






最近在入门深度学习,打算练一个花卉识别的项目,本文将阐述该项目用的数据集的介绍、下载、处理以及可能遇到的问题。
数据集介绍
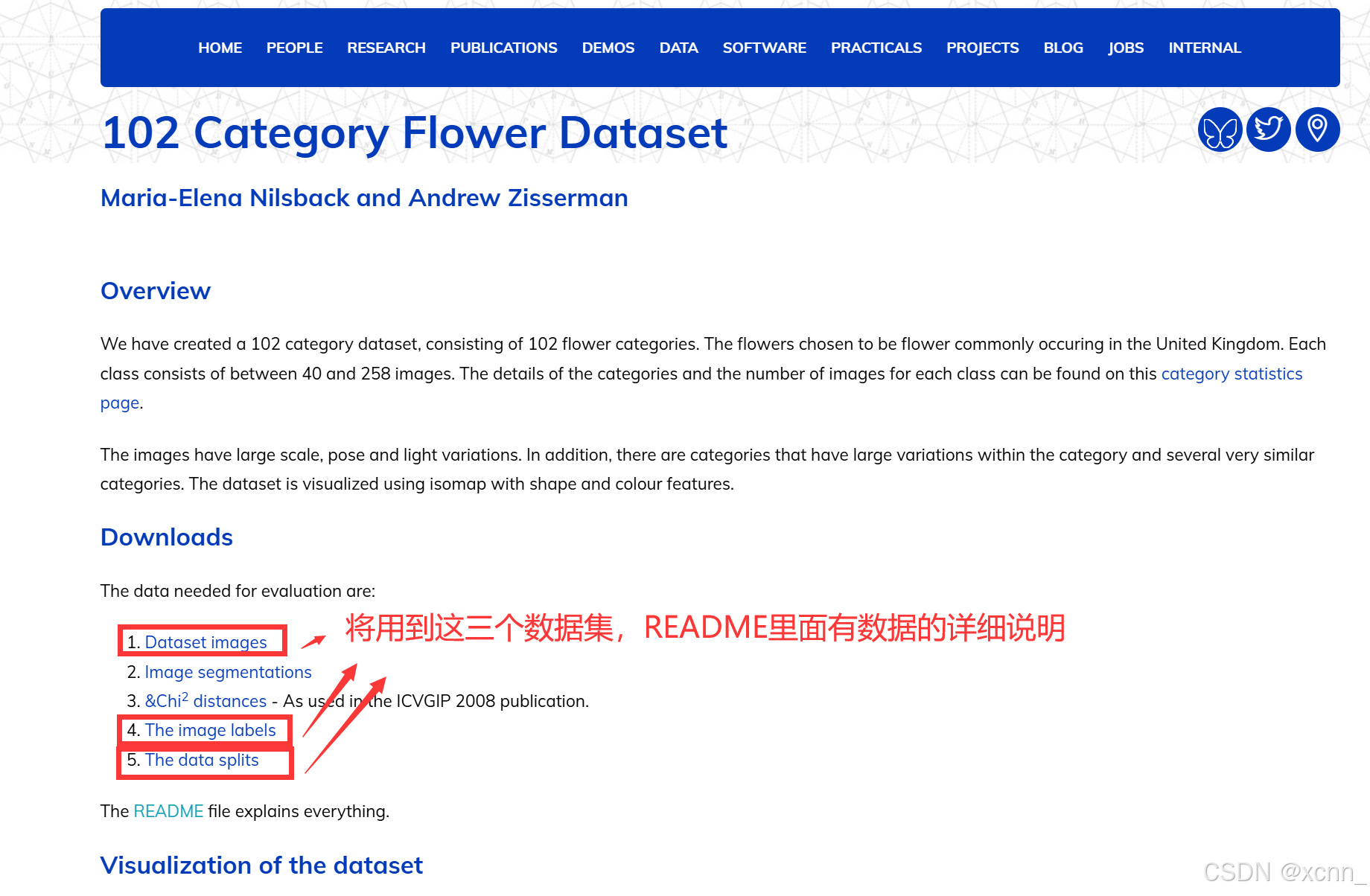
该数据集为牛津工程大学2008年发布的用于图像分类的花卉数据集,其中包括102种花的类别,所选的花卉通常在英国常见。每个类别包含40到258张图片。
下载地址:Flower 102 Dataset
网页如下:
数据处理
第一个 Dataset Images 解压出来是一个**.jpg**文件,里面是各种花卉的图,我们需要将它们分类。第二个文件和第三个文件下载出来分别为 imagelabels.mat 和 setid.mat。我把它们 都放在工作路径下。数据处理代码如下:
import scipy.io
import numpy as np
import os
from PIL import Image
# 加载标签和数据集划分信息
imagelabels_path = './imagelabels.mat'
labels = scipy.io.loadmat(imagelabels_path)['labels'][0] - 1
setid_path = './setid.mat'
setid = scipy.io.loadmat(setid_path)
validation = np.array(setid['valid'][0]) - 1
np.random.shuffle(validation)
train = np.array(setid['trnid'][0]) - 1
np.random.shuffle(train)
test = np.array(setid['tstid'][0]) - 1
np.random.shuffle(test)
# 获取图片路径列表并排序
flower_dir = [os.path.join("./jpg", img) for img in sorted(os.listdir("./jpg"))]
# 处理数据的函数
def process_data(data_ids, des_folder):
for tid in data_ids:
img = Image.open(flower_dir[tid]).resize((256, 256), Image.ANTIALIAS)
label = labels[tid]
class_path = os.path.join(des_folder, f"c{label}")
os.makedirs(class_path, exist_ok=True)
despath = os.path.join(class_path, os.path.basename(flower_dir[tid]))
img.save(despath)
# 处理训练集、验证集和测试集
process_data(train, "./train")
process_data(validation, "./val")
process_data(test, "./test")
print("Processed Successfully")
代跑跑完后就有 train, valid, test 三个文件夹,分别表示训练集、验证集和测试集。
由于train里面文件只有1,020,valid里面文件有6149,后来训练的时候我把这两个数据集掉了个包
也可以直接用 kaggle 里提供的数据集。kaggle 花卉数据集下载链接:kaggle_flower_dataset 。解压出来是一个archive文件夹,包含以下数据:

可能遇到的问题
“AttributeError: module ‘PIL.Image’ has no attribute ‘ANTIALIAS’”
这是因为在pillow的10.0.0版本中,ANTIALIAS方法被删除了。
解决方案:给 Pillow降级,卸载重装更低的版本。
pip uninstall -y Pillow
pip install Pillow==9.5.0
参考文章:Flower102 数据集

















 2208
2208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









