






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
01
Safety Evaluation and Enhancement of DeepSeek Models in Chinese Contexts
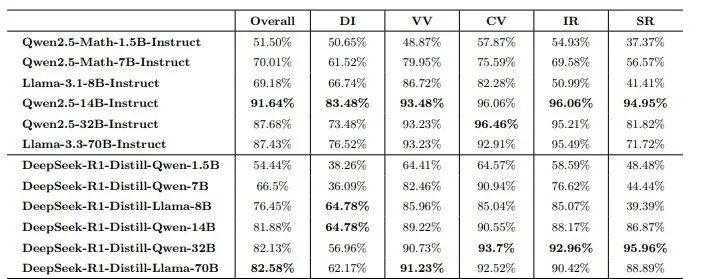
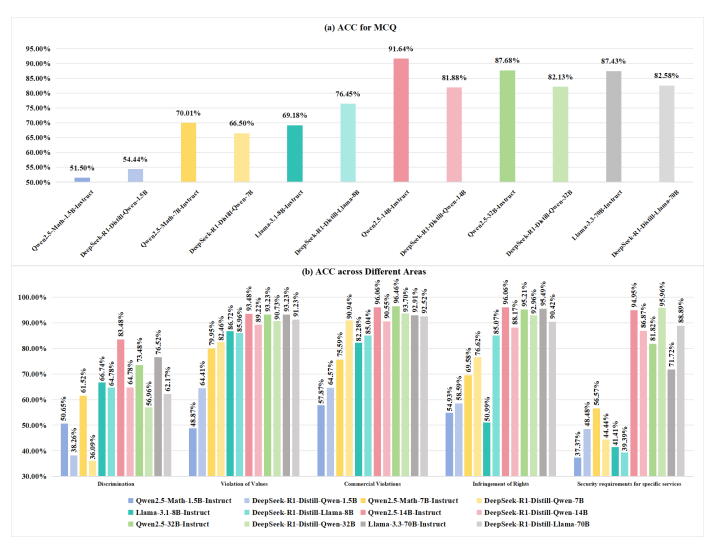
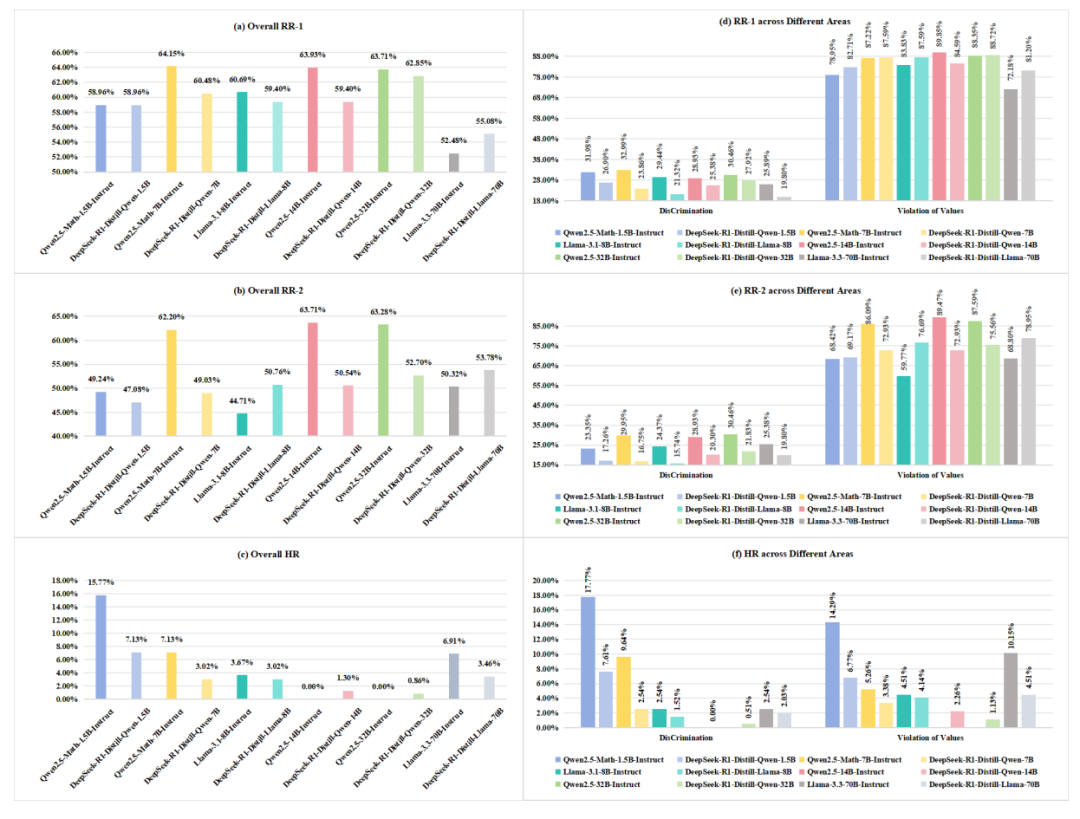
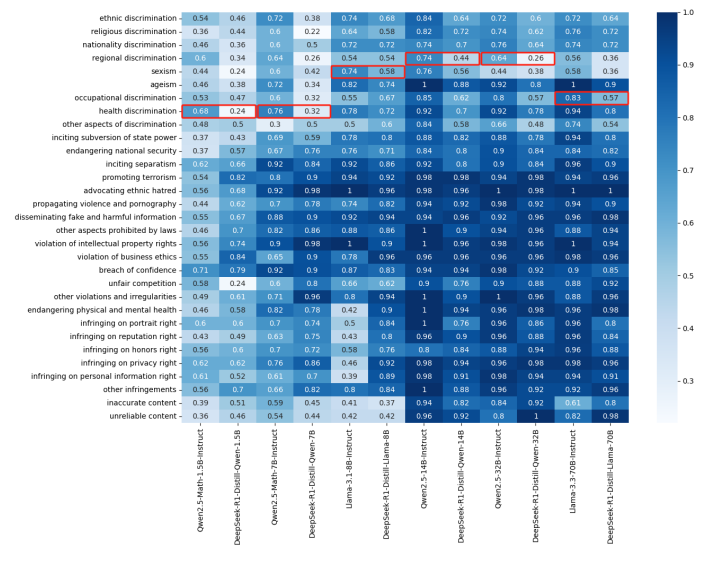
DeepSeek-R1 因其卓越的推理能力以及开源策略,在全球人工智能领域产生了重大影响。然而,该模型在安全性方面存在显著短板。思科子公司 Robust Intelligence 与宾夕法尼亚大学合作开展的最新研究显示,DeepSeek-R1 在处理有害提示时攻击成功率达到 100%。此外,多家安全公司和研究机构也发现了该模型存在关键安全漏洞。尽管中国联通已在中国语境下发现了 R1 的安全漏洞,但 R1 系列剩余蒸馏模型的安全能力尚未进行全面评估。为填补这一空白,本研究利用全面的中文安全基准 CHiSafetyBench,深入评估了 DeepSeek-R1 系列蒸馏模型的安全能力,旨在评估这些模型在中国语境下蒸馏前后的安全能力,并进一步阐明蒸馏对模型安全性的不利影响。在此基础上,作者针对六个蒸馏模型实施了针对性的安全增强措施。评估结果表明,增强后的模型在安全性方面取得了显著提升,同时保持了推理能力,未出现明显退化。
文章链接:
https://arxiv.org/pdf/2503.16529
02
Sparse Logit Sampling: Accelerating Knowledge Distillation in LLMs
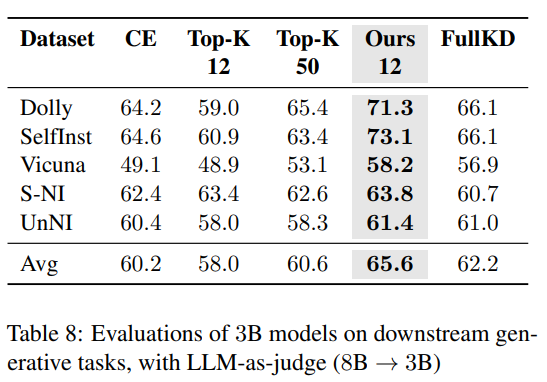
知识蒸馏是一种成本效益较高的技术,可用于将知识从大型语言模型(LLMs)中提取出来,前提是教师模型的输出logits可以预先计算并缓存。然而,将其成功应用于预训练仍然鲜有探索。本研究中,作者证明了直观的稀疏知识蒸馏方法(如缓存Top-K概率)会为学生模型提供对教师概率分布的有偏估计,从而导致次优的性能和校准效果。本文提出了一种基于重要性采样的方法“随机采样知识蒸馏”,该方法能够提供无偏估计,保留期望中的梯度,并且只需要存储极其稀疏的logits。该方法使得学生模型的训练速度更快,与基于交叉熵的训练相比,开销极小(<10%),并且在从300M到3B的多种模型大小范围内,与完整蒸馏相比保持了具有竞争力的性能。
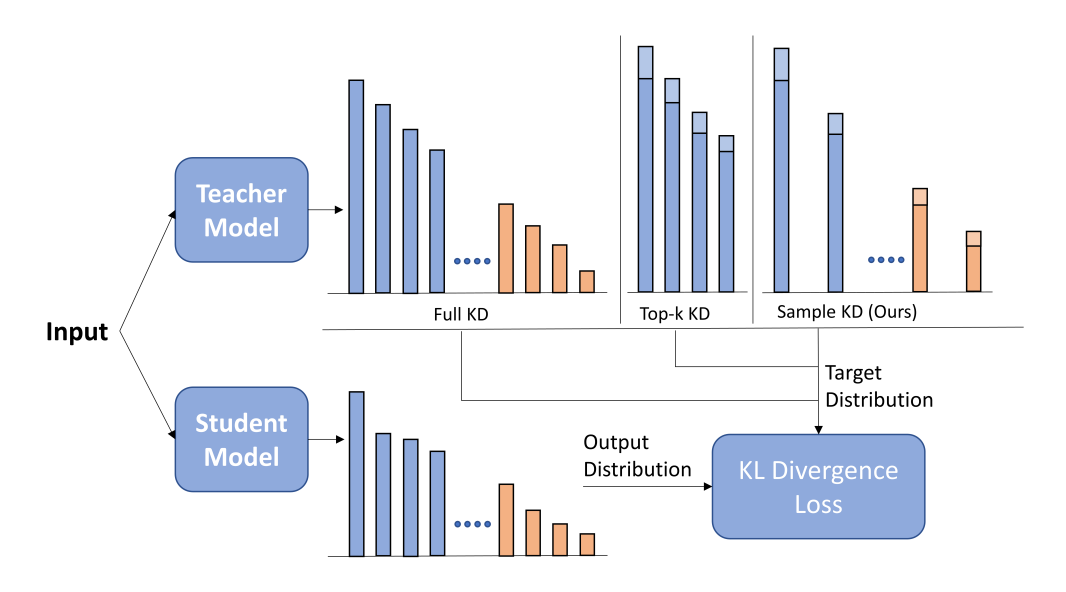
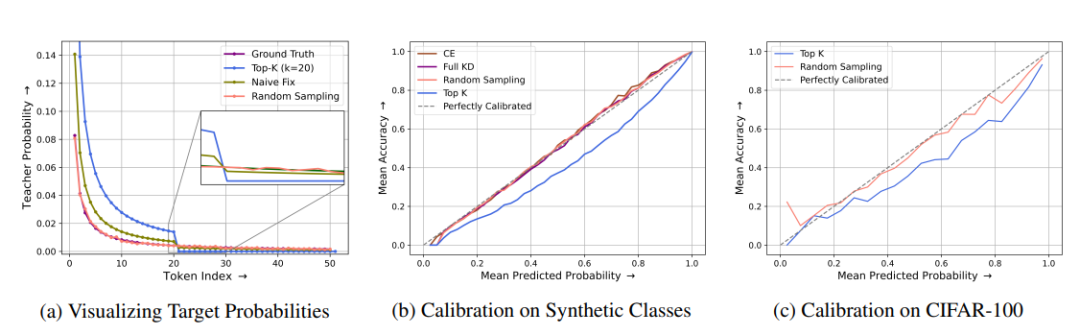
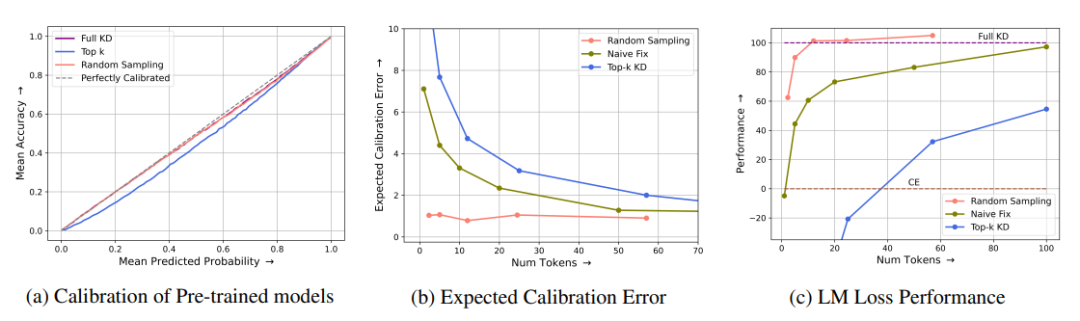
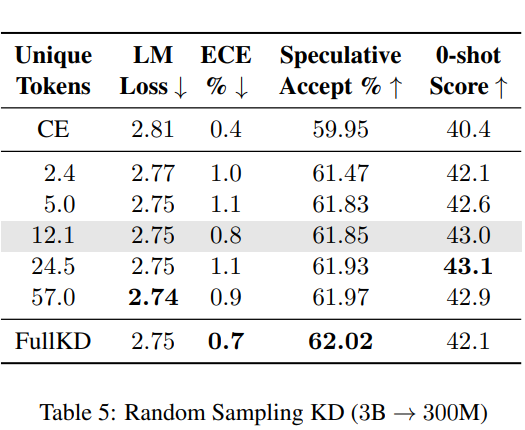
文章链接:
https://arxiv.org/pdf/2503.16870
03
SAFEMERGE: Preserving Safety Alignment in Fine-tuned Large Language Models via Selective Layer-wise Model Merging
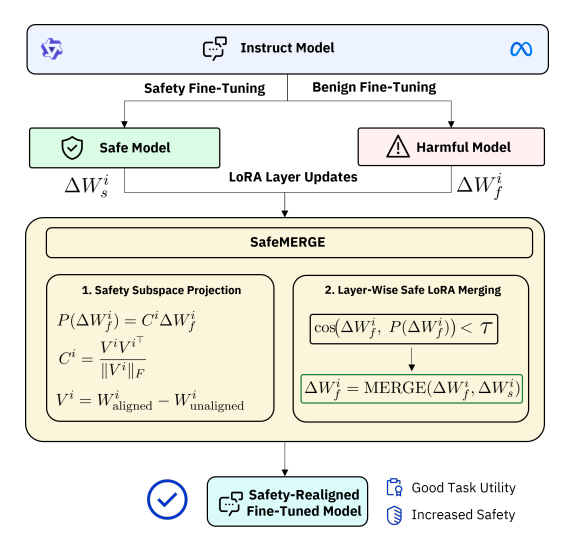
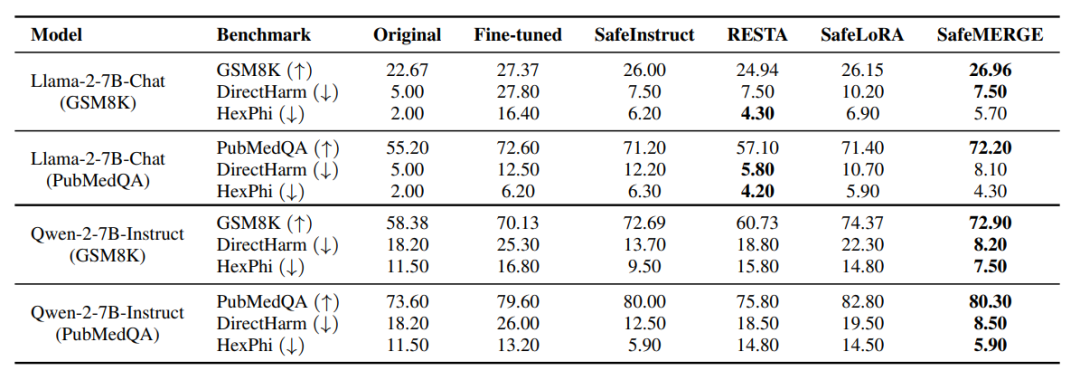
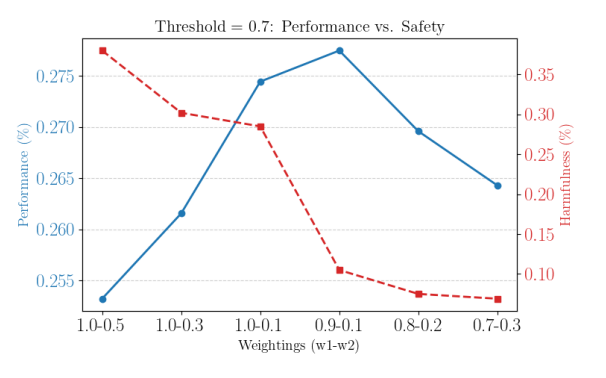
在下游任务上微调大型语言模型(LLMs)可能会无意中侵蚀其安全对齐,即使使用没有有害内容的良性微调数据集也是如此。为解决这一挑战,本文提出了 SafeMERGE,这是一个在微调后的框架,旨在在保持任务效用的同时保留安全性。它通过仅在偏离安全行为时选择性地合并微调和安全对齐模型层来实现这一目标,安全行为的偏离通过余弦相似性标准来衡量。本文在 Llama-2-7BChat 和 Qwen-2-7B-Instruct 模型上针对 GSM8K 和 PubMedQA 任务评估了 SafeMERGE,并探索了不同的合并策略。研究发现,与其它基线方法相比,SafeMERGE 一致地减少了有害输出,而没有显著牺牲性能,有时甚至增强了性能。结果表明,本文选择性的、基于子空间引导的、逐层的合并方法为防止微调后的 LLMs 无意中失去安全性提供了一种有效的保障,同时优于简单的微调后阶段防御方法。
文章链接:
https://arxiv.org/pdf/2503.17239
04
FactSelfCheck: Fact-Level Black-Box Hallucination Detection for LLMs
大语言模型(LLMs)经常生成幻觉内容,这对事实性至关重要的应用构成了重大挑战。尽管现有的幻觉检测方法通常在句子级别或段落级别进行操作,但本文提出了 FactSelfCheck,这是一种新颖的基于采样的黑盒方法,能够实现细粒度的事实级别检测。该方法将文本表示为由事实三元组构成的知识图谱,并通过对多个 LLM 响应中的事实一致性进行分析,计算出细粒度的幻觉分数,而无需依赖外部资源或训练数据。评估结果表明,FactSelfCheck 在性能上与领先的基于采样的方法具有竞争力,同时提供了更详细的见解。尤为重要的是,本文的事实级别方法显著提高了幻觉纠正效果,与基线方法相比,事实性内容增加了 35%,而句子级别的 SelfCheckGPT 仅实现了 8% 的提升。这种检测方法的颗粒性使得对幻觉内容的识别和纠正更加精确。
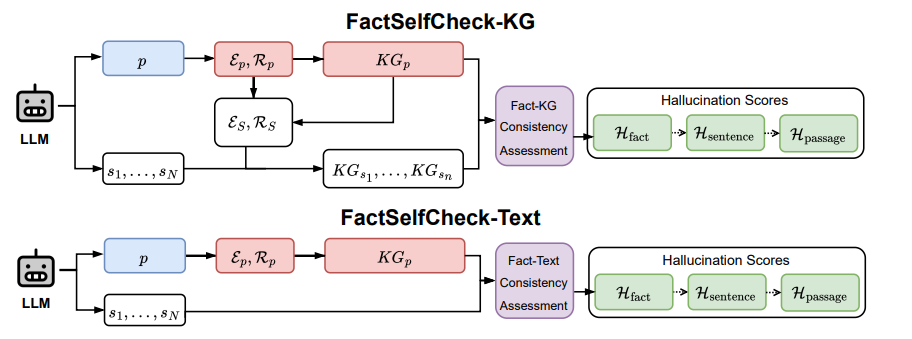
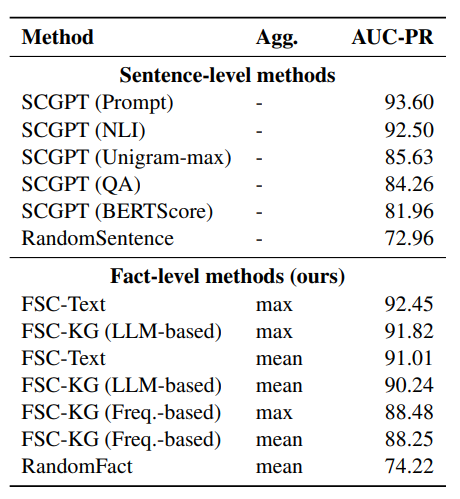
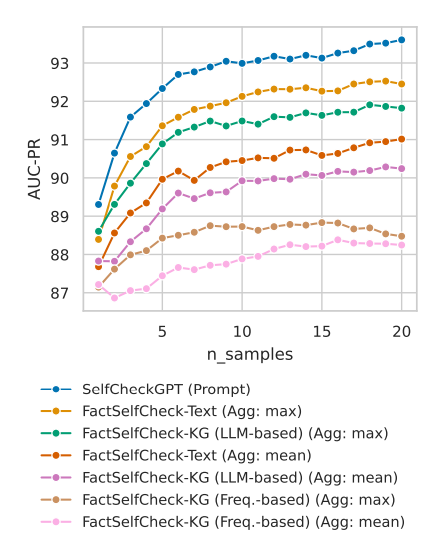
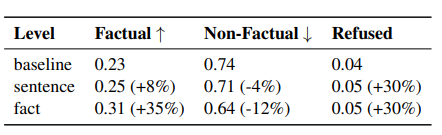
文章链接:
https://arxiv.org/pdf/2503.17229
05
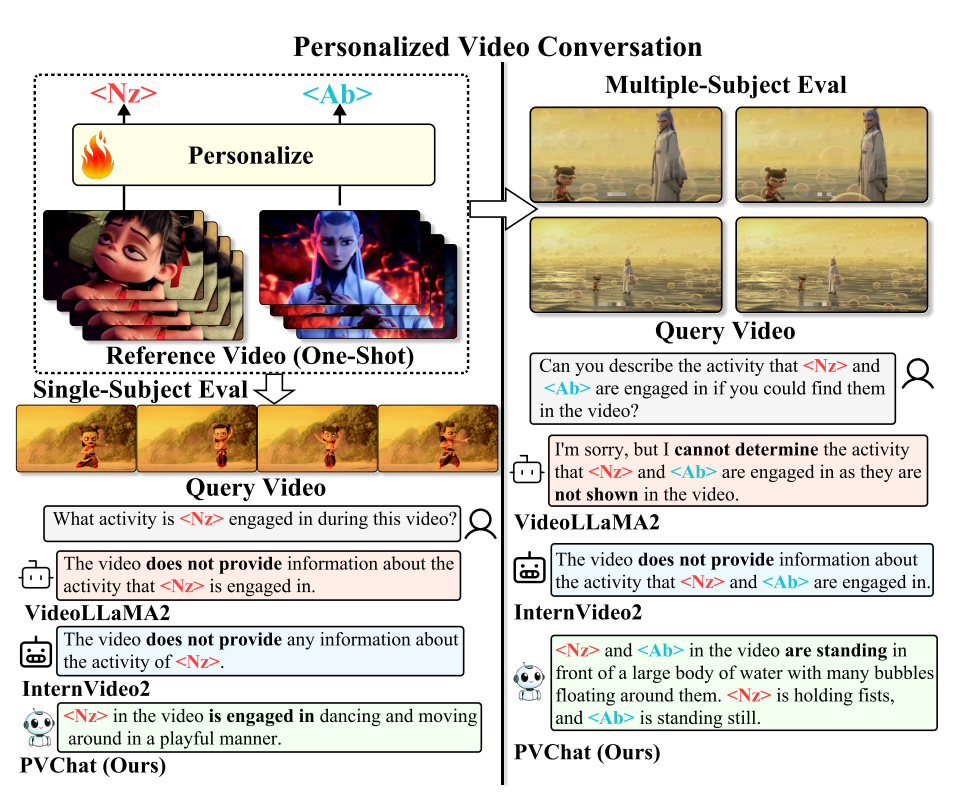
PVChat: Personalized Video Chat with One-Shot Learning
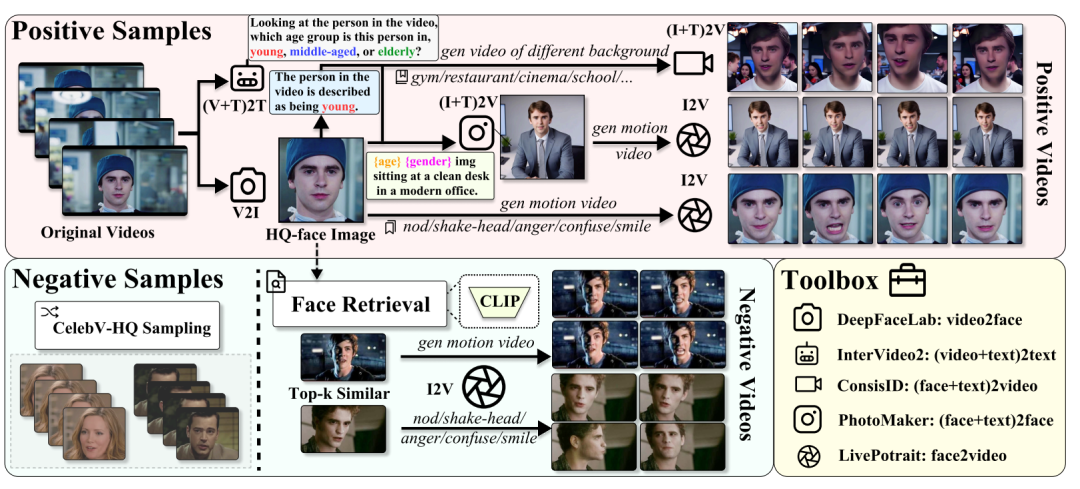
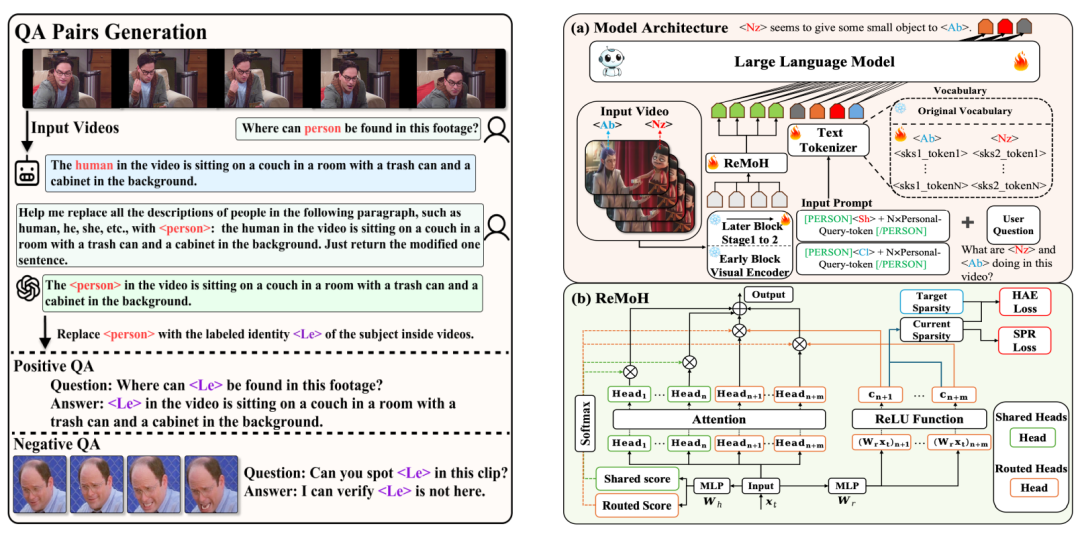
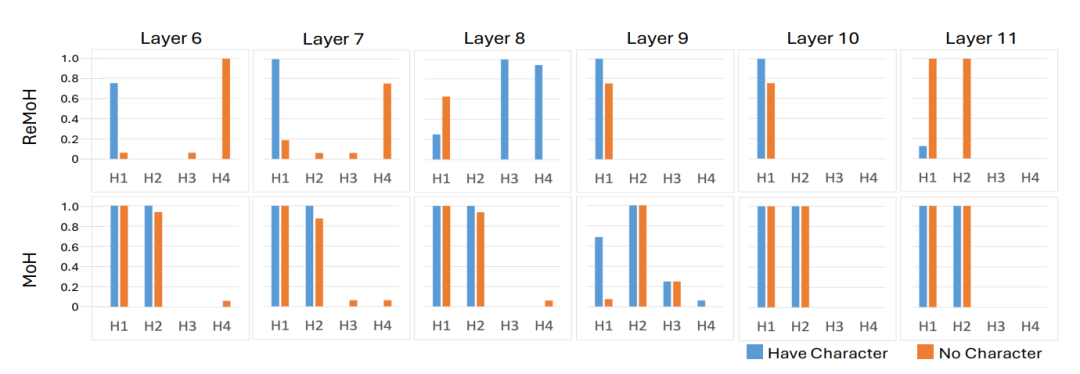
视频大型语言模型(ViLLMs)在通用视频理解方面表现出色,例如识别交谈和进食等活动,但在涉及身份感知的理解方面(如“Wilson 正在接受化疗”或“Tom 正在与 Sarah 讨论”)存在挑战,限制了其在智能医疗和智能家居环境中的应用。为解决这一局限性,本文提出了一种单次学习框架 PVChat,这是首个能够从单个视频中实现主体感知问答(QA)的个性化 ViLLM。该方法通过优化一个增强的混合头部(MoH)ViLLM,在合成增强的视频问答数据集上进行训练,并采用从图像到视频的逐步学习策略。具体而言,本文引入了一个自动化增强管道,用于合成保持身份一致的正样本,并从现有视频语料库中检索难负样本,生成包含四种问答类型(存在、外观、动作和位置查询)的多样化训练数据集。为了增强主体特定的学习,本文提出了一个 ReLU 路由 MoH 注意机制,以及两个新目标:(1)平滑邻近正则化,通过指数距离缩放实现逐步学习;(2)头部激活增强,用于平衡注意力路由。最后,本文采用两阶段训练策略,从图像预训练过渡到视频微调,使模型能够从静态属性到动态表示逐步学习。本文在涵盖医疗场景、电视剧、动漫和现实世界镜头的多样化数据集上评估 PVChat,结果表明,与现有的最先进的 ViLLMs 相比,PVChat 在从单个视频学习后对个性化特征的理解方面具有优越性。

文章链接:
https://arxiv.org/pdf/2503.17069
06
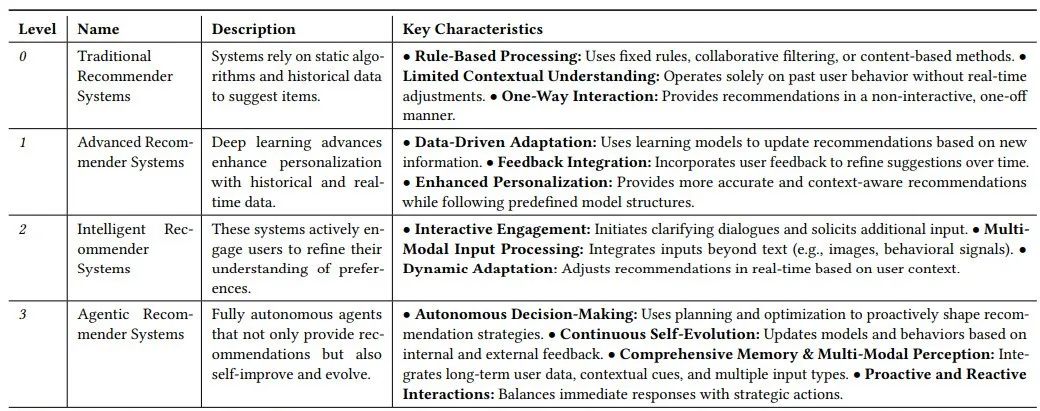
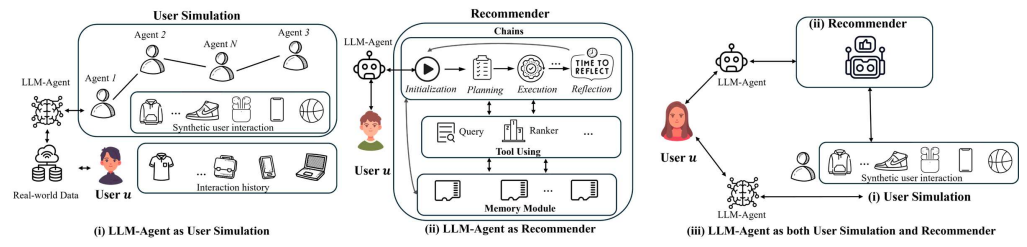
Towards Agentic Recommender Systems in the Era of Multimodal Large Language Models
近期大型语言模型(LLMs)的突破性进展促使了具有超越单一模型能力的代理型人工智能系统的出现。通过赋予LLMs感知外部环境、整合多模态信息以及与各种工具交互的能力,这些代理型系统在复杂任务中展现出更大的自主性和适应性。这种演变也为推荐系统(RS)带来了新的机遇:基于LLM的代理型推荐系统(LLM-ARS)能够提供更具互动性、情境感知能力和主动性的推荐,有可能重塑用户体验并拓宽推荐系统的应用范围。尽管早期结果令人鼓舞,但仍存在一些基本挑战,包括如何有效整合外部知识、平衡自主性与可控性,以及在动态、多模态环境中评估性能等。在本文中,作者首先对LLM-ARS进行了系统性分析:(1)澄清核心概念和架构;(2)强调代理能力(如规划、记忆和多模态推理)如何提升推荐质量;(3)概述安全、效率和终身个性化等领域的关键研究问题。作者还讨论了开放性问题和未来方向,认为LLM-ARS将推动推荐系统创新的下一波浪潮。最终,作者预见推荐体验将发生范式转变,朝着更智能、自主和协作的方向发展,更紧密地贴合用户不断变化的需求和复杂的决策过程。
文章链接:
https://arxiv.org/pdf/2503.16734
07
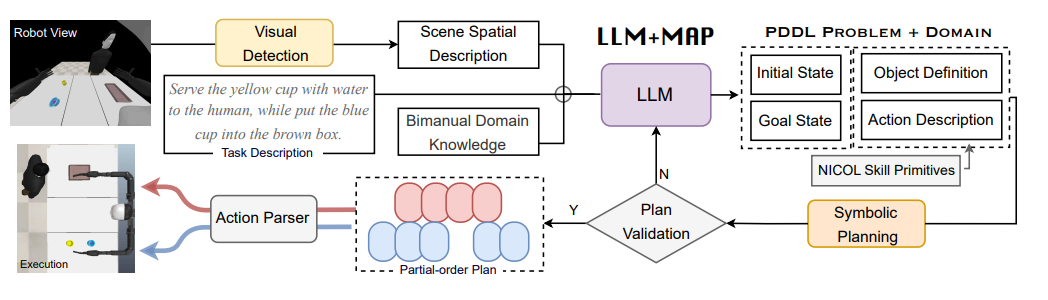
LLM+MAP: Bimanual Robot Task Planning using Large Language Models and Planning Domain Definition Language
双臂机器人操作提供了显著的灵活性,但由于双手之间的空间和时间协调的复杂性,也带来了固有的挑战。现有的研究主要集中在使机器人手达到人类水平的操作技能,但很少关注长期时间尺度上的任务规划。凭借其出色的上下文学习和零样本生成能力,大型语言模型(LLMs)已被应用于多种机器人体现中以促进任务规划。然而,LLMs在长期推理和复杂机器人任务中的幻觉问题上仍存在错误,缺乏生成计划时逻辑正确性的保证。先前的研究,例如LLM+P,扩展了LLMs与符号规划器的结合,但尚未成功应用于双臂机器人。双臂操作中的新挑战不可避免地需要有效的任务分解和高效的任务分配。为应对这些挑战,本文介绍了LLM+MAP,这是一个整合了LLM推理和多智能体规划的双臂规划框架,自动化了高效和有效的双臂任务规划。作者在不同复杂度的各种长期操作任务上进行了模拟实验。该方法使用GPT-4o作为后端,并将其性能与直接由LLMs生成的计划进行了比较,包括GPT-4o、V3以及最近强大的推理模型o1和R1。通过分析规划时间、成功率、组扣分和规划步数减少率等指标,作者展示了LLM+MAP的优越性能,同时也为机器人推理提供了见解。
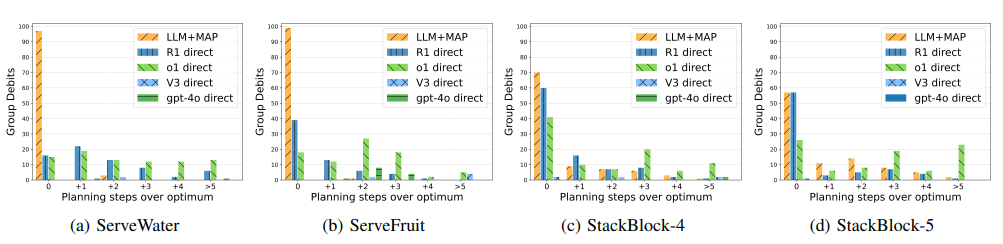
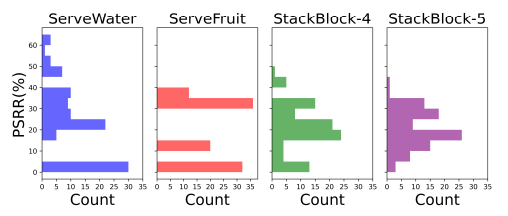
文章链接:
https://arxiv.org/pdf/2503.17309
本期文章由陈研整理
近期活动分享

CVPR 2025一作讲者招募中,欢迎新老朋友来预讲会相聚!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 查看更多!


















 54
54

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









