size(2)!=18:
diff = 18 - fixed_word_train.size(2)
fixed_word_train_cat = torch.zeros([32, 256, diff])
fixed_word_train_cat = fixed_word_train_cat.cuda()
fixed_word_train = torch.cat([fixed_word_train, fixed_word_train_cat], dim=2)
if fixed_word_test.size(2)!=18:
diff = 18 - fixed_word_test.size(2)
fixed_word_test_cat = torch.zeros([32, 256, diff])
fixed_word_test_cat = fixed_word_test_cat.cuda()
fixed_word_test = torch.cat([fixed_word_test, fixed_word_test_cat], dim=2)
fixed_word = torch.cat((fixed_word_train,fixed_word_test),dim=0) # fixed_word_train:torch.Size([32, 256, 15]) fixed_word_test:torch.Size([32, 256, 18])
if args.truncation==True:
noise = truncated_noise(fixed_image.size(0), args.z_dim, args.trunc_rate)
fixed_noise = torch.tensor(noise, dtype=torch.float).to(args.device)
else:
fixed_noise = torch.randn(fixed_image.size(0), args.z_dim).to(args.device)
return fixed_image, fixed_sent, fixed_noise, fixed_word
def prepare_data(data, text_encoder):
imgs, captions, caption_lens, class_ids, keys = data
# sort data by the length in a decreasing order
sorted_cap_lens, sorted_cap_indices = \
torch.sort(caption_lens, 0, True)
captions, sorted_cap_lens, sorted_cap_idxs = sort_sents(captions, caption_lens)
sent_emb, words_embs = encode_tokens(text_encoder, captions, sorted_cap_lens)
sent_emb = rm_sort(sent_emb, sorted_cap_idxs)
words_embs = rm_sort(words_embs, sorted_cap_idxs)
class_ids = class_ids[sorted_cap_indices].numpy()
captions = captions[sorted_cap_indices].squeeze()
captions = Variable(captions).cuda()
sorted_cap_lens = Variable(sorted_cap_lens).cuda()
imgs = Variable(imgs).cuda()
return imgs, captions, sorted_cap_lens, class_ids, sent_emb, words_embs, keys
def sort_sents(captions, caption_lens):
# sort data by the length in a decreasing order
sorted_cap_lens, sorted_cap_indices = torch.sort(caption_lens, 0, True)
captions = captions[sorted_cap_indices].squeeze()
captions = Variable(captions).cuda()
sorted_cap_lens = Variable(sorted_cap_lens).cuda()
return captions, sorted_cap_lens, sorted_cap_indices
def encode_tokens(text_encoder, caption, cap_lens):
# encode text
with torch.no_grad():
if hasattr(text_encoder, 'module'):
hidden = text_encoder.module.init_hidden(caption.size(0))
else:
hidden = text_encoder.init_hidden(caption.size(0))
words_embs, sent_emb = text_encoder(caption, cap_lens, hidden)
words_embs, sent_emb = words_embs.detach(), sent_emb.detach()
return sent_emb, words_embs
def rm_sort(caption, sorted_cap_idxs):
non_sort_cap = torch.empty_like(caption)
for idx, sort in enumerate(sorted_cap_idxs):
non_sort_cap[sort] = caption[idx]
return non_sort_cap
def get_imgs(img_path, bbox=None, transform=None, normalize=None):
img = Image.open(img_path).convert('RGB')
width, height = img.size
if bbox is not None:
r = int(np.maximum(bbox[2], bbox[3]) * 0.75)
center_x = int((2 * bbox[0] + bbox[2]) / 2)
center_y = int((2 * bbox[1] + bbox[3]) / 2)
y1 = np.maximum(0, center_y - r)
y2 = np.minimum(height, center_y + r)
x1 = np.maximum(0, center_x - r)
x2 = np.minimum(width, center_x + r)
img = img.crop([x1, y1, x2, y2])
if transform is not None:
img = transform(img)
if normalize is not None:
img = normalize(img)
return img
################################################################
# Dataset
################################################################
class TextImgDataset(data.Dataset):
def __init__(self, split='train', transform=None, args=None):
self.transform = transform
self.word_num = args.TEXT.WORDS_NUM
self.embeddings_num = args.TEXT.CAPTIONS_PER_IMAGE
self.data_dir = args.data_dir
self.dataset_name = args.dataset_name
self.norm = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
self.split=split
if self.data_dir.find('birds') != -1:
self.bbox = self.load_bbox()
else:
self.bbox = None
split_dir = os.path.join(self.data_dir, split)
self.filenames, self.captions, self.ixtoword, \
self.wordtoix, self.n_words = self.load_text_data(self.data_dir, split)
self.class_id = self.load_class_id(split_dir, len(self.filenames))
self.number_example = len(self.filenames)
def load_bbox(self):
data_dir = self.data_dir
bbox_path = os.path.join(data_dir, 'CUB_200_2011/bounding_boxes.txt')
df_bounding_boxes = pd.read_csv(bbox_path,
delim_whitespace=True,
header=None).astype(int)
#
filepath = os.path.join(data_dir, 'CUB_200_2011/images.txt')
df_filenames = \
pd.read_csv(filepath, delim_whitespace=True, header=None)
filenames = df_filenames[1].tolist()
print('Total filenames: ', len(filenames), filenames[0])
#
filename_bbox = {img_file[:-4]: [] for img_file in filenames}
numImgs = len(filenames)
for i in range(0, numImgs):
# bbox = [x-left, y-top, width, height]
bbox = df_bounding_boxes.iloc[i][1:].tolist()
key = filenames[i][:-4]
filename_bbox[key] = bbox
#
return filename_bbox
def load_captions(self, data_dir, filenames):
all_captions = []
for i in range(len(filenames)):
cap_path = '%s/text/%s.txt' % (data_dir, filenames[i])
with open(cap_path, "r") as f:
captions = f.read().encode('utf-8').decode('utf8').split('\n')
cnt = 0
for cap in captions:
if len(cap) == 0:
continue
cap = cap.replace("\ufffd\ufffd", " ")
# picks out sequences of alphanumeric characters as tokens
# and drops everything else
tokenizer = RegexpTokenizer(r'\w+')
tokens = tokenizer.tokenize(cap.lower())
# print('tokens', tokens)
if len(tokens) == 0:
print('cap', cap)
continue
tokens_new = []
for t in tokens:
t = t.encode('ascii', 'ignore').decode('ascii')
if len(t) > 0:
tokens_new.append(t)
all_captions.append(tokens_new)
cnt += 1
if cnt == self.embeddings_num:
break
if cnt < self.embeddings_num:
print('ERROR: the captions for %s less than %d'
% (filenames[i], cnt))
return all_captions
def build_dictionary(self, train_captions, test_captions):
word_counts = defaultdict(float)
captions = train_captions + test_captions
for sent in captions:
for word in sent:
word_counts[word] += 1
vocab = [w for w in word_counts if word_counts[w] >= 0]
ixtoword = {}
ixtoword[0] = '<end>'
wordtoix = {}
wordtoix['<end>'] = 0
ix = 1
for w in vocab:
wordtoix[w] = ix
ixtoword[ix] = w
ix += 1
train_captions_new = []
for t in train_captions:
rev = []
for w in t:
if w in wordtoix:
rev.append(wordtoix[w])
# rev.append(0) # do not need '<end>' token
train_captions_new.append(rev)
test_captions_new = []
for t in test_captions:
rev = []
for w in t:
if w in wordtoix:
rev.append(wordtoix[w])
# rev.append(0) # do not need '<end>' token
test_captions_new.append(rev)
return [train_captions_new, test_captions_new,
ixtoword, wordtoix, len(ixtoword)]
def load_text_data(self, data_dir, split):
filepath = os.path.join(data_dir, 'captions_DAMSM.pickle')
train_names = self.load_filenames(data_dir, 'train')
test_names = self.load_filenames(data_dir, 'test')
if not os.path.isfile(filepath):
train_captions = self.load_captions(data_dir, train_names)
test_captions = self.load_captions(data_dir, test_names)
train_captions, test_captions, ixtoword, wordtoix, n_words = \
self.build_dictionary(train_captions, test_captions)
with open(filepath, 'wb') as f:
pickle.dump([train_captions, test_captions,
ixtoword, wordtoix], f, protocol=2)
print('Save to: ', filepath)
else:
with open(filepath, 'rb') as f:
x = pickle.load(f)
train_captions, test_captions = x[0], x[1]
ixtoword, wordtoix = x[2], x[3]
del x
n_words = len(ixtoword)
print('Load from: ', filepath)
if split == 'train':
# a list of list: each list contains
# the indices of words in a sentence
captions = train_captions
filenames = train_names
else: # split=='test'
captions = test_captions
filenames = test_names
return filenames, captions, ixtoword, wordtoix, n_words
def load_class_id(self, data_dir, total_num):
if os.path.isfile(data_dir + '/class_info.pickle'):
with open(data_dir + '/class_info.pickle', 'rb') as f:
class_id = pickle.load(f, encoding="bytes")
else:
class_id = np.arange(total_num)
return class_id
def load_filenames(self, data_dir, split):
filepath = '%s/%s/filenames.pickle' % (data_dir, split)
if os.path.isfile(filepath):
with open(filepath, 'rb') as f:
filenames = pickle.load(f)
print('Load filenames from: %s (%d)' % (filepath, len(filenames)))
else:
filenames = []
return filenames
def get_caption(self, sent_ix):
# a list of indices for a sentence
sent_caption = np.asarray(self.captions[sent_ix]).astype('int64')
if (sent_caption == 0).sum() > 0:
print('ERROR: do not need END (0) token', sent_caption)
num_words = len(sent_caption)
# pad with 0s (i.e., '<end>')
x = np.zeros((self.word_num, 1), dtype='int64')
x_len = num_words
if num_words <= self.word_num:
x[:num_words, 0] = sent_caption
else:
ix = list(np.arange(num_words)) # 1, 2, 3,..., maxNum
np.random.shuffle(ix)
ix = ix[:self.word_num]
ix = np.sort(ix)
x[:, 0] = sent_caption[ix]
x_len = self.word_num
return x, x_len
def __getitem__(self, index):
#
key = self.filenames[index]
cls_id = self.class_id[index]
#
if self.bbox is not None:
bbox = self.bbox[key]
data_dir = '%s/CUB_200_2011' % self.data_dir
else:
bbox = None
data_dir = self.data_dir
#
if self.dataset_name.find('coco') != -1:
if self.split=='train':
img_name = '%s/images/train2014/%s.jpg' % (data_dir, key)
else:
img_name = '%s/images/val2014/%s.jpg' % (data_dir, key)
elif self.dataset_name.find('flower') != -1:
if self.split=='train':
img_name = '%s/oxford-102-flowers/images/%s.jpg' % (data_dir, key)
else:
img_name = '%s/oxford-102-flowers/images/%s.jpg' % (data_dir, key)
elif self.dataset_name.find('CelebA') != -1:
if self.split=='train':
img_name = '%s/image/CelebA-HQ-img/%s.jpg' % (data_dir, key)
else:
img_name = '%s/image/CelebA-HQ-img/%s.jpg' % (data_dir, key)
else:
img_name = '%s/images/%s.jpg' % (data_dir, key)
imgs = get_imgs(img_name, bbox, self.transform, normalize=self.norm)
# random select a sentence
sent_ix = random.randint(0, self.embeddings_num)
new_sent_ix = index * self.embeddings_num + sent_ix
caps, cap_len = self.get_caption(new_sent_ix)
return imgs, caps, cap_len, cls_id, key
def __len__(self):
return len(self.filenames)
接下来,需要检查module.py、prepare.py,train.py等文件中:
将from lib.datasets import prepare_data, encode_tokens改为from lib.datasets_flower import prepare_data, encode_tokens
将from lib.datasets import TextImgDataset as Dataset改为from lib.datasets_flower import TextDataset as Dataset
将from lib.datasets import get_fix_data改为from lib.datasets_flower import get_fix_data
这一步需要较大的耐心和细心,可能会出现些许bug,可以在评论区留言。
如果不希望破坏原有的数据集配置,可以传一个args进行,通过判断是否为花来加一个条件判断,如:

以下是成功运行后,训练一百多轮后生成的效果,还是不错的;:

四、资源下载
💖 个人简介:人工智能领域研究生,目前主攻文本生成图像(text to image)方向
📝 个人主页:中杯可乐多加冰
🔥 限时免费订阅:文本生成图像T2I专栏
🎉 支持我:点赞👍+收藏⭐️+留言📝
另外,我们已经建立了研学交流群,如果你也是大模型、生成式AI、T2I方面的爱好者或研究者可以私信我加入,如果你对本文的配置仍然不理解或者需要相关数据资源,可以私信我。
Oxford-102 Flower配置数据包:https://download.csdn.net/download/air__Heaven/88842966
配置好的Oxford-102 Flower数据集 花卉数据集(不包含模型代码):https://download.csdn.net/download/air__Heaven/88843196



















 2747
2747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











